本文主要是介绍【python爬虫 系列】12.实战一 爬取北京地区所有的房租信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实战一
爬取北京地区所有的房租信息
1.要求
包括以下信息:
标题,租金,出租方式,户型,建筑面积,
朝向,楼层,装修等信息
存储于MYSQL中。导出excel或者csv
Sql导出csv方法:
select * from house into outfile "D:/out.csv
2.分析信息:
网址:https://zu.fang.com/
直接请求时请求不到页面
需要具备各种参数
启动Fiddler编写测试
需要三个参数
头部
来源
Cookies
3.设计架构:
数据库db.py
爬虫main.py
测试test.py
我们发起的request请求太多,
使用长连接,避免占用太多资源
4.编写db.py(创建表)
4.1这在之前,我们先调节一下我们的数据库配置文件,改为:
[client]
#设置mysq|客户端默认字符集
# default character- set=utf8[mysqld]
#设置3306端口
port = 3306
#设置mysql的安装目录
basedir=D:\mysql-8.0.19-winx64
#允许最大连接数
max_connections=1000
#服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
#创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
#导出文件需要
secure_file_priv="D:/"
4.2链接数据库:
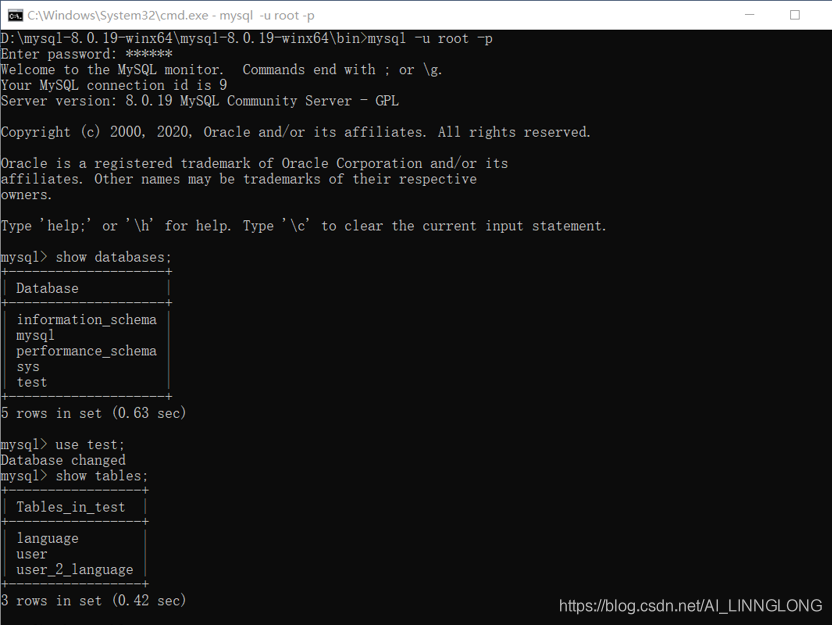
4.3写入db.py:
#存放数据库代码#导入包
from sqlalchemy import create_engine
from sqlalchemy import Column,Integer,String
from sqlalchemy.orm import sessionmaker,scoped_session
from sqlalchemy.ext.declarative import declarative_base
#创建连接
BASE=declarative_base() #创建基类
# 连接数据库
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=UTF8MB4",# (里面的 root 要填写你的密码),注意:mysql+pymysql 之间不要加空格# "mysql + pymysql://root:root@localhost/test",max_overflow = 500, # 超过连接池大小之后,外最多可以创建的链接pool_size = 100, # 连接池大小echo = True, # 调试信息展示
)
#建表
class House(BASE):__tablename__="house" #表名 id=Column(Integer,primary_key=True,autoincrement=True) #id 主键自增block=Column(String(125))rent=Column(String(125))data=Column(String(225))#建立数据库
BASE.metadata.create_all(engine) #创建Session=sessionmaker(engine)
sess=scoped_session(Session) #为了线程安全
4.4运行后在cmd查看运行结果:
5.编写main.py
用session取代requests
解析库使用xpath
并发库使用concurrent
5.1Headers的构建(在开发者页面里找到参数):
headers={'cookie': 'global_cookie=txaxdx88dpgv9a49oflr6w4j61yk6sncq90; integratecover=1; city=www; g_sourcepage=zf_fy%5Elb_pc; __utmc=147393320; ASP.NET_SessionId=pyefmyz0epjjnlcjw0yllr4r; keyWord_recenthousebj=%5b%7b%22name%22%3a%22%e6%b5%b7%e6%b7%80%22%2c%22detailName%22%3a%22%22%2c%22url%22%3a%22%2fhouse-a00%2f%22%2c%22sort%22%3a1%7d%5d; Captcha=565778754464366F3136557A644C556259477767704D334E4F37783431497978657165764544395474336737653179312F554358594E52367A6B566A5232373549695265782B76703633733D; unique_cookie=U_tc13v239pj2xmb5t6dasouizw1nk79um3rd*4; __utma=147393320.411936847.1583116386.1583116386.1583119062.2; __utmz=147393320.1583119062.2.2.utmcsr=zu.fang.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt_t0=1; __utmt_t1=1; __utmt_t2=1; __utmb=147393320.3.10.1583119062',
'referer': 'https://zu.fang.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'}
4.2分析url(对爬取的多个页面url进行分析寻找规律)
部分url:
https://zu.fang.com/house -a01/
https://zu.fang.com/house- a00/
https://zu.fang.com/house- a010/
https://zu.fang.com/house-a016/
分析结果:urls=['https://zu.fang.com/house-a0{}/'.format(i) for i in range(1,17)]
4.3初步编写main.py
首先写单线程模式,优化是后期的事情过早优化会让代码复杂,可读性低
import requests
from lxml import etree
import re
from urllib import parse
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from db import sess,House #从我们的db.py引入 线程安全和表headers={'cookie': 'global_cookie=txaxdx88dpgv9a49oflr6w4j61yk6sncq90; integratecover=1; city=www; g_sourcepage=zf_fy%5Elb_pc; __utmc=147393320; ASP.NET_SessionId=pyefmyz0epjjnlcjw0yllr4r; keyWord_recenthousebj=%5b%7b%22name%22%3a%22%e6%b5%b7%e6%b7%80%22%2c%22detailName%22%3a%22%22%2c%22url%22%3a%22%2fhouse-a00%2f%22%2c%22sort%22%3a1%7d%5d; Captcha=565778754464366F3136557A644C556259477767704D334E4F37783431497978657165764544395474336737653179312F554358594E52367A6B566A5232373549695265782B76703633733D; unique_cookie=U_tc13v239pj2xmb5t6dasouizw1nk79um3rd*4; __utma=147393320.411936847.1583116386.1583116386.1583119062.2; __utmz=147393320.1583119062.2.2.utmcsr=zu.fang.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt_t0=1; __utmt_t1=1; __utmt_t2=1; __utmb=147393320.3.10.1583119062',
'referer': 'https://zu.fang.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'}session = requests.session() #建立会话利用session长链接
session.headers = headersdef main():urls=['https://zu.fang.com/house-a0{}/'.format(i) for i in range(1,17)]for url in urls:get_index(url)if __name__ == '__main__':main()session.close()
4.4爬取列表页,获取详细data
获取一个地区后
爬去每个地区的房子总页数
方便下一步迭代
def get_index(url):html=session.get(url)if html.status_code==200:get_data(html)else:print("请求页面{}出错".format(url))
分析每个地区下不同列表页数:



可以发现页数这是相当没有规律的,但是有一个好的地方就是每个地区下都会标注一共有多少页,这样也就方便了我们,只要我们把这个页面总数get到就可以了,我们可以利用xpath和正则表达式实现这一点。
对海淀区的不同页url进行分析
url:
1页:https://zu.fang.com/house-a00/i31/
2页:https://zu.fang.com/house-a00/i32/
3页:https://zu.fang.com/house-a00/i33/
完善如下:
import requests
from lxml import etree
import re
from urllib import parse
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from db import sess,House #从我们的db.py引入 线程安全和表headers={'cookie': 'global_cookie=txaxdx88dpgv9a49oflr6w4j61yk6sncq90; integratecover=1; city=www; g_sourcepage=zf_fy%5Elb_pc; __utmc=147393320; ASP.NET_SessionId=pyefmyz0epjjnlcjw0yllr4r; keyWord_recenthousebj=%5b%7b%22name%22%3a%22%e6%b5%b7%e6%b7%80%22%2c%22detailName%22%3a%22%22%2c%22url%22%3a%22%2fhouse-a00%2f%22%2c%22sort%22%3a1%7d%5d; Captcha=565778754464366F3136557A644C556259477767704D334E4F37783431497978657165764544395474336737653179312F554358594E52367A6B566A5232373549695265782B76703633733D; unique_cookie=U_tc13v239pj2xmb5t6dasouizw1nk79um3rd*4; __utma=147393320.411936847.1583116386.1583116386.1583119062.2; __utmz=147393320.1583119062.2.2.utmcsr=zu.fang.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt_t0=1; __utmt_t1=1; __utmt_t2=1; __utmb=147393320.3.10.1583119062',
'referer': 'https://zu.fang.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'}session = requests.session() #建立会话利用session长链接
session.headers = headers
#进入首页
def get_index(url):html=session.get(url)if html.status_code==200:get_data(html)else:print("请求页面{}出错".format(url))
#获取数字
def get_number(text):number=re.compile('\d+')return number.findall(text)[0]
#获取页面的page总数
def get_pages(html):soup=etree.HTML(html.text)pages=soup.xpath('//div[@class="fanye"]/span[@class="txt"]/text()')number=get_number(pages[0])if number:return int(number)return None#获取页面
def get_data(html):pages=get_pages(html)if not pages:pages=1urls=['https://zu.fang.com/house-a00/i3%d/'%i for i in range(1,pages+1)]for url in urls:get_data_next(url)def main():urls=['https://zu.fang.com/house-a0{}/'.format(i) for i in range(1,17)]for url in urls:get_index(url)if __name__ == '__main__':main()session.close()
4.5获取页面的预览信息
预览页面中有有用信息可以事先爬取

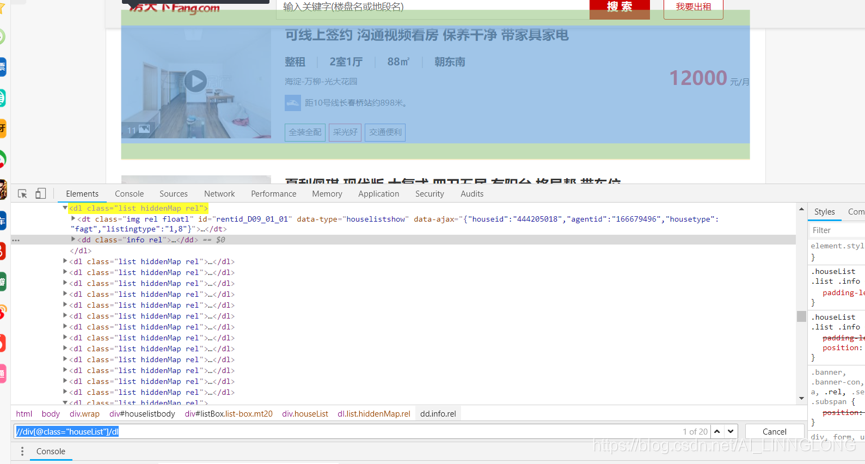
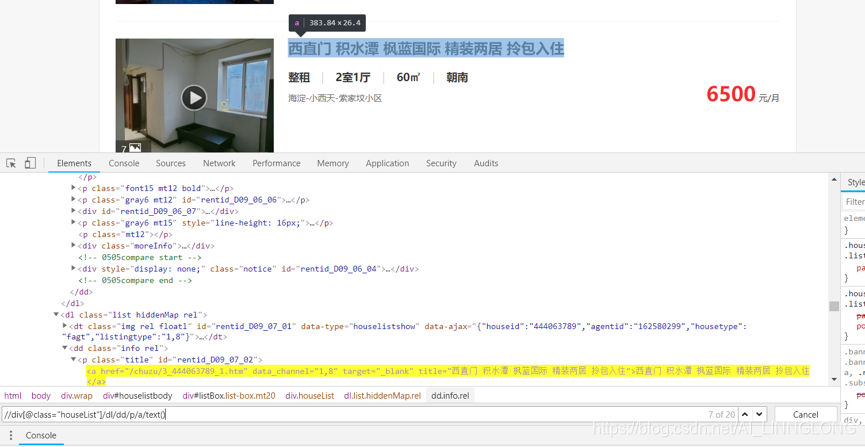
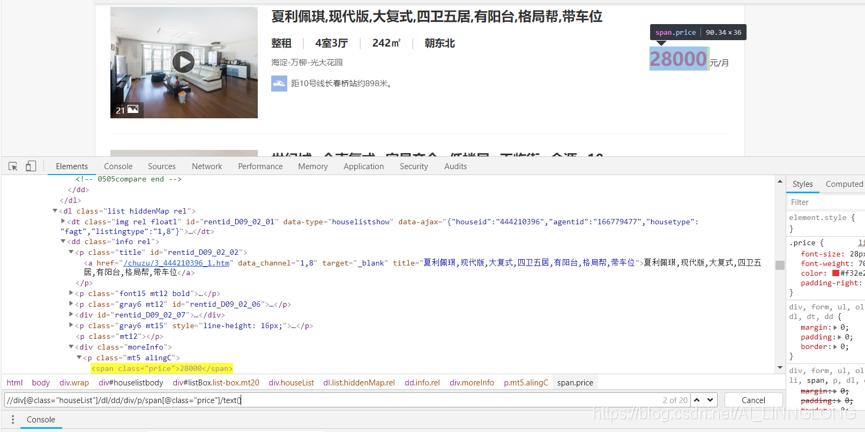
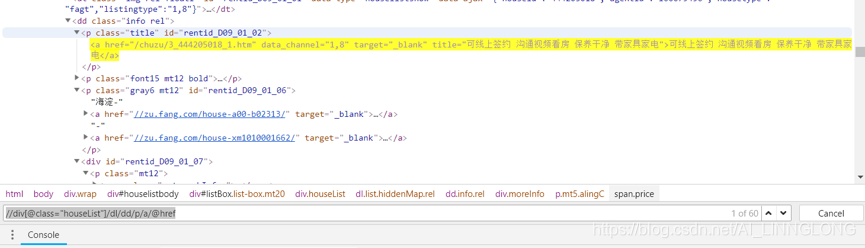
注意这里的hrf并不是全的,需要我们利用urljoin方法补全主站
import requests
from lxml import etree
import re
from urllib import parse
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from db import sess,House #从我们的db.py引入 线程安全和表headers={'cookie': 'global_cookie=txaxdx88dpgv9a49oflr6w4j61yk6sncq90; integratecover=1; city=www; g_sourcepage=zf_fy%5Elb_pc; __utmc=147393320; ASP.NET_SessionId=pyefmyz0epjjnlcjw0yllr4r; keyWord_recenthousebj=%5b%7b%22name%22%3a%22%e6%b5%b7%e6%b7%80%22%2c%22detailName%22%3a%22%22%2c%22url%22%3a%22%2fhouse-a00%2f%22%2c%22sort%22%3a1%7d%5d; Captcha=565778754464366F3136557A644C556259477767704D334E4F37783431497978657165764544395474336737653179312F554358594E52367A6B566A5232373549695265782B76703633733D; unique_cookie=U_tc13v239pj2xmb5t6dasouizw1nk79um3rd*4; __utma=147393320.411936847.1583116386.1583116386.1583119062.2; __utmz=147393320.1583119062.2.2.utmcsr=zu.fang.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt_t0=1; __utmt_t1=1; __utmt_t2=1; __utmb=147393320.3.10.1583119062',
'referer': 'https://zu.fang.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'}session = requests.session() #建立会话利用session长链接
session.headers = headers
#进入首页
def get_index(url):html=session.get(url)if html.status_code==200:get_data(html)else:print("请求页面{}出错".format(url))
#获取数字
def get_number(text):number=re.compile('\d+')return number.findall(text)[0]
#获取页面的page总数
def get_pages(html):soup=etree.HTML(html.text)pages=soup.xpath('//div[@class="fanye"]/span[@class="txt"]/text()')number=get_number(pages[0])if number:return int(number)return None#获取页面
def get_data(html):pages=get_pages(html)if not pages:pages=1urls=['https://zu.fang.com/house-a00/i3%d/'%i for i in range(1,pages+1)]for url in urls:get_data_next(url)def get_data_next(url):html=session.get(url)soup=etree.HTML(html.text)dls=soup.xpath('//div[@class="houseList"]/dl')for dl in dls:try:title=dl.xpath('dd/p/a/text()')[0]rent=dl.xpath('dd/div/p/span[@class="price"]/text()')[0]href=parse.urljoin("https://zu.fang.com",dl.xpath('dd/p/a/@href')[0])#print(title,rent,href)except IndexError as e:print("dl error")def main():urls=['https://zu.fang.com/house-a0{}/'.format(i) for i in range(1,17)]for url in urls:get_index(url)if __name__ == '__main__':main()session.close()
4.6获取详情页信息
获取line:
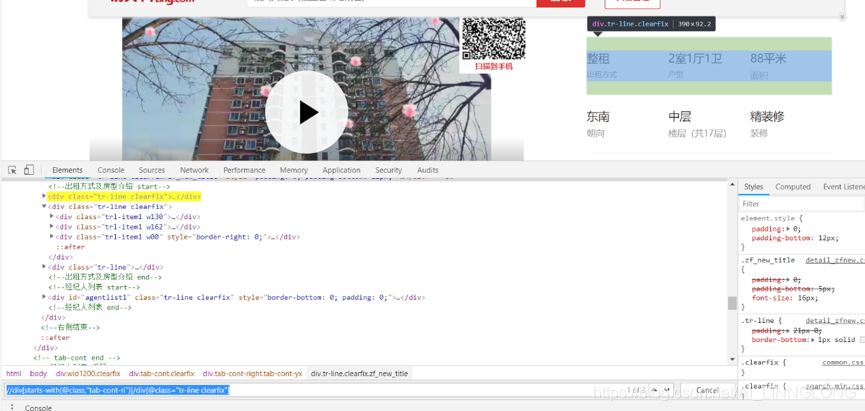
获取line下的标签:
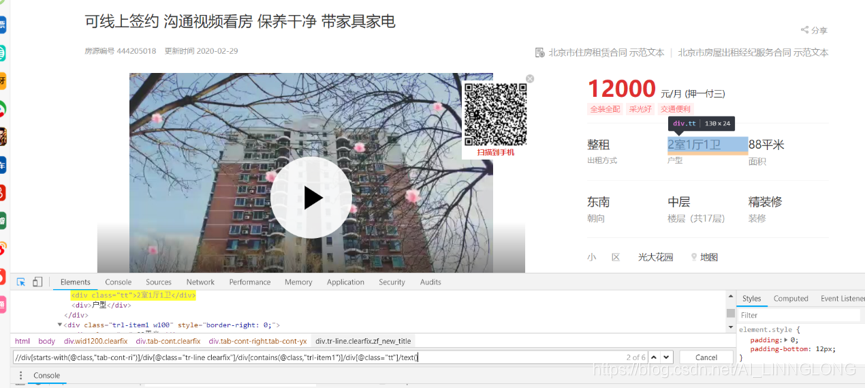
4.7完善单线程的main.py
数据入库防止插入数据失败,编写回滚
import requests
from lxml import etree
import re
from urllib import parse
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from db import sess,House #从我们的db.py引入 线程安全和表headers={'cookie': 'global_cookie=txaxdx88dpgv9a49oflr6w4j61yk6sncq90; integratecover=1; city=www; g_sourcepage=zf_fy%5Elb_pc; __utmc=147393320; ASP.NET_SessionId=pyefmyz0epjjnlcjw0yllr4r; keyWord_recenthousebj=%5b%7b%22name%22%3a%22%e6%b5%b7%e6%b7%80%22%2c%22detailName%22%3a%22%22%2c%22url%22%3a%22%2fhouse-a00%2f%22%2c%22sort%22%3a1%7d%5d; Captcha=565778754464366F3136557A644C556259477767704D334E4F37783431497978657165764544395474336737653179312F554358594E52367A6B566A5232373549695265782B76703633733D; unique_cookie=U_tc13v239pj2xmb5t6dasouizw1nk79um3rd*4; __utma=147393320.411936847.1583116386.1583116386.1583119062.2; __utmz=147393320.1583119062.2.2.utmcsr=zu.fang.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt_t0=1; __utmt_t1=1; __utmt_t2=1; __utmb=147393320.3.10.1583119062',
'referer': 'https://zu.fang.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'}session = requests.session() #建立会话利用session长链接
session.headers = headers
#进入首页
def get_index(url):html=session.get(url)if html.status_code==200:get_data(html)else:print("请求页面{}出错".format(url))
#获取数字
def get_number(text):number=re.compile('\d+')return number.findall(text)[0]
#获取页面的page总数
def get_pages(html):soup=etree.HTML(html.text)pages=soup.xpath('//div[@class="fanye"]/span[@class="txt"]/text()')number=get_number(pages[0])if number:return int(number)return None#获取页面
def get_data(html):pages=get_pages(html)if not pages:pages=1urls=['https://zu.fang.com/house-a00/i3%d/'%i for i in range(1,pages+1)]for url in urls:get_data_next(url)def get_data_next(url):html=session.get(url)soup=etree.HTML(html.text)dls=soup.xpath('//div[@class="houseList"]/dl')for dl in dls:try:title=dl.xpath('dd/p/a/text()')[0]rent=dl.xpath('dd/div/p/span[@class="price"]/text()')[0]href=parse.urljoin("https://zu.fang.com",dl.xpath('dd/p/a/@href')[0])#print(title,rent,href)get_house_data(href,title,rent,href)except IndexError as e:print("dl error")#获取单个房间的信息
def get_house_data(url,*args):html=session.get(url)soup=etree.HTML(html.text)lines=soup.xpath('//div[starts-with(@class,"tab-cont-ri")]/div[@class="tr-line clearfix"]')[:2]results=""for line in lines:datas=line.xpath('div[contains(@class,"trl-item1")]/div[@class="tt"]/text()')results+="|".join(datas)#print(results)s=sess()try:print(s)house=House(block=args[0],rent=args[1],data=results)s.add(house)s.commit()print("commit")except Exception as e:print("rollback",e)s.rollback()def main():urls=['https://zu.fang.com/house-a0{}/'.format(i) for i in range(1,17)]for url in urls:get_index(url)if __name__ == '__main__':main()session.close()
4.8优化
1)优化
完成基础架构:先优化两部分
地区部分多进程
每个地区 下多线程
(后续可以在多线程下异步协程或者Celery分布式)
import requests
from lxml import etree
import re
from urllib import parse
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
from db import sess,House #从我们的db.py引入 线程安全和表headers={'cookie': 'global_cookie=txaxdx88dpgv9a49oflr6w4j61yk6sncq90; integratecover=1; city=www; g_sourcepage=zf_fy%5Elb_pc; __utmc=147393320; ASP.NET_SessionId=pyefmyz0epjjnlcjw0yllr4r; keyWord_recenthousebj=%5b%7b%22name%22%3a%22%e6%b5%b7%e6%b7%80%22%2c%22detailName%22%3a%22%22%2c%22url%22%3a%22%2fhouse-a00%2f%22%2c%22sort%22%3a1%7d%5d; Captcha=565778754464366F3136557A644C556259477767704D334E4F37783431497978657165764544395474336737653179312F554358594E52367A6B566A5232373549695265782B76703633733D; unique_cookie=U_tc13v239pj2xmb5t6dasouizw1nk79um3rd*4; __utma=147393320.411936847.1583116386.1583116386.1583119062.2; __utmz=147393320.1583119062.2.2.utmcsr=zu.fang.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt_t0=1; __utmt_t1=1; __utmt_t2=1; __utmb=147393320.3.10.1583119062',
'referer': 'https://zu.fang.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'}session = requests.session() #建立会话利用session长链接
session.headers = headers
#进入首页
def get_index(url):html=session.get(url)if html.status_code==200:get_data(html)else:print("请求页面{}出错".format(url))
#获取数字
def get_number(text):number=re.compile('\d+')return number.findall(text)[0]
#获取页面的page总数
def get_pages(html):soup=etree.HTML(html.text)pages=soup.xpath('//div[@class="fanye"]/span[@class="txt"]/text()')number=get_number(pages[0])if number:return int(number)return None#获取页面
def get_data(html):pages=get_pages(html)if not pages:pages=1urls=['https://zu.fang.com/house-a00/i3%d/'%i for i in range(1,pages+1)]with ThreadPoolExecutor(max_workers=10) as t:for url in urls:print("crawl page %s"%url)t.submit(get_data_next,url)
#获取详情页面信息
def get_data_next(url):html=session.get(url)soup=etree.HTML(html.text)dls=soup.xpath('//div[@class="houseList"]/dl')for dl in dls:try:title=dl.xpath('dd/p/a/text()')[0]rent=dl.xpath('dd/div/p/span[@class="price"]/text()')[0]href=parse.urljoin("https://zu.fang.com",dl.xpath('dd/p/a/@href')[0])#print(title,rent,href)get_house_data(href,title,rent,href)except IndexError as e:print("dl error")#获取单个房间的信息
def get_house_data(url,*args):html=session.get(url)soup=etree.HTML(html.text)lines=soup.xpath('//div[starts-with(@class,"tab-cont-ri")]/div[@class="tr-line clearfix"]')[:2]results=""for line in lines:datas=line.xpath('div[contains(@class,"trl-item1")]/div[@class="tt"]/text()')results+="|".join(datas)#print(results)s=sess()try:print(s)house=House(block=args[0],rent=args[1],data=results)s.add(house)s.commit()print("commit")except Exception as e:print("rollback",e)s.rollback()def main():urls=['https://zu.fang.com/house-a0{}/'.format(i) for i in range(1,17)]with ProcessPoolExecutor(max_workers=10) as p:for url in urls:p.submit(get_index,url)if __name__ == '__main__':main()session.close()
这样我们就完成了项目,并且多线程多进程效率十分高
有些时候房天下会301,参考我们之前在状态码那一页所说的就可以成功get
这篇关于【python爬虫 系列】12.实战一 爬取北京地区所有的房租信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







