本文主要是介绍【已更新】2024美赛C题代码教学思路数据处理数学建模分析Momentum in Tennis,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题一完整的代码已给出,预计2号晚上或者3号凌晨全部给出。
代码逻辑如下:
C题第一问要求我们开发一个模型,捕捉得分时的比赛流程,并将其应用于一场或多场比赛。你的模型应该确定哪名球员在比赛的特定时间表现得更好,以及他们的表现有多好。那么换句话说,就是评价球员在比赛期间的一个实时的状态,
因此对于这个问题求解的关键在于如何从给出的数据中提取特征,而不是侧重于套用模型进行评价
在于我们需要根据提供的数据,分析出选手在场上的心态,体能的实时状态,随后根据提取出的选手特征对选手的表现进行评价,最后的结果会抽象成为一个数值用于表现选手在某一时刻下的表现得分,根据得分的差别反应选手的表现好坏程度
部分代码可视化图如下:
【腾讯文档】2024美赛C题详情docs.qq.com/doc/DVVp3WFVmTERTTlhC

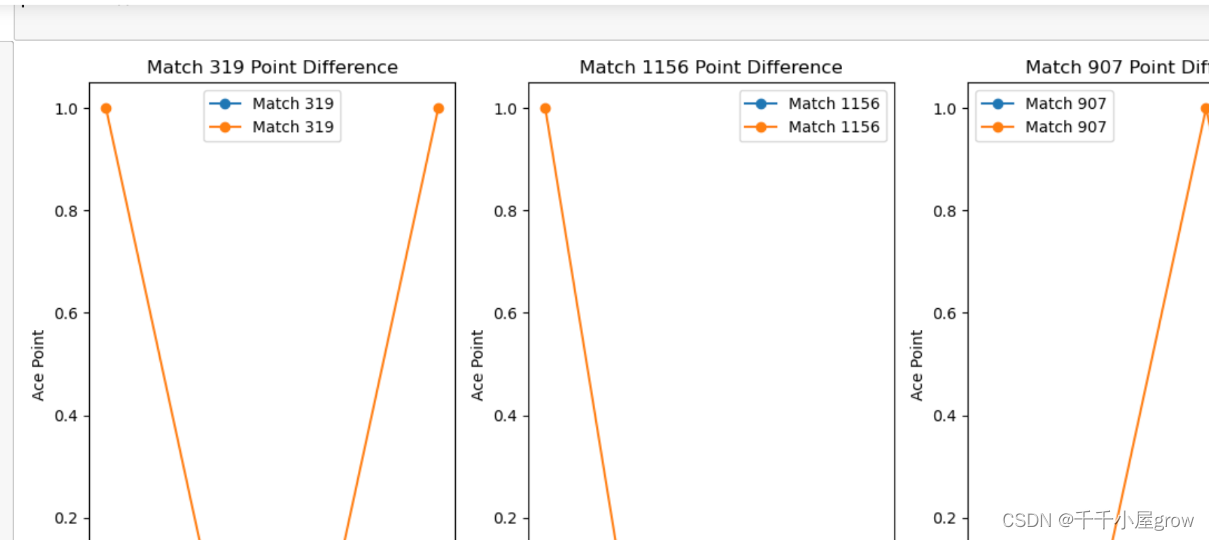
核心代码如下:
数据预处理部分:
数据预处理
Convert elapsed_time to timedelta
match_data[‘elapsed_time_td’] = pd.to_timedelta(match_data[‘elapsed_time’])
Calculate the time difference in seconds within each match_id group
match_data[‘time_diff’] = match_data.groupby(‘match_id’)[‘elapsed_time_td’].diff().dt.total_seconds()
Fill NaN values with the first elapsed_time value in each group, converted to seconds
match_data[‘time_diff’] = match_data.groupby(‘match_id’)[‘time_diff’].fillna(
match_data[‘elapsed_time_td’].dt.total_seconds()
)
Show the updated dataframe to verify changes
match_data[[‘match_id’, ‘elapsed_time’, ‘time_diff’]].head()
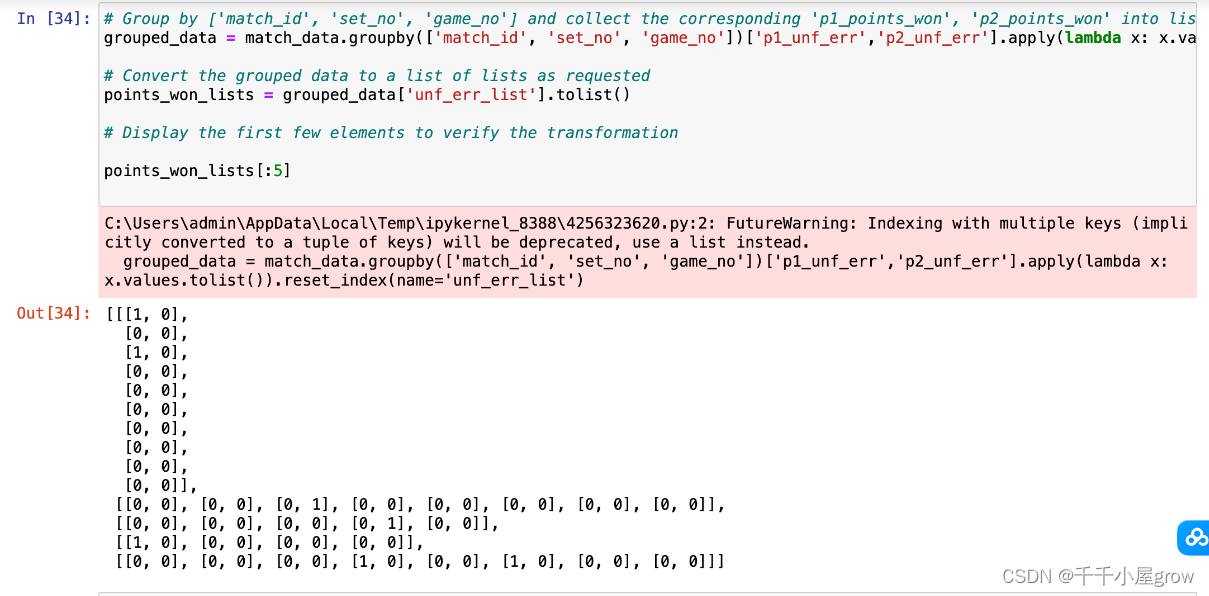
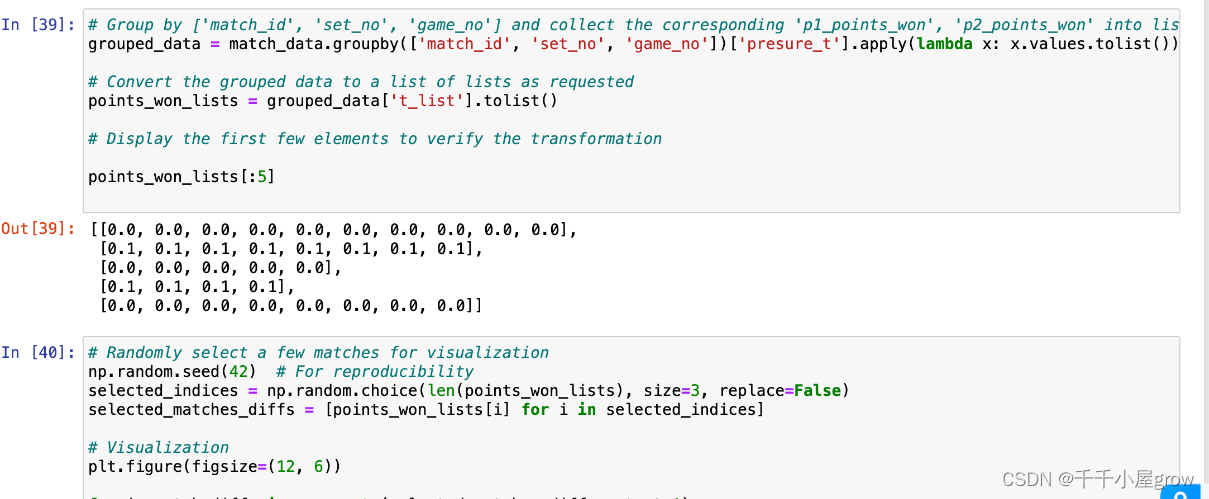
Group by [‘match_id’, ‘set_no’, ‘game_no’] and collect the corresponding ‘p1_points_won’, ‘p2_points_won’ into lists
grouped_data = match_data.groupby([‘match_id’, ‘set_no’, ‘game_no’])[[‘p1_points_won’, ‘p2_points_won’]].apply(lambda x: x.values.tolist()).reset_index(name=‘points_won_list’)
Convert the grouped data to a list of lists as requested
points_won_lists = grouped_data[‘points_won_list’].tolist()
Convert the ‘p1_points_won’, ‘p2_points_won’ values into their differences
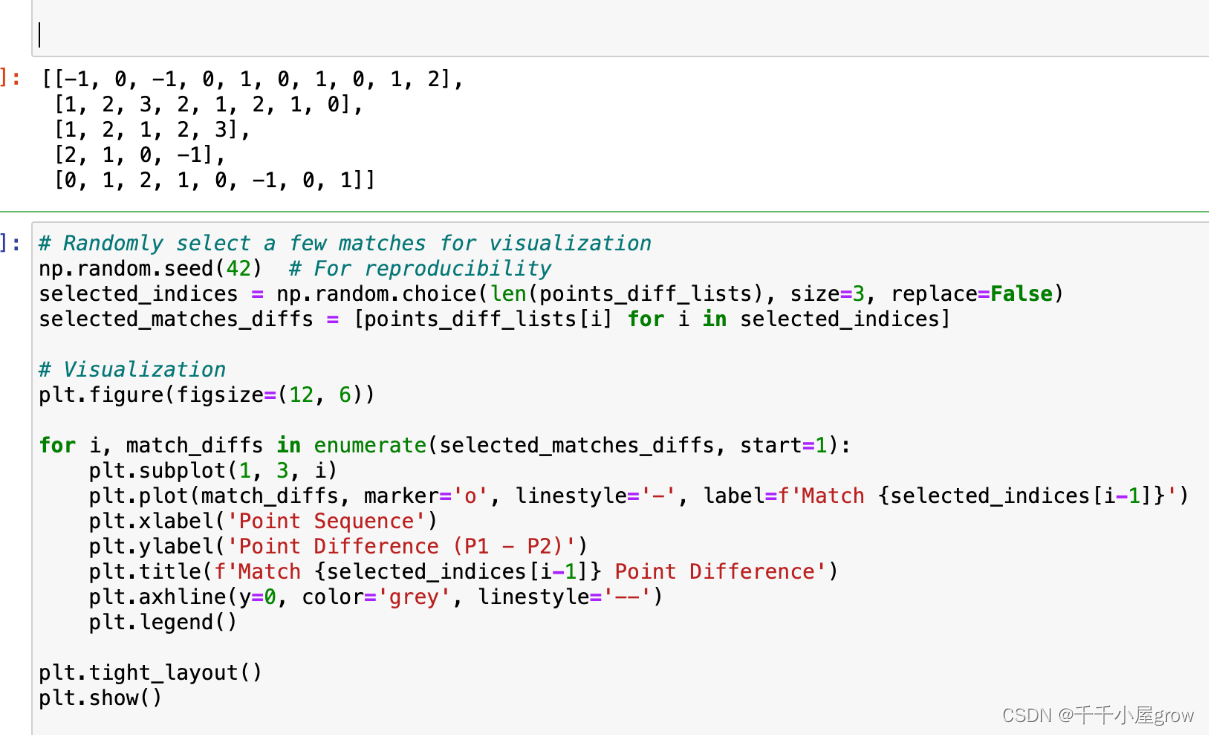
points_diff_lists = [[p1 - p2 for p1, p2 in match] for match in points_won_lists]
Display the first few elements to verify the transformation
points_diff_lists[:5]
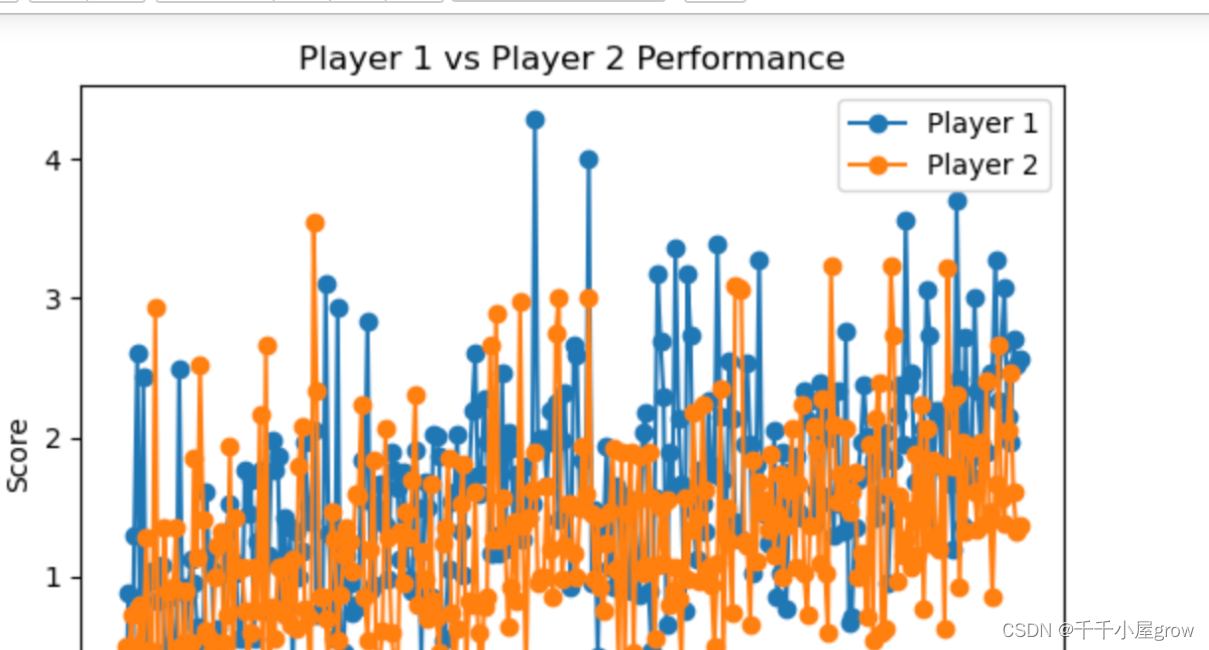
def Calculate_Performance(df):
df[‘p1’] = df[‘time_diff’]/100 + df[‘p1_sets’]*0.5 + df[‘p1_games’]*0.1 + df[‘p1_ace’] + df[‘p1_winner’]*0.5 - df[‘p1_unf_err’]*0.5
df[‘p2’] = df[‘time_diff’]/100 + df[‘p2_sets’]*0.5 + df[‘p2_games’]*0.1 + df[‘p2_ace’] + df[‘p2_winner’]*0.5 - df[‘p2_unf_err’]*0.5
for index in range(len(df)):if index == 0:if df.at[index, 'point_victor'] == 1:df.at[index, 'p1'] += 0.5else:df.at[index, 'p2'] += 0.5continueif df.at[index, 'point_victor'] == 1:if df.at[index-1, 'point_victor'] == 1:df.at[index, 'p1'] += 0.5 * 1.2else:df.at[index, 'p1'] += 0.5else:if df.at[index-1, 'point_victor'] == 1:df.at[index, 'p2'] += 0.5else:df.at[index, 'p2'] += 0.5 * 1.2return df['p1'], df['p2']
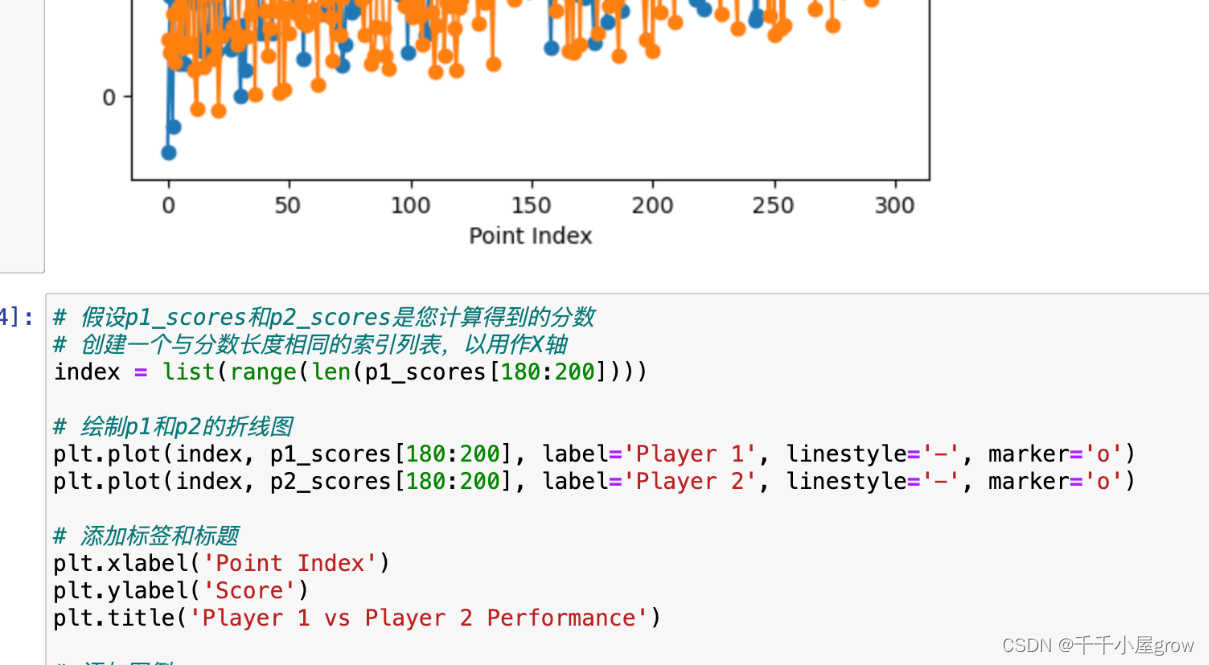
调用函数并获取结果
p1_scores, p2_scores = Calculate_Performance(match_data[match_data[‘match_id’]==‘2023-wimbledon-1301’])
p1_scores, p2_scores
问题分析
问题围绕2023年温网男单决赛中,20岁的西班牙新星卡洛斯·阿尔卡拉兹击败36岁的诺瓦克·德约科维奇的比赛。德约科维奇自2013年以来首次在温布尔登输球,结束了他在大满贯赛事中的杰出表现。这场比赛被认为是一场精彩的较量,经历了多次势头的转换,这些势头转换通常被归因于“动量”。在体育运动中,团队或球员可能会在比赛/比赛中感觉到自己有动量,或“力量/力量”,但很难衡量这种现象。此外,还不清楚比赛中的各种事件是如何产生或改变势头的。
提供了2023年温布尔登网球公开赛前两轮之后所有男子比赛的每一分数据。您可以自行选择包含其他玩家信息或其他数据,但必须完整记录来源。
也就是说,我们需要通过对已有的数据进行处理,找到其中包含动量特征的因素,构建一个模型去衡量这些因素是否使得我们选手的表示更加生猛,下面是我们的一个具体思路。
数据预处理
确保每个比赛的数据完整性,包括比赛时间、比分、发球情况等。
转换时间格式,统一比分表示方法。
将数据转换成可处理的数值数据,如在玩家的得分中,包含了AD这一项,这不利于我们后续的数据处理,可以将其转换成50
特征提取
目标是找到可以为运动员积累获胜“动量”的特征,可以从以下角度考虑是否存在连胜的“动量”。
比分变化:记录每一分后的总比分变化。
发球优势:统计每位运动员的发球局中赢得的分数比例。
破发点:记录每位运动员赢得和失去的破发点数量。
连续得分:运动员连续得分的次数,反映比赛势头。
回球成功率:根据返回深度和速度评估回球成功率。
运动员移动距离:反映体能和比赛中的活跃度。
模型设计
使用逻辑回归或随机森林等机器学习方法来评估每位运动员的表现。模型的输入是上述特征,输出是每位运动员的表现评分。
模型应用
选择具体的比赛数据应用模型,比较不同运动员的表现评分。
结果分析
根据模型的评分结果,分析哪位运动员在比赛中表现更好及其显示出的优势。
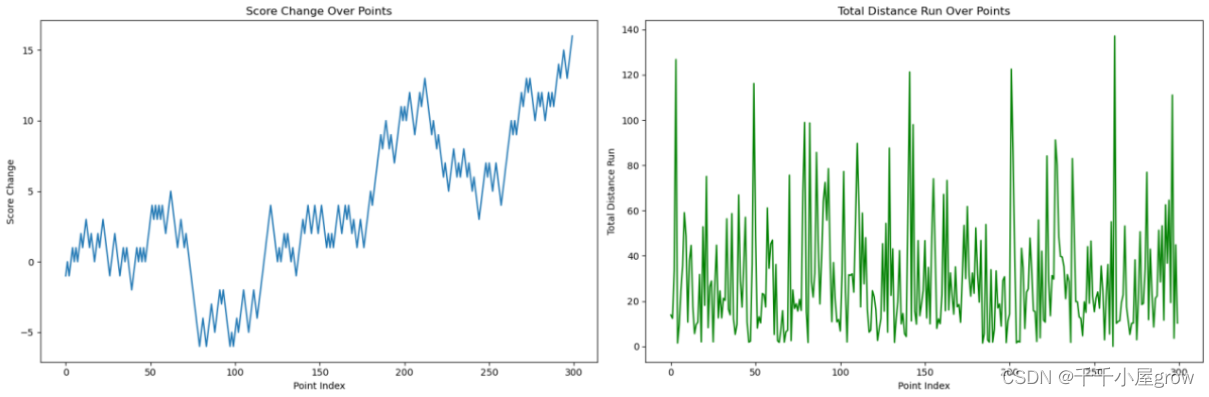
接下来,我们将开始实现这些步骤。首先进行数据预处理和特征提取。我们将从提供的比赛数据中提取关键特征。左图展示了比赛中每个得分点后选手之间比分差异的变化。这可以帮助我们理解比赛的势头和选手间的竞争状态。右图展示了比赛过程中两位选手总移动距离的变化,反映了选手的体能消耗和场上活跃度。
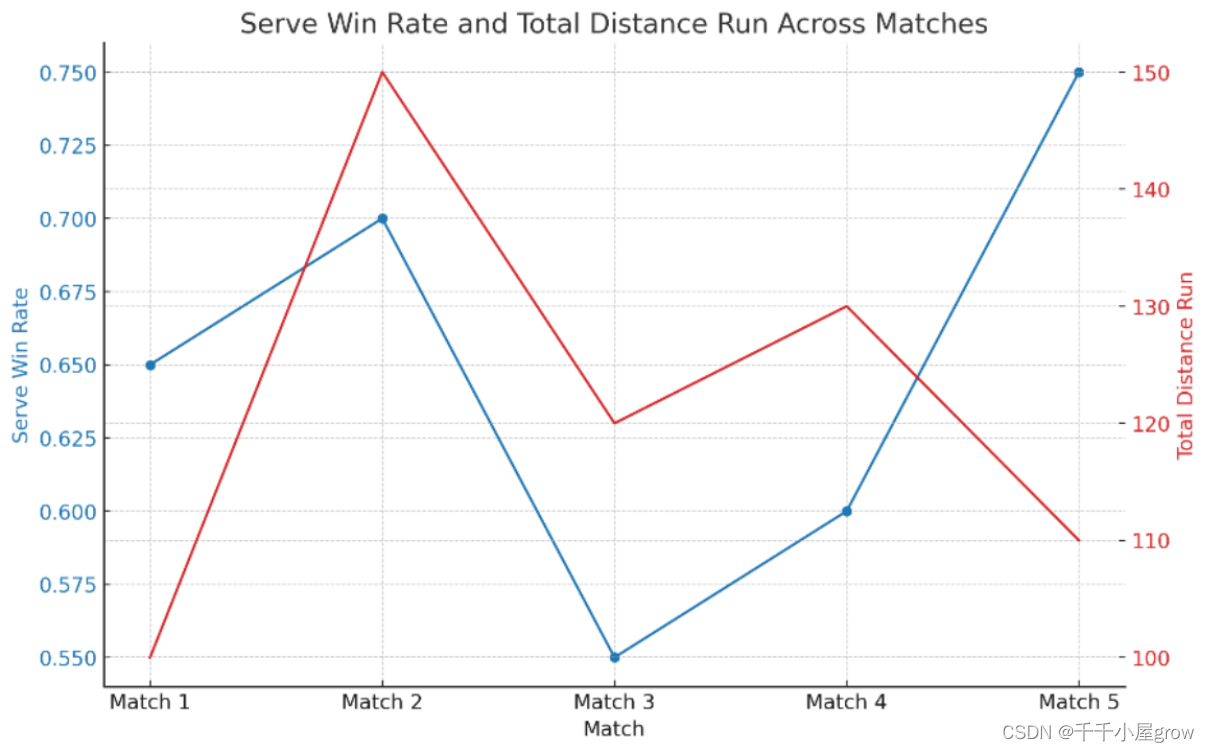
下图通过计算选手1在其发球局中赢得的分数比例,我们绘制了一个折线图来展示选手在不同round下的总共的移动距离以及得分比例。
这篇关于【已更新】2024美赛C题代码教学思路数据处理数学建模分析Momentum in Tennis的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




