本文主要是介绍Python与Xpath--二手房房价数据爬取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、写在开头
本文在【城市感知计算】代码的基础上进行了修改和调整以更符合自己的需求和习惯,在此感谢作者的分享。
其次我想说的是如果有同志看见了我的文章并且想要尝试实现的话,希望能“合理、温柔”地爬取数据,给网站减少访问压力,他好我也好。最好是先将一页HTML下载到本地进行调试,调试好后再进行爬取。
二、大概逻辑
简要叙述一下大概的逻辑,通过查看链家网站有两个逻辑:
首先是需要在链家小区页获取每个小区的id。该网页链接也很简单,以湖南省长沙市岳麓区为例,其url链接为---https://cs.lianjia.com/xiaoqu/yuelu/---其中cs为长沙缩写,yuelu为岳麓区缩写,大概看了下,其他城市的url链接也是通过这个逻辑来构造的,但有一点需要注意的就是城市名称或区域名称可能出现多音字的情况,如武汉的沌口开发区,“沌”有“zhuan”和"dun"两个读音,这种情况需要仔细确认。
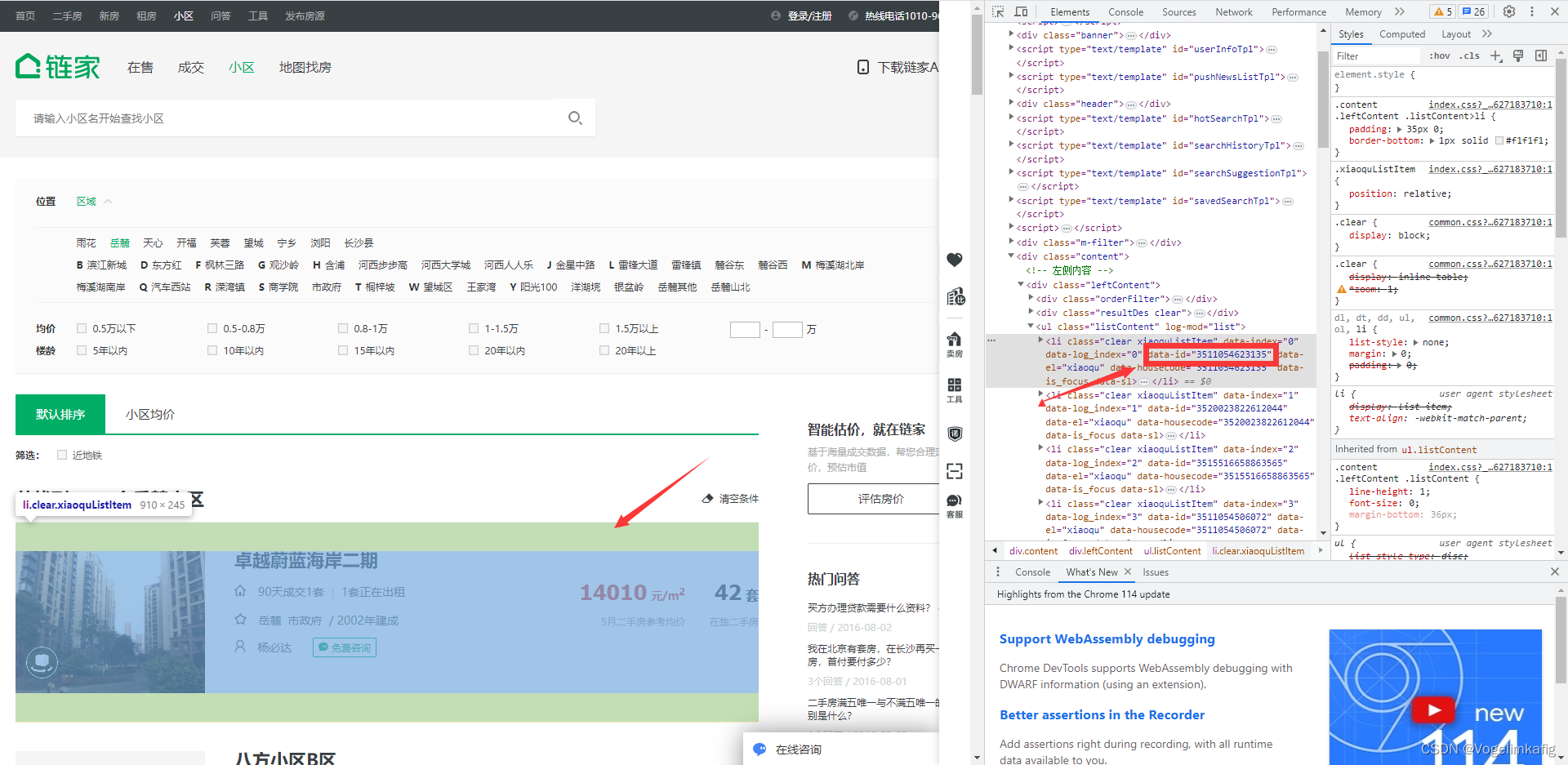
通过Xpath获取到小区id后可以通过小区id构造url链接获取每个小区二手房的详细信息,进入到小区详情页可以看到其url链接为---https://cs.lianjia.com/xiaoqu/3511054623135/---前面都是固定的模式,仅仅是后面有区别,这个数字就是每个小区的id。通过构造不同小区的url链接我们就可以获取不同小区的详细信息了。
最后得到的数据大概如下:
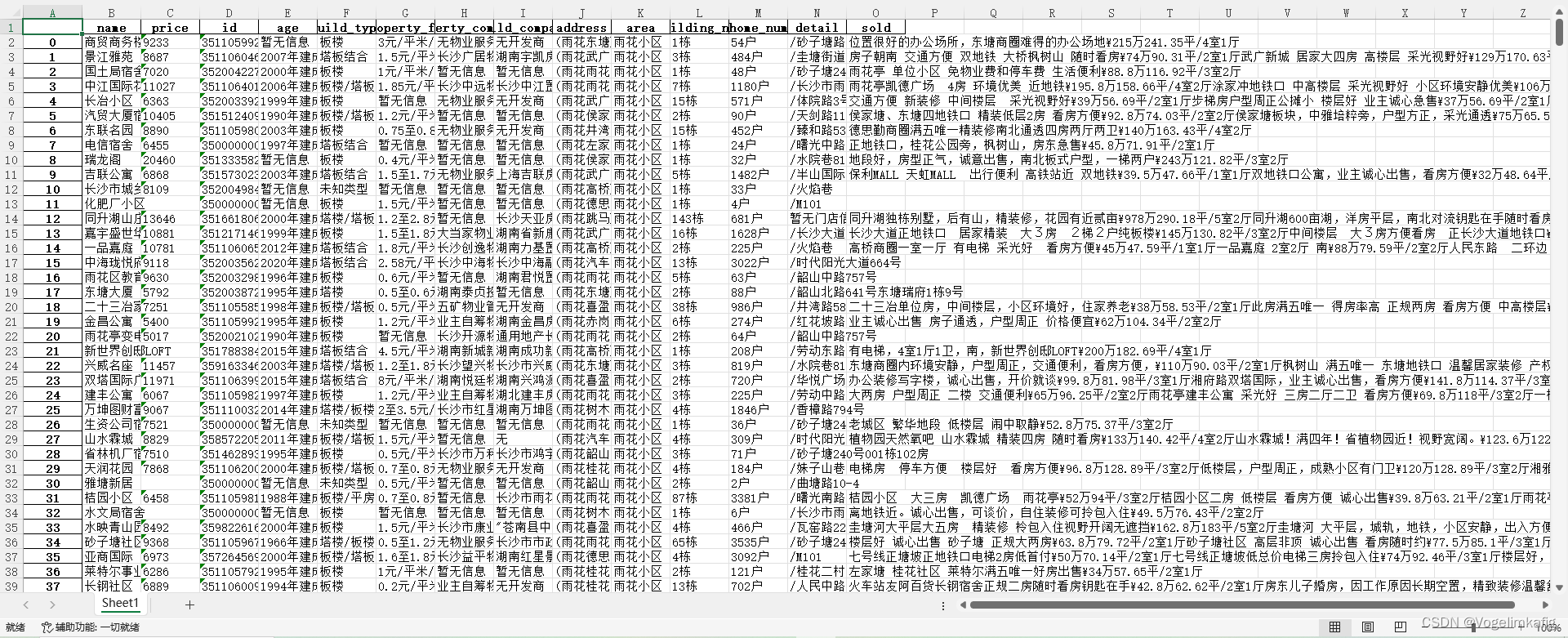
大概获取数据的逻辑就是这样,具体详细细节可以查看原文。
三、代码
import requests
import time
from lxml import etree
from pypinyin import pinyin, lazy_pinyin, Style
import pandas as pdurl = 'https://cs.lianjia.com/xiaoqu/{}/pg{}/'
names = []
ids = []
data = {'name': names, 'id': ids}# 获取列表数据,主要为小区id
def fetch_data(com):name = ''.join(lazy_pinyin(com))r_url = url.format(name, 1)try:response = requests.get(r_url)content = response.content# 获取区域范围内总小区数量numbers = etree.HTML(content).xpath('/html/body/div[4]/div[1]/div[2]/h2/span/text()')[0]print(numbers, com)# 计算页数,以求获取更全面的数据for i in range(int(int(numbers) / 30 + 1)):i += 1name = ''.join(lazy_pinyin(com))r_url = url.format(name, i)try:response = requests.get(r_url)content = response.contenttree = etree.HTML(content)# 确认这一点的逻辑,详见Xpath节点定位规则xpath_expression = "//li[@class='clear xiaoquListItem']" # 选取所有属性为...的li子元素,不考虑其在文档中的位置elements = tree.xpath(xpath_expression)for element in elements:try:a = element.xpath("./@data-id")[0] # 当前节点的根元素b = element.xpath('.//div[@class="info"]/div[@class="title"]/a/text()')[0] # .//是指从当前节点的子节点中进行查找data['id'].append(a)data['name'].append(b)except Exception as e:print(e)time.sleep(1)except Exception as e:print(e)time.sleep(1)except Exception as e:print(e)time.sleep(10)try:pd.DataFrame(data).to_excel('你自己的文件存储路径_{}.xlsx'.format(com))print("小区id表写出成功!")except Exception as e:print(e)time.sleep(1)# coms = [...] # 填入您的coms数据
# coms = ['雨花', '岳麓', '天心', '开福', '芙蓉', '望城', '宁乡', '浏阳', '长沙县']
coms = ['雨花'] # 为减轻其服务器压力,也为分阶段保存数据防止被封ip,分区域一个个爬取
for com in coms:fetch_data(com)ages = []
build_types = []
property_fees = []
property_companys = []build_companys = []
addresses = []
building_nums = []
home_nums = []
details = []
solds = []
areas = []names = []
prices = []
ids = []print("开始爬取详细数据,共计{}个小区".format(len(set(data['id']))))
for id, i in zip(list(set(data['id'])), range(len(set(data['id'])))): # 需要注意的是,当使用zip()函数同时遍历多个序列时,它会在最短的序列用完后停止迭代。# 如果需要遍历所有的序列,可以使用itertools.zip_longest()函数,该函数可以在序列用完后用指定值填充缺失的元素。print("当前数据获取进度:{:.2f}%".format(i/len(set(data['id']))*100))url = 'https://cs.lianjia.com/xiaoqu/{}'content = requests.get(url.format(id), timeout=10).content# following-sibling 为定位方法,获取弟节点,即为选择当前节点之后的所有同级节点,此处为获取建筑年代、建筑类型等具体数据try:age = etree.HTML(content).xpath('//div[@class="xiaoquInfoItem"]/span[text()="建筑年代"]/following-sibling::span/text()')[0]except Exception as e:age = ''ages.append(age)try:build_type = etree.HTML(content).xpath('//div[@class="xiaoquInfoItem"]/span[text()="建筑类型"]/following-sibling::span/text()')[0]except Exception as e:build_type = ''build_types.append(build_type)try:property_fee = etree.HTML(content).xpath('//div[@class="xiaoquInfoItem"]/span[text()="物业费用"]/following-sibling::span/text()')[0]except Exception as e:property_fee = ''property_fees.append(property_fee)try:property_company = etree.HTML(content).xpath('//div[@class="xiaoquInfoItem"]/span[text()="物业公司"]/following-sibling::span/text()')[0]except Exception as e:property_company = ''property_companys.append(property_company)try:build_company = etree.HTML(content).xpath('//div[@class="xiaoquInfoItem"]/span[text()="开发商"]/following-sibling::span/text()')[0]except Exception as e:build_company = ''build_companys.append(build_company)try:area = etree.HTML(content).xpath('//div[@class="xiaoquDetailbreadCrumbs"]/div[1]/a[3]/text()')[0]except Exception as e:area = ''areas.append(area)try:address = etree.HTML(content).xpath('//div[@class="detailDesc"]/text()')[0].strip()except Exception as e:address = ''addresses.append(address)try:building_num = etree.HTML(content).xpath('//div[@class="xiaoquInfoItem"]/span[text()="楼栋总数"]/following-sibling::span/text()')[0]except Exception as e:building_num = ''building_nums.append(building_num)try:home_num = etree.HTML(content).xpath('//div[@class="xiaoquInfoItem"]/span[text()="房屋总数"]/following-sibling::span/text()')[0]except Exception as e:home_num = ''home_nums.append(home_num)try:detail = etree.HTML(content).xpath('//div[@class="xiaoquInfoItem"]/span[text()="附近门店"]/following-sibling::span/text()')[0]except Exception as e:detail = ''details.append(detail)try:sold = ""# 使用XPath选择每个优质二手房的元素houses = etree.HTML(content).xpath('//ol[@class="clear"]/li')# 遍历每个优质二手房并提取信息for house in houses:title = house.xpath('.//div[@class="goodSellItemTitle"]/a/text()')[0]price_d = house.xpath('.//span[@class="goodSellItemPrice"]/text()')[0]description = house.xpath('.//div[@class="goodSellItemDesc"]/text()')[0]sold = sold + title + price_d + description + '\t'except Exception as e:sold = ''solds.append(sold)try:name = etree.HTML(content).xpath("//h1[@class='detailTitle']/text()")[0]except:name = ''names.append(name)try:price = etree.HTML(content).xpath("//span[@class='xiaoquUnitPrice']/text()")[0]except:price = ''prices.append(price)ids.append(id)# 注意数据组织模式
all_data = {'name': names, 'price': prices, 'id': ids, 'age': ages, 'build_type': build_types,'property_fee': property_fees, 'property_company': property_companys, 'build_company': build_companys,'address': addresses, 'area':areas, 'building_num': building_nums, 'home_num': home_nums, 'detail': details,'sold': solds}pd.DataFrame(all_data).to_excel('你自己的文件存储路径_房价信息总表_{}.xlsx'.format(coms[0]))
print("房价信息总表写出成功!")四、总结
(一)对程序运行时间进度的了解
在实际程序运行过程中会发现爬取一个区域的数据会消耗比较长的时间,怎么确定爬取的进度呢?我采用for循环记录循环的次数,从而计算进度的百分比,但是我又不想每循环一次都print一个进度出来,后面和朋友讨论了下可以按以下代码的逻辑实现每隔10%print一下进度,但是逻辑还是有些问题的,当数据量小于10就不符合了,还得重新设计。(虽然我朋友吐槽这是一个臭需求,上面代码就能很好实现了,但我觉得挺有意思的)
nums = 11334idx_f = nums//10idx_l = idx_fa = 1for i in range(nums):if i == idx_l:print("{}%".format(10*a))a+=1idx_l += idx_f(二) zip()函数的学习
当for循环对象不是单纯的数字时,我想要统计当前循环的次数就可以用zip()函数同时遍历多个序列(除了这个目前没有想到其他方法),但是需要注意的是:
当使用zip()函数同时遍历多个序列时,它会在最短的序列用完后停止迭代。也就是两个序列长度不相等时会导致一些问题。如果需要遍历所有的序列,可以使用itertools.zip_longest()函数,该函数可以在序列用完后用指定值填充缺失的元素。(三)set()函数的学习
set()函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。能很好的筛选出重复的数据,因为在程序运行过程中发现获取到的id表中确实有数据重复的情况,需要进行去重处理。
(四)数据存储结构的学习
这种由list组成的字典在数据存储的时候还挺方便,用pandas库中dataframe写出也很方便。
import pandas as pddata = {'姓名': ['张三', '李四', '王二'], '年龄': [23, 27, 26],'性别': ['男', '女', '女']
}
df = pd.DataFrame(data)
print(df)(五)小区经纬度的确定
原文并没有获取到准确的小区经纬度信息,采用的是通过小区的地址进行地理编码从而获取其经纬度,但是链家网站上实际是有确切的位置信息的,但是我找了下好像也没发现在哪,不知道什么情况。
这篇关于Python与Xpath--二手房房价数据爬取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





