本文主要是介绍中科大计网学习记录笔记(四):Internet 和 ISP | 分组延时、丢失和吞吐量,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
学习视频:中科大郑烇、杨坚全套《计算机网络(自顶向下方法 第7版,James F.Kurose,Keith W.Ross)》课程
该视频是B站非常著名的计网学习视频,但相信很多朋友和我一样在听完前面的部分发现信息量过大,有太多无法理解的地方,在我第一次点开的时候也有相同的感受,但经过了一段时间项目的学习,对计网有了更多的了解,所以我准备在这次学习的时候做一些记录并且加入一些我的理解,希望能够帮助到大家。
往期笔记可以看专栏中的内容😊😊😊
资料分享:
视频课件分享链接,提取码pho1
计算机网络(第七版) 自顶向下方法分享链接,提取码7ln4
1.5 Internet 和 ISP
1.5.1 互联网络结构 —— 网络的网络
端系统通过接入 ISPs 连接到互联网,比如住宅、公司和大学的 ISPs,然后接入的 ISPs 必须是互联的,因此任何两个端系统的用户苦于相互发送分组给对方;接入 ISPs 互联的方式的发展和演化是根据经济的、国家的原因变化和发展的。
以渐进式的方式来看当前互联网的结构
-
直接将他们互联在一起,成本指数级增长
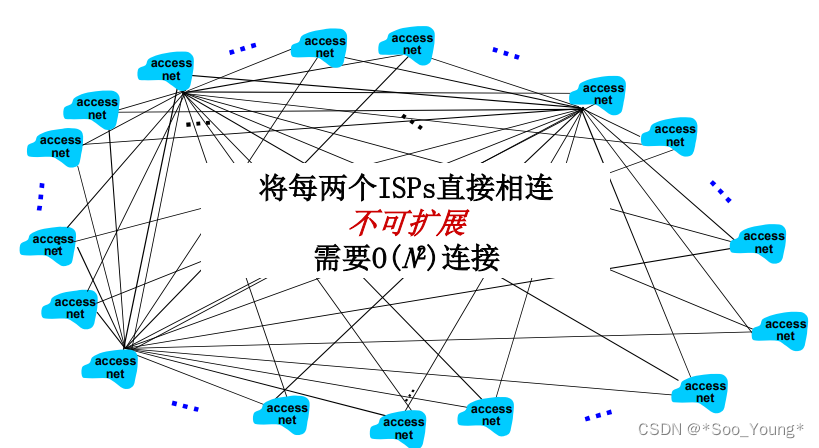
-
将每个接入的 ISP 接入到全局的 ISP

-
能够实现全局 ISP 的运营商有很多,同时有利可图,很多的全局 ISP 被建立起来

-
在竞争的同时还会有合作,上面的各种全局 ISP 不互通,通过各个 ISP 之间的合作可以完成业务的拓展,且如果从一方到另一方之间互相的流量对等,就可以实现对等互联的结算关系
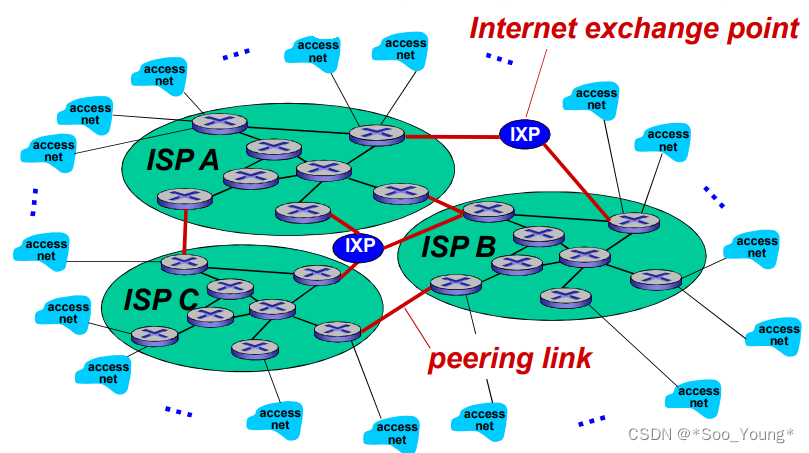
-
然后业务会进行细分,会出现区域网络,用户通过区域网络接入到全局的 ISPs

-
内容提供商网络(ICP),也可能会构建他们自己的网络,因为要将他们的服务接入其他 ISP 会导致成本过高,而且对其他地区的服务提供会很困难(跨州、跨国等),所以为了让他们的服务和内容更加靠近用户,他们会选择自己提供网络,来优化用户体验和减少支出。
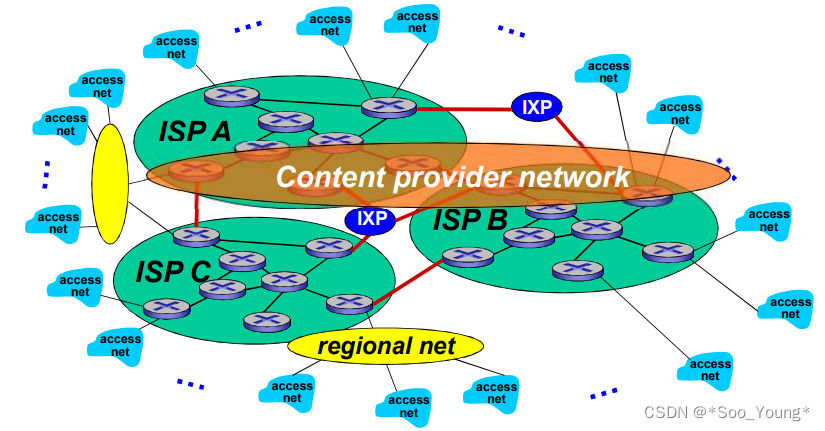
最终可以抽象这个图
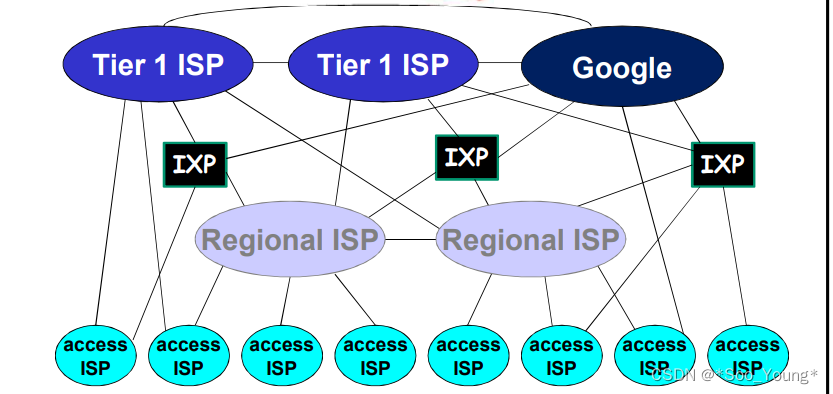
在网络的最中心,存在为数不多的充分链接(带宽很宽)的大范围网络,然后向下又与其他的 ISP 相连。
IXP(Internet Exchange Point),互联网交换点。IXP 是一种网络设施,其主要目的是促进不同互联网服务提供商(ISPs)、内容交付网络(CDNs)和其他网络服务提供商之间的互联互通。
1.6 分组延时、丢失和吞吐量
1.6.1 分组丢失和分组延时是怎样发生的?
分组到达链路的速率超过了链路的输出能力
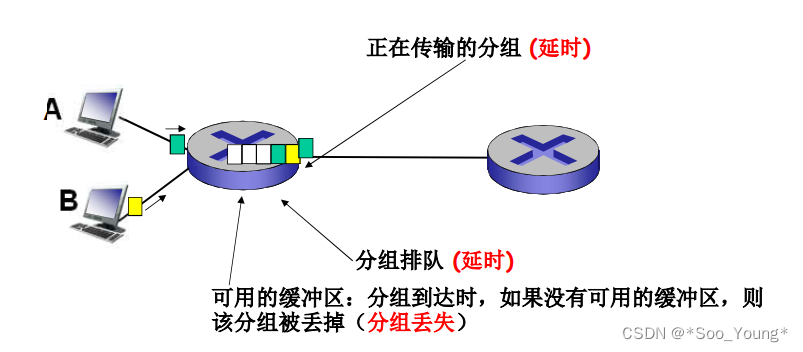
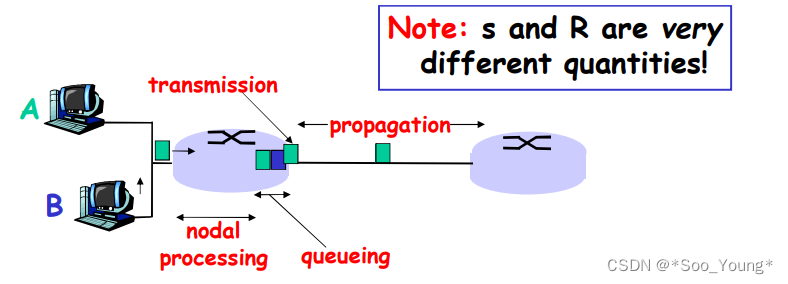
分组延迟的分类
- 节点检查延时:检查
bit级的差错,检查分组首部来决定将分组传到何处 - 排队延时:在输出链路上等待传输的时间,依赖于路由器的拥塞程度
- 传输延时:将分组发送到链路上的时间
- 传播延时:数据在链路上传播的时间
1.6.2 车队类比

车辆以 100 km/h 的速度传播,收费站服务每一辆车需要 12s(传输延时)
通过计算可得,将完全经过第一个收费站(最后一个车通过收费站),需要 120s,而传播延时也就是数据在链路上传播的时间,需要 1h,所以在最后一个车通过收费站的时候第一辆车还远远没有到达下一个收费站,所以传播延时是不能忽略的,其远大于传输延时
再来看另一种情况

车辆以 1000 km/h 的速度传播,收费站服务每辆车需要 1分钟
通过计算可得,完全经过第一个收费站需要 60min,而到达第二个收费站仅仅需要 6min,也就是第一个收费站还在服务的时候,第二个就已经有车辆开始了,这时候就可以忽略掉传传播延迟,因为其远小于传输延时
1.6.3 排队延时
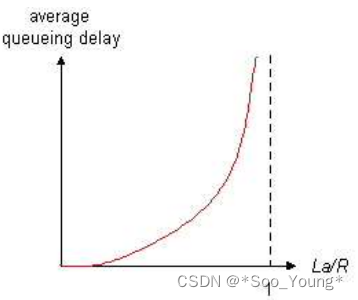
排队延时取决于流量强度:
I = L ∗ a / R I=L*a / R I=L∗a/R
L:分组长度(bits)
a:分组到达队列的平均速率
R:链路带宽
排队延时随流量强度的变化,当流量强度为 1 的时候,其排队延时趋向于无穷
Tranceroute 诊断工具:用于跟踪数据包从源主机到目标主机的路径。通过 traceroute,用户可以 了解数据包在互联网中经过的中间路由器(或跳数),以及每个路由器的响应时间。
在使用 traceroute 时,用户向目标主机发送一系列的 ICMP(Internet Control Message Protocol)或 UDP(User Datagram Protocol)数据包,这些数据包会依次经过网络中的路由器。每个路由器在接收到数据包后,会返回一个响应,包含了它自身的信息。这个过程会重复多次,形成一个跟踪路径的列表。
1.6.4 分组丢失
原因:链路的队列缓冲区的容量有线
当分组到达一个满的队列的时候,该分组就会被丢失,丢失的分组可能会被前一个节点或者源端系统重传或者不重传。
重传是由上一条还是源主机重传是取决于通信协议的设计和实现
- 由上一个链路重传:
- 停等协议(Stop-and-Wait): 在停等协议中,发送方发送一个分组,然后等待接收到对应的确认(ACK)之后才发送下一个分组。如果发送方在一定时间内没有收到确认,它会假设分组丢失,并重新发送。这里的重传是由上一个链路(接收方)触发的。
- 自动重传请求(Automatic Repeat reQuest,ARQ): 在ARQ类协议中,发送方周期性地重传未收到确认的分组。这包括选择性重传(Selective Repeat)和连续 ARQ(Continuous ARQ)等变种。重传的触发仍然是由上一个链路(接收方)检测到分组丢失而引发的。
- 由源头重传:
- TCP 协议: 在TCP中,如果发送方检测到未收到确认的分组,它会根据接收到的重复确认(Duplicate ACK)信息来触发重传。TCP的重传机制是由源头(发送方)主动发起的。
1.6.5 吞吐量
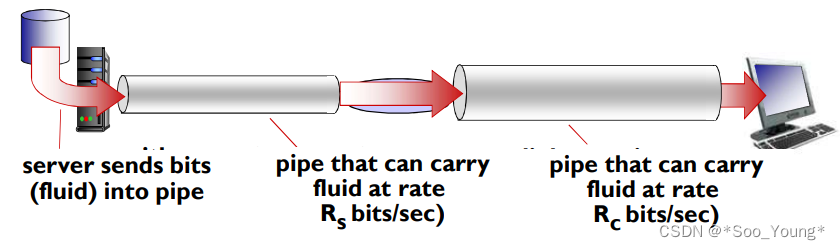
从源端到目标端之间传输的速率
- 瞬间吞吐量:在一个时间点的速率
- 平均吞吐量:在一个长时间的平均值
理解为平均速度和瞬时速度的关系
- 瓶颈链路(Bottleneck Link)是指在一个网络中,由于某个特定链路的带宽、延迟或其他性能限制,导致整个网络的传输速率受到限制的链路。这条链路的性能相对较差,成为整体网络性能的瓶颈点。
这篇关于中科大计网学习记录笔记(四):Internet 和 ISP | 分组延时、丢失和吞吐量的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







