本文主要是介绍缓存修炼手册:跟着我走进分布式缓存的神秘世界,解密缓存雪崩、缓存穿透等技术难题。发掘缓存预热、更新、降级的独门绝技,让你在面试中轻松秒杀,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
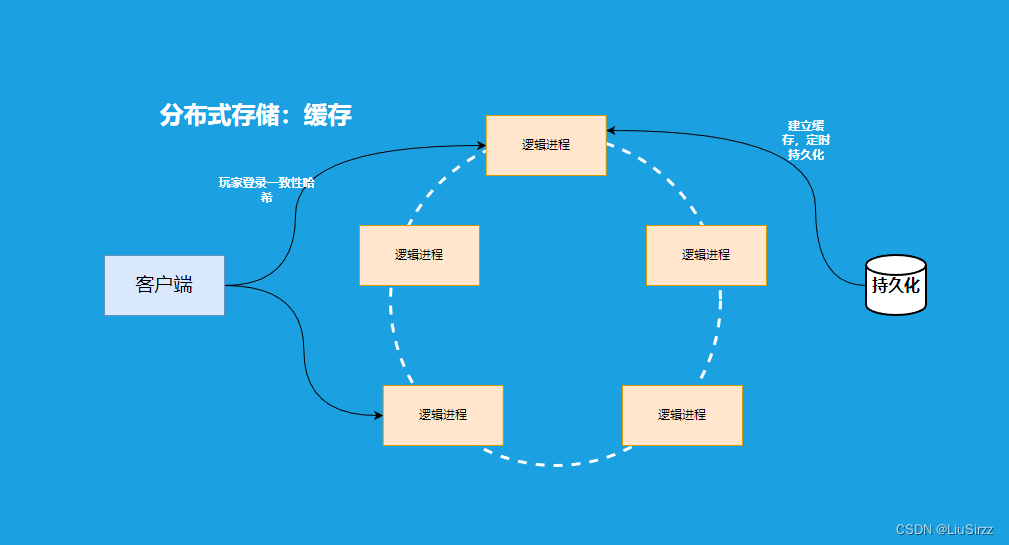
1. 分布式缓存概念
分布式缓存是一种用于存储和管理数据的系统,它将数据缓存在多个节点上,以提高性能和可扩展性。以下是分布式缓存的一些关键概念和特点:
-
缓存节点:
-
分布式缓存系统由多个节点组成,每个节点负责存储一部分数据。这些节点可以分布在不同的物理服务器上,形成一个缓存集群。
-
-
数据分片:
-
缓存中的数据被划分为多个分片,每个分片由不同的缓存节点管理。数据的分片可以根据某种策略(例如,哈希或范围分片)进行划分,以实现负载均衡和高效的数据访问。
-
-
数据副本:
-
为了提高数据的可用性和容错性,分布式缓存通常会在不同的节点上存储数据的副本。当一个节点不可用时,可以从其他节点获取数据。
-
-
一致性协议:
-
为了保持分布式缓存中数据的一致性,系统通常使用一致性协议来确保在节点之间进行数据同步。常见的一致性协议包括 CAP(Consistency、Availability、Partition tolerance)理论、Paxos 和 Raft 等。
-
-
缓存失效策略:
-
分布式缓存通常支持缓存失效策略,即确定数据在缓存中存储的时间。失效策略可以基于时间(TTL,Time-to-Live)或基于访问模式(LRU,Least Recently Used)等。
-
-
分布式锁:
-
在多节点环境中,为了保证数据的一致性,分布式缓存可能需要支持分布式锁。分布式锁用于协调多个节点对共享资源的访问,以避免并发问题。
-
-
支持的数据结构:
-
除了简单的键值对之外,一些分布式缓存系统还提供了丰富的数据结构,如哈希表、列表、集合等,以满足不同场景下的需求。
-
-
监控和管理:
-
为了保障系统的稳定性和性能,分布式缓存通常提供监控和管理功能,允许管理员实时监视缓存的使用情况、性能指标以及节点健康状况。
-
常见的分布式缓存系统包括 Redis、Memcached、Apache Ignite、Hazelcast 等。这些系统通过提供高性能、可扩展性和容错性的特性,帮助应用程序加速数据访问,提高系统的整体性能。
2. 缓存雪崩及其解决方案
缓存雪崩是指在某个时间点,缓存中的大量数据同时失效或过期,导致大量的请求直接打到数据库或后端系统上,引起系统瞬时压力过大,可能导致系统崩溃或性能急剧下降。通常,缓存雪崩发生在缓存层失效的情况下,而没有有效的应对措施。
缓解缓存雪崩的解决方案:
-
合理设置缓存过期时间:
-
设置不同的缓存过期时间,避免大量缓存同时失效。可以采用随机化过期时间,使得缓存的失效时间分散开,减少同时失效的概率。
-
-
使用多级缓存:
-
采用多级缓存架构,包括本地缓存、分布式缓存等。即使某个缓存层失效,其他层的缓存仍然能够提供部分数据,减轻后端压力。
-
-
热点数据永不过期:
-
对于一些热点数据,可以设置其永不过期,确保这些关键数据不会在同一时刻失效,从而避免大量请求直接击穿到数据库。
-
-
加锁或串行化处理:
-
在缓存失效的时候,对数据的加载操作加锁或串行化处理,防止大量并发请求同时击穿到后端系统,减缓压力。
-
-
使用缓存预热:
-
在系统启动或低峰期,通过缓存预热机制,将热门数据加载到缓存中,降低缓存失效导致的压力。
-
-
限流和降级:
-
对于突发流量,可以通过限流和降级的手段来保护系统。限制请求的并发数,或者在缓存失效的情况下返回默认值,暂时降低对后端系统的压力。
-
例子:
假设一个电商网站的商品信息缓存在分布式缓存中,由于促销活动结束后,大量商品信息的缓存同时失效,导致用户在短时间内查询商品信息时,直接打到数据库上,引发了缓存雪崩。
解决方案可以是设置合理的缓存过期时间,使用多级缓存(本地缓存 + 分布式缓存),将热门商品数据设置为永不过期,加锁或串行化处理缓存失效时的数据加载操作,以及通过缓存预热机制在低峰期加载商品信息。这样可以有效减缓缓存雪崩导致的压力激增,保障系统的稳定性。
3.缓存穿透及其解决方案
缓存穿透是指查询一个不存在的数据,由于缓存中不含该数据,每次查询都会直接请求数据库,导致大量无效的数据库查询流量,可能会对数据库造成压力,甚至引起雪崩。
缓解缓存穿透的解决方案:
-
布隆过滤器:
-
使用布隆过滤器来过滤掉那些肯定不存在的数据,避免这些请求直接访问数据库。布隆过滤器是一种空间效率较高的数据结构,用于判断一个元素是否属于一个集合。
-
-
缓存空值:
-
当查询到数据库中不存在的数据时,将空结果也缓存起来,但设置一个较短的过期时间。这样,在接下来的一段时间内,相同的查询请求就可以直接从缓存中获取到空结果,而不会直接访问数据库。
-
-
热点数据永不过期:
-
对于一些热点数据,可以设置其永不过期,确保这些关键数据不会在同一时刻失效,即使有穿透请求也能够避免对数据库的直接访问。
-
-
限制并发访问:
-
对于相同的查询请求,可以使用互斥锁等机制限制其并发访问。当一个请求在查询数据库时,其他相同请求需要等待,避免同时触发缓存穿透。
-
例子:
假设一个电商网站的商品信息缓存在分布式缓存中,而攻击者恶意请求不存在的商品ID,如果不进行防范,这些请求会直接穿透缓存访问数据库,造成数据库压力激增。
解决方案可以是使用布隆过滤器,对查询请求的商品ID进行过滤,将一定不存在的ID直接拦截。另外,对于查询到数据库中不存在的商品ID,也可以将空结果缓存起来,但设置较短的过期时间,避免对数据库的直接访问。在一些热点商品的情况下,可以将这些数据设置为永不过期,以应对缓存穿透的风险。这样可以有效防止攻击者通过构造不存在的ID来触发缓存穿透问题。 在Java中,可以使用Guava库提供的BloomFilter类来实现布隆过滤器。下面是一个简单的布隆过滤器的Java使用案例:
首先,确保你的项目中引入了Guava库。如果使用Maven,可以在pom.xml中添加以下依赖:
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>30.1-jre</version> <!-- 请根据实际情况选择最新版本 -->
</dependency>
然后,可以通过以下方式使用布隆过滤器:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;public class BloomFilterExample {public static void main(String[] args) {// 创建一个布隆过滤器,预计包含1000个元素,期望的误判率为0.01BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), 1000, 0.01);// 向布隆过滤器中添加元素bloomFilter.put("item1");bloomFilter.put("item2");bloomFilter.put("item3");// 检查元素是否存在于布隆过滤器中System.out.println(bloomFilter.mightContain("item1")); // 输出 trueSystem.out.println(bloomFilter.mightContain("item4")); // 输出 false}
}
在这个案例中,我们使用Guava的BloomFilter类创建了一个布隆过滤器,指定了预期包含的元素数量和期望的误判率。然后,我们向布隆过滤器中添加了几个元素,并检查了某些元素是否存在于过滤器中。
需要注意的是,布隆过滤器是一个概率型数据结构,存在一定的误判率。在实际使用中,需要根据具体业务场景选择合适的参数来权衡误判率和内存消耗。
4.分布式系统中如何做缓存预热?
缓存预热概念:
缓存预热是指在系统上线或者某个缓存失效后,通过提前加载缓存数据,将一些常用或者重要的数据预先放入缓存中,以避免在实际请求过程中因为缓存失效而导致大量请求直接访问数据库,提高系统性能。
缓存预热的实现步骤:
-
确定预热数据: 确定哪些数据是热点数据或者常用数据,需要被提前加载到缓存中。
-
编写预热脚本: 编写脚本或者程序,负责从数据源中加载需要预热的数据,并将其放入缓存中。
-
定时执行预热脚本: 在系统启动时或者定时执行预热脚本,将数据加载到缓存中。
-
合理设置缓存过期时间: 设置缓存过期时间,确保预热的数据能够在一定时间内保持有效,同时避免占用过多缓存资源。
例子:
假设有一个电商网站,其中商品信息是一个重要的热点数据,用户频繁查询商品详情。在系统启动时或者每天的低峰期,可以通过缓存预热来提前加载部分热门商品信息到缓存中。
public class CacheWarmUp {public static void main(String[] args) {// 模拟从数据库中查询热门商品数据List<Product> hotProducts = queryHotProductsFromDatabase();// 将热门商品信息预热到缓存中warmUpCache(hotProducts);}private static List<Product> queryHotProductsFromDatabase() {// 模拟从数据库中查询热门商品数据的逻辑// 这里可以连接数据库,执行 SQL 查询,获取热门商品数据// 返回查询结果的集合return Arrays.asList(new Product(1, "商品A", "描述A", 100.0),new Product(2, "商品B", "描述B", 150.0),new Product(3, "商品C", "描述C", 200.0));}private static void warmUpCache(List<Product> hotProducts) {// 模拟将热门商品信息加载到缓存中的逻辑// 这里可以使用缓存框架提供的 API,将数据放入缓存中for (Product product : hotProducts) {// 将商品信息放入缓存,键可以使用商品ID,值为商品对象Cache.put(product.getId(), product);}}static class Product {private int id;private String name;private String description;private double price;// 省略构造函数和Getter方法}static class Cache {private static Map<Integer, Product> cache = new HashMap<>();public static void put(int key, Product value) {cache.put(key, value);}public static Product get(int key) {return cache.get(key);}}
}
在这个例子中,queryHotProductsFromDatabase 模拟了从数据库中查询热门商品数据的逻辑,warmUpCache 模拟了将热门商品信息加载到缓存中的过程。通过执行 main 方法,可以在系统启动时预热缓存,提前加载热门商品信息,减少实际请求中对数据库的访问。
5.缓存更新
缓存更新是指在数据发生变化时,及时将新的数据同步到缓存中,以确保缓存中的数据与数据源保持一致。缓存更新的目的是避免缓存中存储的数据与实际数据不一致,保持系统的数据一致性。
缓存更新的实现策略:
-
主动更新:
-
当数据源发生变化时,系统主动通知缓存进行更新。可以通过消息队列、发布订阅等机制来通知缓存进行更新。
-
-
定时刷新:
-
定时任务定期检查数据源的变化,并将变化的数据同步到缓存中。虽然实时性较差,但能够保证数据最终一致性。
-
-
失效更新(Cache-Aside模式):
-
当缓存中的数据过期或被使用时,再从数据源中获取最新数据。这种方式适用于数据变化频率较低的场景。
-
-
写穿透更新:
-
在写操作时,先更新数据源,然后再更新缓存。确保缓存中的数据总是由最新的数据源提供。
-
例子:
在Java中,可以使用Jedis库来操作Redis,以下是一个简单的例子,演示如何使用Java与Redis结合进行缓存更新:
import redis.clients.jedis.Jedis;public class RedisCacheUpdateExample {private static final String REDIS_HOST = "localhost";private static final int REDIS_PORT = 6379;public static void main(String[] args) {// 初始化Jedis连接try (Jedis jedis = new Jedis(REDIS_HOST, REDIS_PORT)) {// 模拟初始化商品缓存initCache(jedis);// 模拟商品价格发生变化,更新商品缓存updateProductPrice(jedis, 1, 120.0);// 查询商品信息时,先从缓存中查找Product product = getProductFromCache(jedis, 1);if (product != null) {System.out.println("商品ID:" + product.getId() + ",商品名称:" + product.getName() +",商品价格:" + product.getPrice());} else {System.out.println("商品不存在");}}}private static void initCache(Jedis jedis) {// 模拟初始化商品缓存jedis.hset("products", "1", serialize(new Product(1, "商品A", 100.0)));jedis.hset("products", "2", serialize(new Product(2, "商品B", 150.0)));jedis.hset("products", "3", serialize(new Product(3, "商品C", 200.0)));}private static void updateProductPrice(Jedis jedis, int productId, double newPrice) {// 模拟商品价格发生变化,更新缓存if (jedis.hexists("products", String.valueOf(productId))) {Product product = deserialize(jedis.hget("products", String.valueOf(productId)));product.setPrice(newPrice);jedis.hset("products", String.valueOf(productId), serialize(product));System.out.println("商品价格更新成功,商品ID:" + productId + ",新价格:" + newPrice);// 实际项目中,还可以通过消息队列等方式通知其他节点进行缓存更新} else {System.out.println("商品不存在");}}private static Product getProductFromCache(Jedis jedis, int productId) {// 查询商品信息时,先从缓存中查找if (jedis.hexists("products", String.valueOf(productId))) {return deserialize(jedis.hget("products", String.valueOf(productId)));}return null;}private static String serialize(Product product) {// 在实际项目中,可以使用更复杂的序列化方式,如JSON序列化return product.getId() + ";" + product.getName() + ";" + product.getPrice();}private static Product deserialize(String serializedProduct) {// 在实际项目中,可以使用更复杂的反序列化方式,如JSON反序列化String[] parts = serializedProduct.split(";");int id = Integer.parseInt(parts[0]);String name = parts[1];double price = Double.parseDouble(parts[2]);return new Product(id, name, price);}static class Product {private int id;private String name;private double price;public Product(int id, String name, double price) {this.id = id;this.name = name;this.price = price;}// 省略Getter和Setter方法}
}
在这个例子中,通过使用Jedis库与Redis进行交互,模拟了商品缓存的初始化、价格更新和查询操作。在实际项目中,通常会使用更复杂的序列化和反序列化方式,并考虑分布式缓存和消息队列等技术来实现更可靠的缓存更新。
6.缓存降级
缓存降级是一种在面临缓存故障或性能下降时的应对策略。当缓存系统出现异常或性能下降时,为了保障系统的稳定性,可以选择关闭缓存或降低对缓存的依赖,直接访问底层数据源,从而避免缓存带来的问题。
缓存降级的实现策略:
-
异常降级:
-
当缓存系统出现异常时,系统可以自动降级,将缓存的读写操作直接切换到底层数据源,保证系统的正常运行。
-
-
性能降级:
-
当缓存系统的性能下降时,可以通过监控系统性能指标,自动切换至底层数据源,以减轻缓存对系统性能的影响。
-
-
手动降级:
-
在系统遇到特定情况(如高并发、缓存失效等)时,可以手动触发缓存降级策略,直接访问底层数据源。
-
缓存降级的举例说明:
假设有一个电商网站,商品信息存储在缓存中,当缓存系统出现异常时,可以通过降级策略直接从数据库中获取商品信息。
public class CacheDegradationExample {public static void main(String[] args) {// 模拟缓存系统出现异常boolean cacheException = true;// 查询商品信息Product product = getProduct(1, cacheException);if (product != null) {System.out.println("商品ID:" + product.getId() + ",商品名称:" + product.getName() +",商品价格:" + product.getPrice());} else {System.out.println("商品信息获取失败,可能正在进行缓存降级处理");}}private static Product getProduct(int productId, boolean cacheException) {try {// 模拟缓存读取操作if (!cacheException) {Product cachedProduct = getFromCache(productId);if (cachedProduct != null) {return cachedProduct;}}// 如果缓存异常或未命中,从数据库获取商品信息return getFromDatabase(productId);} catch (Exception e) {// 异常降级:在缓存异常时直接访问数据库return getFromDatabase(productId);}}private static Product getFromCache(int productId) {// 模拟从缓存中获取商品信息的操作// 这里可以使用缓存框架提供的 API// 返回缓存中的商品对象return null;}private static Product getFromDatabase(int productId) {// 模拟从数据库获取商品信息的操作// 这里可以连接数据库,执行 SQL 查询// 返回从数据库中查询到的商品对象return new Product(productId, "商品A", 100.0);}static class Product {private int id;private String name;private double price;public Product(int id, String name, double price) {this.id = id;this.name = name;this.price = price;}// 省略Getter和Setter方法}
}
在这个例子中,通过 getProduct 方法模拟了商品信息获取的流程,当缓存系统出现异常时,通过异常降级策略直接访问数据库获取商品信息。在实际项目中,需要根据具体情况选择合适的缓存降级策略。

关注公众号 洪都新府笑颜社,发送 “面试题” 即可免费领取一份超全的面试题PDF文件!!!!
这篇关于缓存修炼手册:跟着我走进分布式缓存的神秘世界,解密缓存雪崩、缓存穿透等技术难题。发掘缓存预热、更新、降级的独门绝技,让你在面试中轻松秒杀的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





