本文主要是介绍使用python3爬取网页,利用aria2下载电影,Jellyfin自动更新最新电影,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:在我搭建好Jellyfin软件后,因为只能播放本地视频,就想能不能播放网络上的电影,可以每天自动下载并更新,这样就不用我手工下载好,再上传到NAS中播放。或许有更好的方法,那就是直接用电影播放源,那就有个问题了,没有那个视频网愿意给播放源,所以还是自己慢慢下载后再播放吧。个人对于python语言也是小白,在网络上寻找大神的脚本稍加修改得到的。
如果需要搭建jellyfin,请看我之前的博客-家庭影院Jellyfin搭建,linux网页视频播放器。
环境:centos7
工具:python3、jellyfin、shell脚本、aria2
1、安装python3
默认安装好centos7系统后,自带有python2.7.5的版本,所以需要安装python3的版本。2.7.5的版本不能删除,否则centos系统会崩溃。请从官网下载python3.8版本。
关于python2升级至python3,会有一些问题,但都能解决,请参考以下资料:
1)Centos7升级python2到python3
2)pbzip2: error while loading shared libraries: libbz2.so.1.0: cannot open shared object file
3)centos7安装python3及其配置pip(建立软连接)
2、编辑python脚本
命名脚本为movie.py,将以下复制到py脚本保存,执行python3 movie.py。查看爬取结果,是否生成文件。
脚本不是我编写的,是借鉴大神,然后根据电影天堂现在的地址和信息,做了一些改动,获取下载电影地址
# encoding: gbk
# 我们用到的库
import requests
import bs4
import re
import pandas as pddef get_data(url):'''功能:访问 url 的网页,获取网页内容并返回参数:url :目标网页的 url返回:目标网页的 html 内容'''headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',}try:r = requests.get(url, headers=headers)r.raise_for_status()r.encoding = 'gbk'return r.textexcept requests.HTTPError as e:print(e)print("HTTPError")except requests.RequestException as e:print(e)except:print("Unknown Error !")def parse_data(html):'''功能:提取 html 页面信息中的关键信息,并整合一个数组并返回参数:html 根据 url 获取到的网页内容返回:存储有 html 中提取出的关键信息的数组'''bsobj = bs4.BeautifulSoup(html,'html.parser')info = []# 获取电影列表tbList = bsobj.find_all('table', attrs = {'class': 'tbspan'})# 对电影列表中的每一部电影单独处理for item in tbList:movie = []link = item.b.find_all('a')[0]# 获取电影的名称name = link.string# 获取详情页面的 urlurl = 'https://www.dytt8.net' + link["href"]# 将数据存放到电影信息列表里movie.append(name)movie.append(url)try:# 访问电影的详情页面,查找电影下载的磁力链接temp = bs4.BeautifulSoup(get_data(url),'html.parser')tbody = temp.find_all('a')print(tbody)#^magnet.*?fannouce# 下载链接有多个(也可能没有),这里将所有链接都放进来for i in tbody:lines = i.get("href") if "magnet" in lines:#download = lines.a.text#print(lines)movie.append(lines)print(movie)# 将此电影的信息加入到电影列表中info.append(movie)except Exception as e:print(e)return infodef save_data(data):'''功能:将 data 中的信息输出到文件中/或数据库中。参数:data 将要保存的数据 '''filename = 'C:/Users/Administrator/Desktop/movie.txt'dataframe = pd.DataFrame(data)dataframe.to_csv(filename, mode='a', index=False, sep=';', header=False)def main():# 循环爬取多页数据#for page in range(1, 114):# print('正在爬取:第' + str(page) + '页......') # 根据之前分析的 URL 的组成结构,构造新的 url#if page == 1:# index = 'index'#else:# index = 'index_' + str(page) # url = 'https://www.dy2018.com/2/'+ index +'.html'#url='https://www.dy2018.com/2/index.html'url='https://www.dytt8.net/html/gndy/dyzz/index.html'# 依次调用网络请求函数,网页解析函数,数据存储函数,爬取并保存该页数据html = get_data(url)movies = parse_data(html)save_data(movies)#print('第' + str(page) + '页完成!')if __name__ == '__main__':print('爬虫启动成功!')main()print('爬虫执行完毕!')3、安装aria2
安装教程,请访问我的博客第一条,安装nextcloud里面有详细的安装aria2教程
4、编写aria2下载的shell脚本
#!/bin/bash
cd /downloads
count=0
#/root/shell/movie.txt,这个地址是movie.py执行后生成的下载地址,请根据你实际的地址填写
route=/root/shell/movie.txt
name=(`awk -F ";" '{print $1}' $route | cut -d '《' -f2|cut -d '》' -f1 | cut -d '/' -f1`)
addr=(`awk -F ";" '{print $3}' $route`)
nr=`awk '{print NR}' $route | tail -n1`
prop=`awk -F ";" '{print $3}' $route | cut -d '&' -f2 | awk -F "." '{print $8}'`for ((i=0; i<=nr; i++))
dolet count++echo "正在下载第$count个电影,《${name[$i]}》"sudo -u www nohup aria2c -o "${name[$i]}.${prop[$i]}" "${addr[$i]}" &echo "第$count个电影完成创建,转后台下载中"sleep 2
donerm -rf /root/shell/movie.txt5、测试
执行脚本,请注意先后顺序,先执行python3 movie.py。等待爬取下载电影地址完成后,执行sh movie.sh。
6、增加自动任务,添加到crontab
crontab -e中增加以下信息,获取这个方法不完善,但仍在改进
#每2天运行python脚本,获取电影天堂下载地址
20 1 */2 * * python3 /root/shell/movie.py
#每2天运行一次aria2下载电影
30 1 */2 * * sh /root/shell/movie.sh
7、使用jellyfin添加媒体库
在这里,把媒体库的自动扫描调整为每个小时都扫描一次,这样可以很快的增加到媒体库。
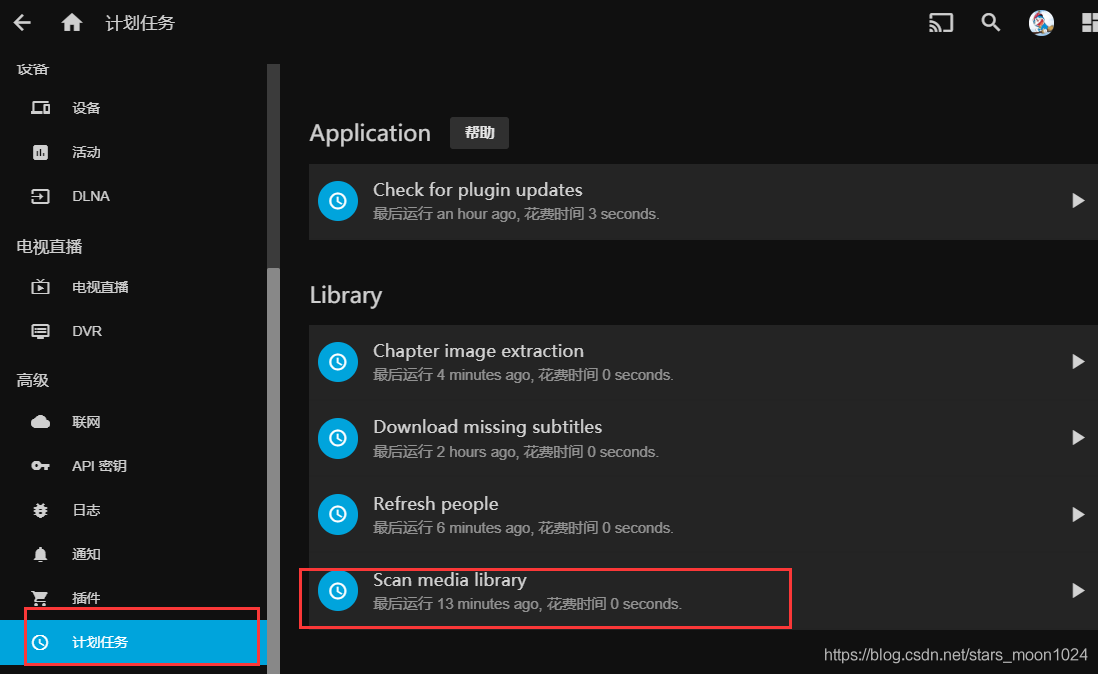
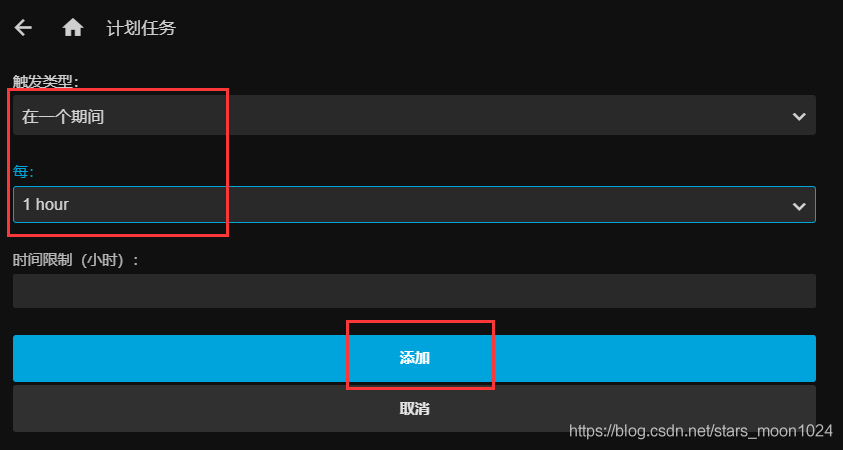
至此,已经完成了自动从电影网下载电影,并自动扫描到媒体库,就可以不用管了,每2天自动更新。写的脚本只下载了详情页的第一页,如果想下载很多页,请把主方法中的循环打开调整数字就可以了
这篇关于使用python3爬取网页,利用aria2下载电影,Jellyfin自动更新最新电影的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




