本文主要是介绍Python实战:爬取微博,获取南京地铁每日客流数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在这篇文章中,我们将使用 Python 进行网络爬虫,爬取微博上的南京地铁每日客流数据。
一、分析网页
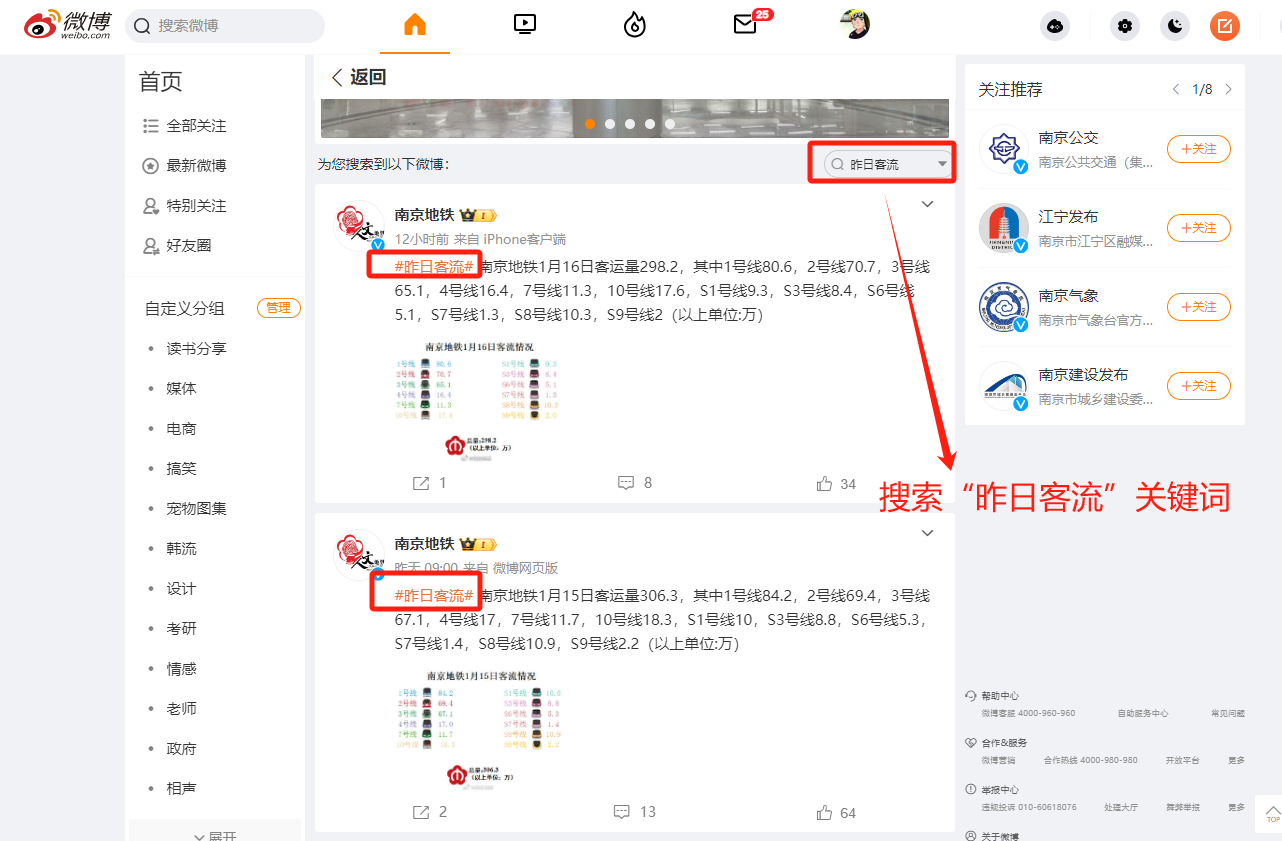
在“南京地铁”微博主页搜索“昨日客流”关键词,搜索到每天发布的昨日客流数据。
“南京地铁”微博主页地址https://weibo.com/u/2638276292
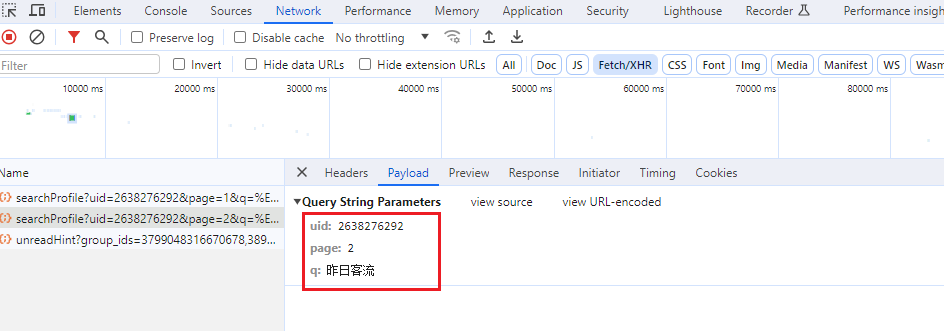
在浏览器开发者工具界面查看相关请求 url、payload、response 等参数,可以很清晰的分析出爬虫逻辑。
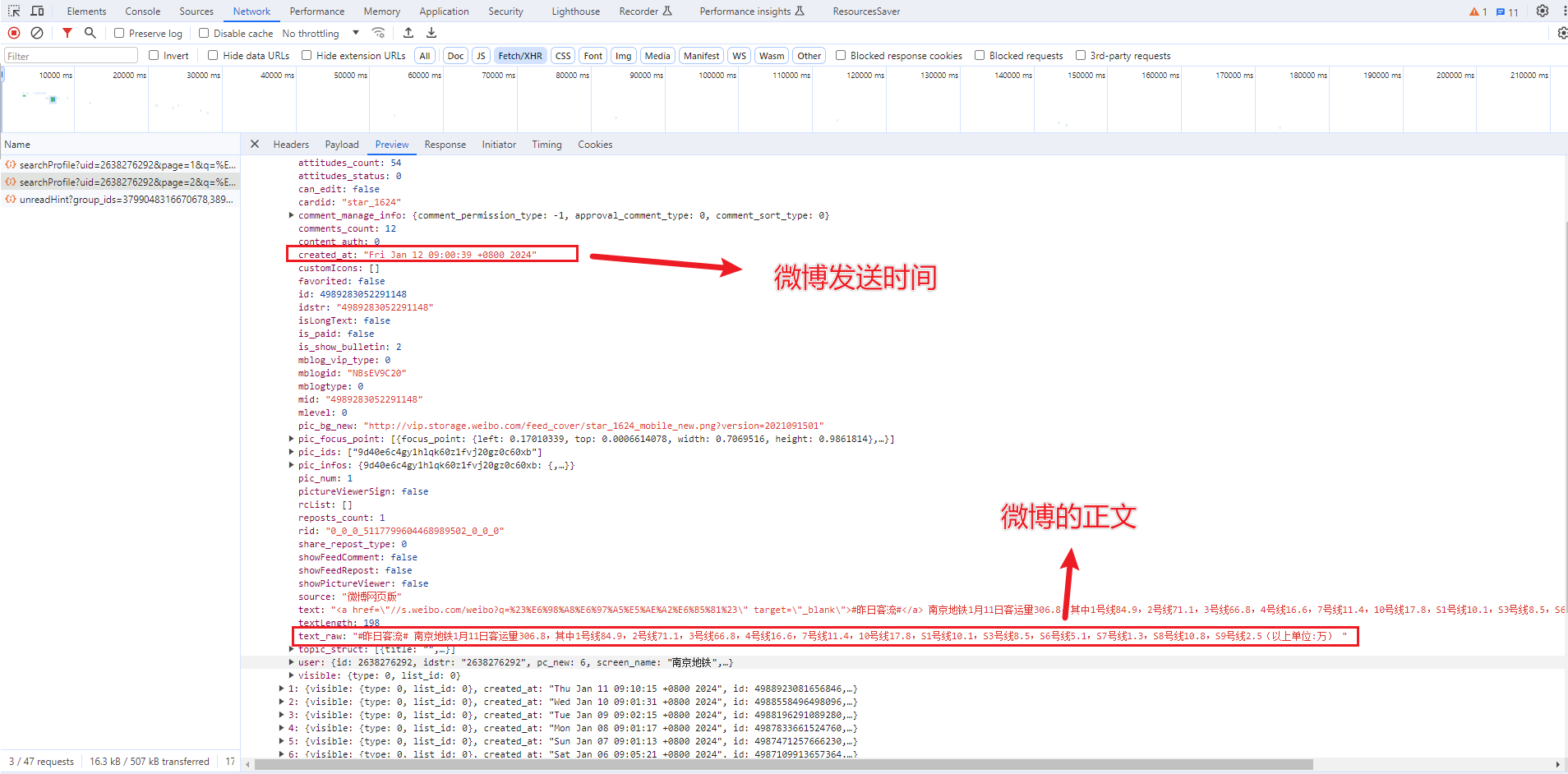
爬虫代码就不展开说了,下面直接给出完整代码。分析过程可以参考之前公众号文章,写过好几篇类似的文章。
二、爬取数据
编写 python 代码,获取到过去 1035 天含有“昨日客流”关键词的微博,并保存为一个 excel 表。
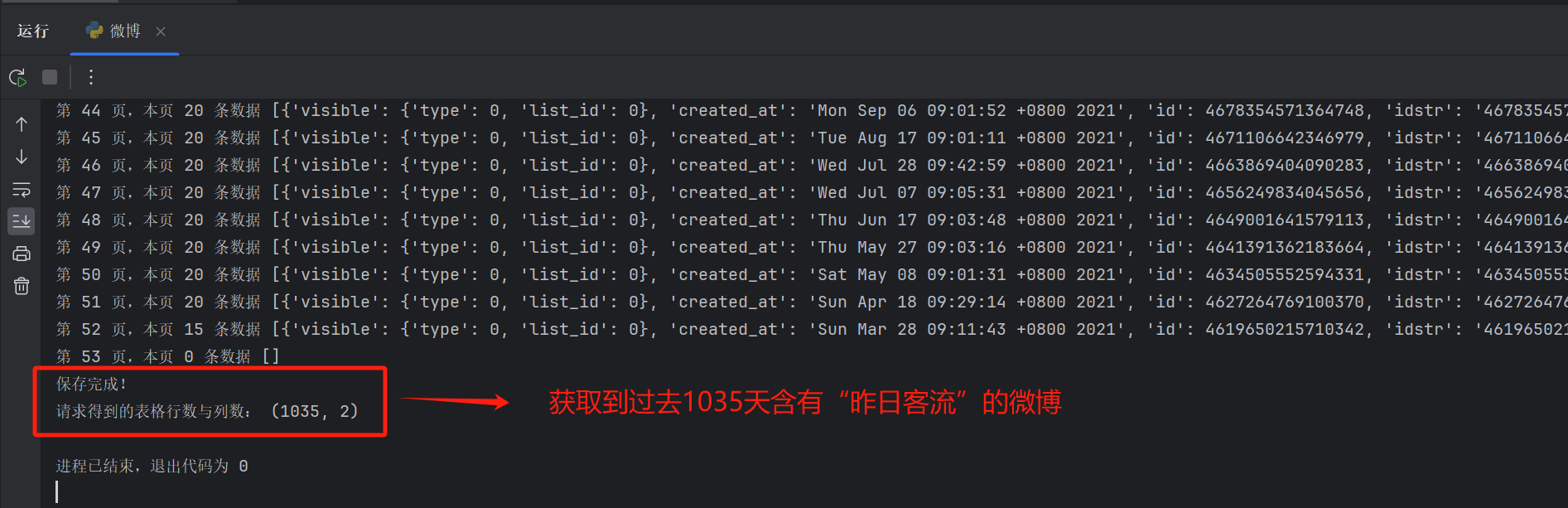
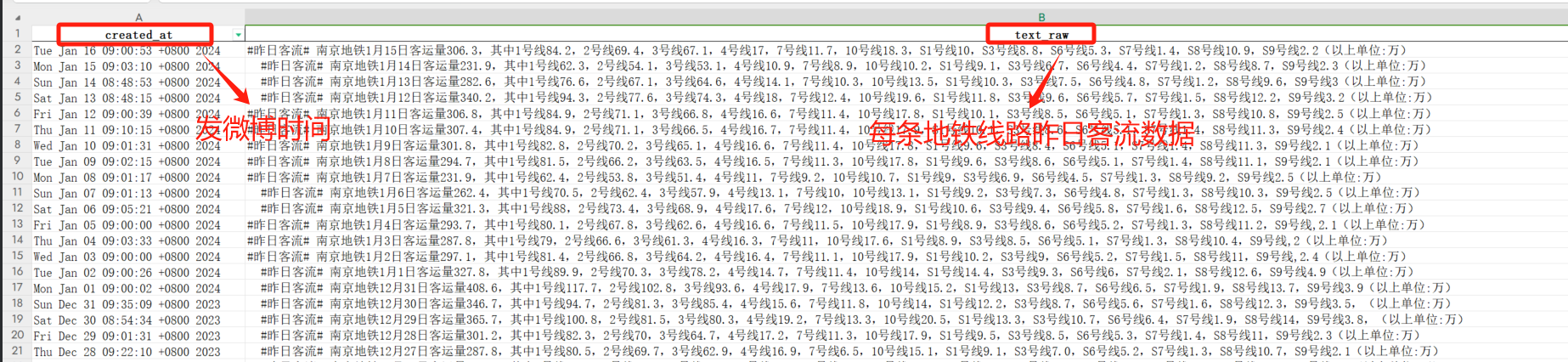
保存的 excel 表如下,created_at字段是微博发送时间,text_raw字段是微博正文。
三、解析数据
对created_at字段进行正则表达式,提取出微博发送时间、前一天日期。
from datetime import datetime, timedelta# 提取出日期字符串
text = "Mon Jan 15 09:03:10 +0800 2024"
date_split = text.split()
date_str = date_split[5] + " " + date_split[1] + " " + date_split[2] + " " + date_split[3]# 将字符串转换为日期格式
created_date = datetime.strptime(date_str, '%Y %b %d %H:%M:%S')
print(created_date)# 计算客流日期,只保留年月日
traffic_date = (created_date - timedelta(days=1)).date()
print(traffic_date)

对text_raw字段进行正则表达式,提取出每天每条地铁线路的客流数量。
import retext = "#昨日客流# 南京地铁12月31日客运量408.6,其中1号线117.7,2号线102.8,3号线93.6,4号线17.9,7号线13.6,10号线15.2,S1号线13,S3号线8.7,S6号线6.5,S7号线1.9,S8号线13.7,S9号线3.9(以上单位:万)"
# 提取日期
date_pattern = r'\d{1,2}月\d{1,2}日'
date = re.search(date_pattern, text).group()# 提取客运量
traffic_all = re.findall(r"客运量(\d+\.{0,1}\d?)", text)[0]
print(traffic_all)# 提取每条地铁线路的客运量
pattern = r"(S?\d+号线\d+\.{0,1}\d?)"
matches = re.findall(pattern, text)
print(matches)data = {}
for match in matches:line_number = re.findall(r"(S?\d+号线)", match)[0]traffic_volume = re.findall(r"号线(\d+\.{0,1}\d?)", match)[0]data["str_date"] = datedata[line_number] = traffic_volume
print(data)
四、查看异常数据
使用布尔索引筛选出包含空值的行
# 使用布尔索引筛选出包含空值的行
print(traffic_df[traffic_df.isnull().any(axis=1)])
Pycharm 显示 12 月 21 日、6 月 4 日、6 月 5 日、4 月 27 日的行存在空值:
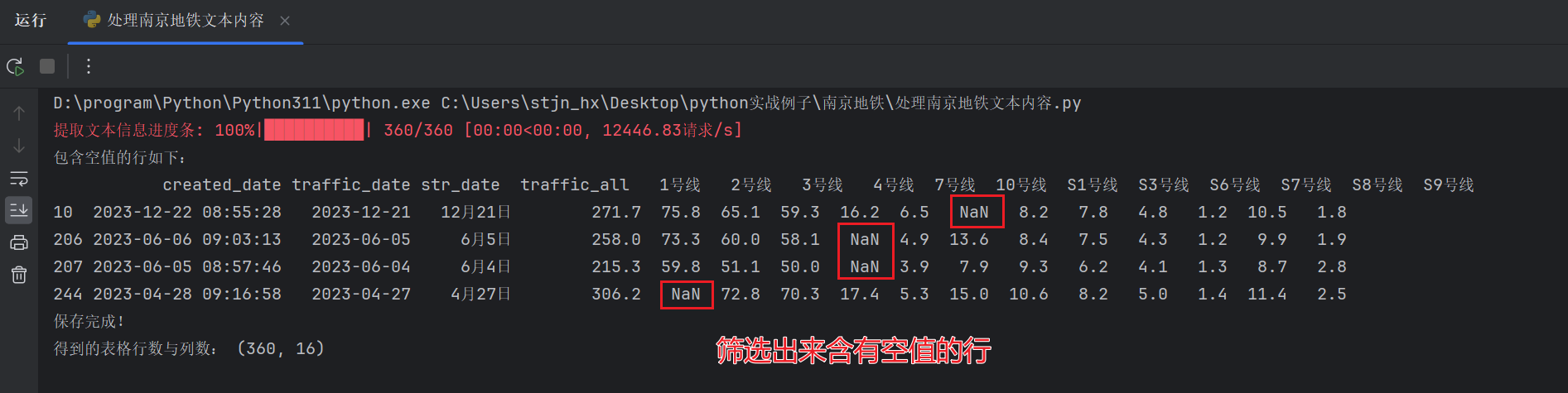
12 月 21 日空值如下:
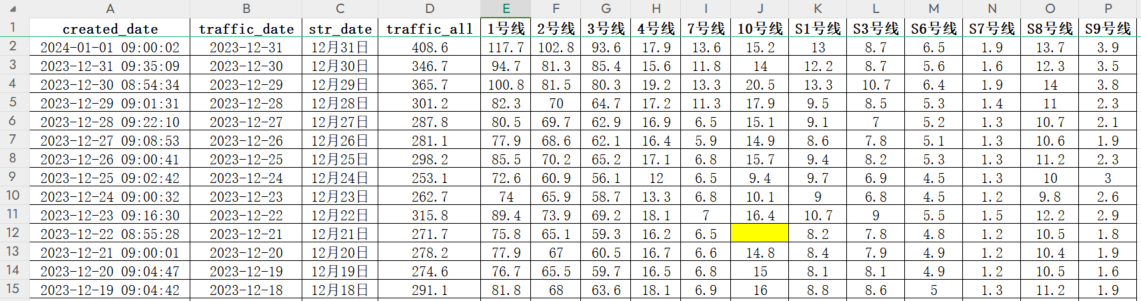
6 月 4 日、6 月 5 日空值如下:
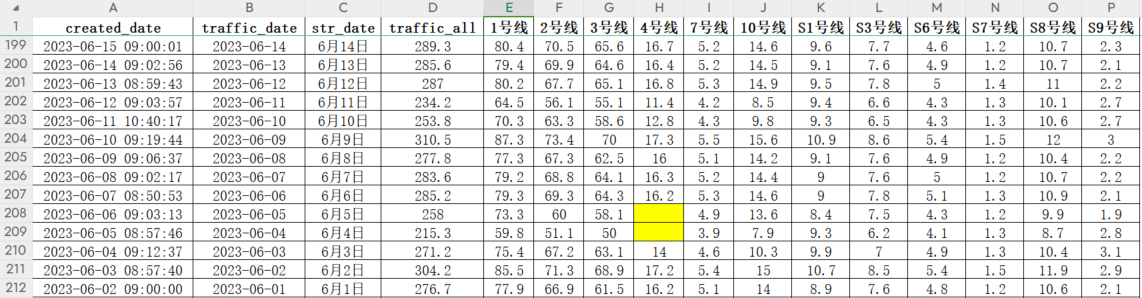
4 月 27 日空值如下:
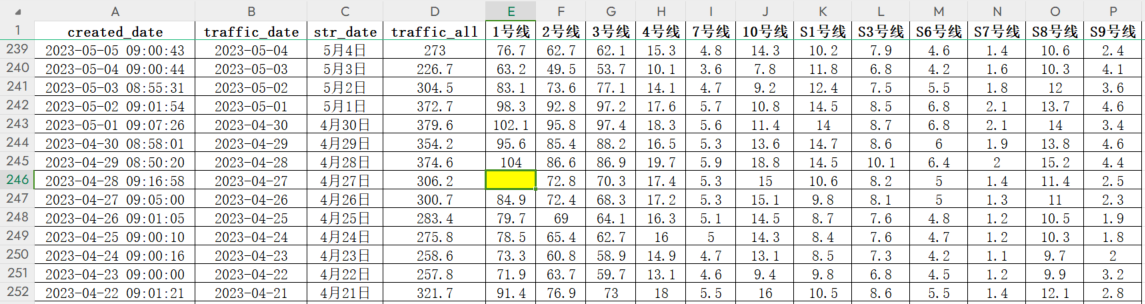
对比原始 excel,可以发现产生空值的原因是人工发微博有细节错误,导致正则表达式没有匹配出数据。

例如“10 号线,14.5”、“4 线 14.9”、“4 线 10.2”、“1 号线,86.3”,这几个字符串由于人工输入错误,没有被正则表达式匹配出来。
五、完整代码
1、爬取数据部分的完整代码:
import requests
import pandas as pdcontent_list = []for page in range(1, 200):headers = {"Cookie": "","User-Agent": ""}data = {"page": page,"uid": "2638276292","q": "昨日客流",}url = f"https://weibo.com/ajax/statuses/searchProfile?"content_json = requests.get(url=url, headers=headers, params=data).json()print("第", page, "页,本页", len(content_json['data']['list']), "条数据", content_json['data']['list'])# df = pd.DataFrame(content_json['data'])if len(content_json['data']['list']) > 0:df = pd.json_normalize(content_json['data']['list'], errors='ignore')df = df.loc[:, ['created_at', 'text_raw']]content_list.append(df)else:break# concat合并Pandas数据
df = pd.concat(content_list)
df.to_excel(f"南京地铁客运量-昨日客流1.xlsx", index=False)
print("保存完成!")# 查看 DataFrame 的行数和列数。
rows = df.shape
print("请求得到的表格行数与列数:", rows)
2、处理数据部分的完整代码:
import re
import pandas as pd
from tqdm import tqdm
from datetime import datetime, timedeltapd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 100)
pd.set_option('display.width', 1000)def extract_info(created_at, text_raw):# 从created_at字段,提取出日期text1 = created_atdate_split = text1.split()date_str = date_split[5] + " " + date_split[1] + " " + date_split[2] + " " + date_split[3]# 将字符串转换为日期格式created_date = datetime.strptime(date_str, '%Y %b %d %H:%M:%S')# 计算客流日期,只保留年月日traffic_date = (created_date - timedelta(days=1)).date()# 从text_raw字段,提取日期、客运量text2 = text_rawdate_pattern = r'\d{1,2}月\d{1,2}日'date = re.search(date_pattern, text2).group()# 提取客运量traffic_all = re.findall(r"客运量(\d+\.{0,1}\d?)", text2)[0]# 提取每条地铁线路的客运量pattern = r"(S?\d+号线\d+\.{0,1}\d?)"matches = re.findall(pattern, text2)# data字典用来存放提取出来的数据data = {}for match in matches:line_number = re.findall(r"(S?\d+号线)", match)[0]traffic_volume = re.findall(r"号线(\d+\.{0,1}\d?)", match)[0]data["created_date"] = created_datedata["traffic_date"] = traffic_datedata["str_date"] = datedata["traffic_all"] = float(traffic_all)data[line_number] = float(traffic_volume)# 提取出来的数据存到traffic_list列表traffic_list.append(data)if __name__ == '__main__':# traffic_list列表存放数据traffic_list = []df = pd.read_excel("./南京地铁客运量-昨日客流.xlsx")# drop_duplicates()函数删除重复行df = df.drop_duplicates()tqdm.pandas(desc='提取文本信息进度条', unit="请求") # tqdm显示进度条df.progress_apply(lambda x: extract_info(x['created_at'], x['text_raw']), axis=1)traffic_df = pd.DataFrame(traffic_list)# 使用布尔索引筛选出包含空值的行print("包含空值的行如下:")print(traffic_df[traffic_df.isnull().any(axis=1)])# 保存为excel表格traffic_df.to_excel(f"南京地铁2023年客运量数据.xlsx", index=False)print("保存完成!")# 查看 DataFrame 的行数和列数。rows = traffic_df.shapeprint("得到的表格行数与列数:", rows)
六、数据可视化
最后,我们还可以使用数据可视化工具(如 Matplotlib、Seaborn、Pyecharts 等)将南京地铁每日客流数据可视化,以便更直观地分析数据。
例如:将每月的客运量进行统计,绘制一个按月份的折线图。
代码如下:
import pandas as pd
import matplotlib.pyplot as plt# 读取Excel文件
df = pd.read_excel('南京地铁2023年客运量数据.xlsx')# # 将traffic_date列转换为日期类型
# df['traffic_date'] = pd.to_datetime(df['traffic_date'])# 计算每月的客运量总量
monthly_traffic = df.groupby(pd.Grouper(key='traffic_date', freq='M'))['traffic_all'].sum().reset_index()# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 绘制折线图
plt.figure(figsize=(12, 6))
plt.plot(monthly_traffic['traffic_date'].dt.strftime('%Y-%m'), monthly_traffic['traffic_all'])
plt.xlabel('月份')
plt.ylabel('月客运量')
plt.title('每月客运量总计')
plt.xticks(rotation=45)
plt.grid()# 在图上标记每个月的客运量数字
for i, row in monthly_traffic.iterrows():plt.annotate(f"{row['traffic_all']:.0f}",(row['traffic_date'].strftime('%Y-%m'), row['traffic_all']),xytext=(10, 10),textcoords='offset points',ha='left',va='bottom',fontsize=12)plt.show()
生成的折线图如下:
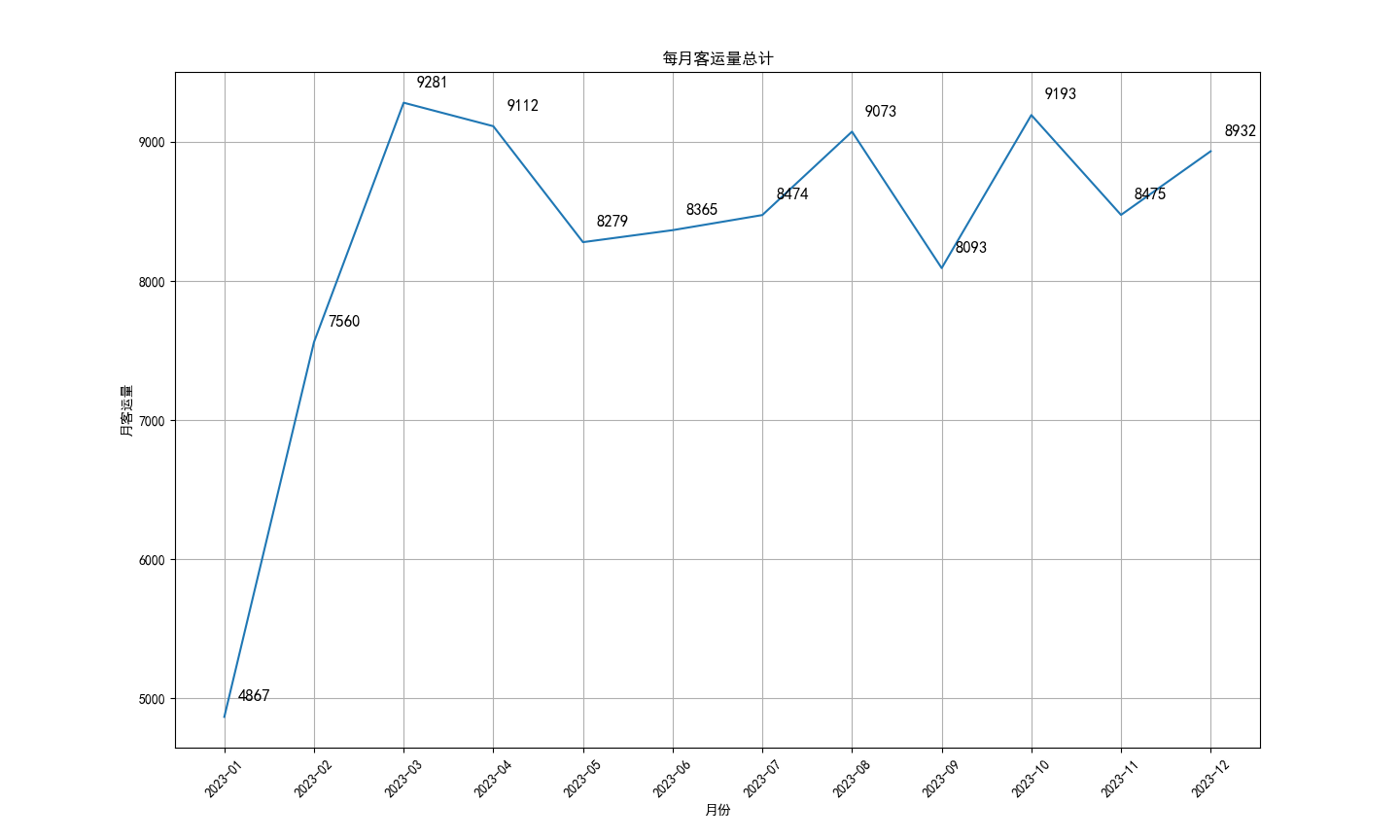
可以看到 2023 年 1 月份和 2 月份客运量明显偏低,当时疫情对出行还是产生较大影响。受后续相关政策调整后,客运量数据从 2 月份开始才逐渐恢复正常水平。
由于数据可视化不是本篇文章重点,就不展开写了,可以移步参考之前写过的几篇数据可视化的文章。
七、总结
在这篇文章中,我们使用 Python 进行网络爬虫,爬取了微博上的南京地铁每日客流数据,并且进行了数据处理和数据可视化。
爬取数据环节较为简单,多看几篇我之前发的文章,都可以轻松写出来爬虫部分的代码。
由于微博是由地铁公司的工作人员每天人工编辑发送的,其中不免有数据格式不完全一致,这给数据处理环节增加了复杂度。
本文首发在“程序员coding”公众号,欢迎关注与我一起交流学习。
本文数据集已经上传到公众号,后台回复“南京地铁”可以自取。
这篇关于Python实战:爬取微博,获取南京地铁每日客流数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







