本文主要是介绍深入浅出 diffusion(5):理解 Latent Diffusion Models(LDMs),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果你了解 diffusion 原理的话,那么理解 Latent Diffusion Models 的原理就比较容易。论文High-Resolution Image Synthesis with Latent Diffusion Models(Latent Diffusion Models)发表于CVPR2022,第一作者是Robin Rombach(慕尼黑大学)。
1. LDM 优势
论文特点在于:
- Diffusion model 训练和推理代价都很高。通过在潜在表示空间(latent space)上进行 diffusion 过程的方法,从而能够大大减少计算复杂度并达到较好的效果。
- 可以生成更细致的图像,并且在高分辨率图片生成任务(如风景图生成,百万像素图像)上表现得也很好。
- 模型在无条件图片生成(unconditional image synthesis), 图片修复(inpainting),图片超分(super-resolution)任务上进行了实验,都取得了不错的效果。
- 论文还提出了cross-attention的方法来实现多模态训练,使得条件图片生成任务也可以实现。论文中提到的条件图片生成任务包括类别条件图片生成(class-condition), 文图生成(text-to-image), 布局条件图片生成(layout-to-image)。
2. LDM 原理
LDM 的网络示意图如下所示。
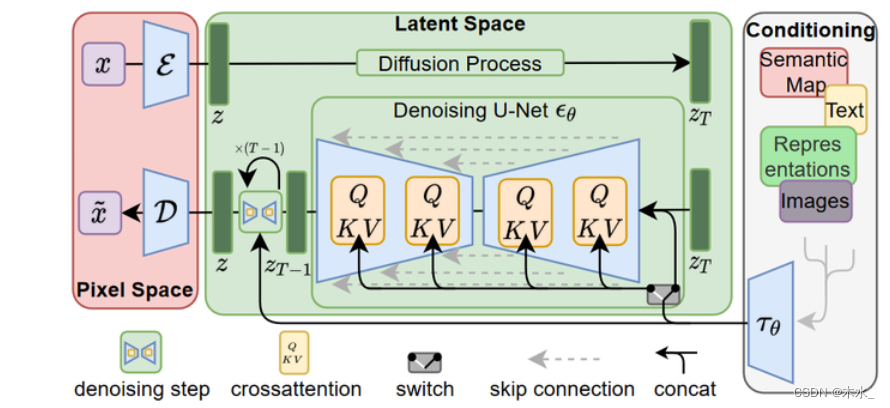
2.1 图片感知压缩
图片感知压缩(Perceptual Image Compression)特点如下:
- 目的
- 给定一个RGB空间内的图像x,编码器把x编成潜空间的z,解码器从潜空间把z解码回
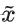 。
。 - 训练 loss
- KL 正则和 VQ 正则。实验结果显示虽然FID指标上 VQ 比 KL 稍微好一点点,VQ分数是14.99,KL分数是15.21(FID越低越好),但是VQ的视觉效果要比KL好很多。
2.2 潜在扩散模型
潜在扩散模型中,引入了预训练的感知压缩模型,它包括一个编码器 ![]() 和一个解码器
和一个解码器 ![]() 。这样就可以利用在训练时就可以利用编码器得到
。这样就可以利用在训练时就可以利用编码器得到 ![]() ,从而让模型在潜在表示空间中学习。
,从而让模型在潜在表示空间中学习。
下式为 DM 的目标函数:

下式为 LDM 的目标函数:
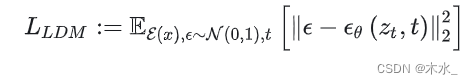
2.3 条件机制
条件机制(Conditioning Mechanisms)本质在于通过交叉注意机制增强其底层 UNet 主干,将 DM 转变为更灵活的条件图像生成器,这让基于attention的模型学习多种输入模态更有效了。
Attention 计算公式如下:
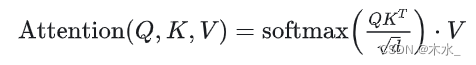
其中:
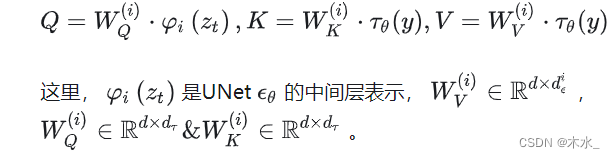
3 训练与推理
3.1 训练
训练过程分两步:
- 第一步,训练一个VAE(下图中横的虚线框),得到x到 zt 的编码器 Encoder 和还原回 x′ 的解码器 Decoder;
- 第二步,训练一个扩散模型LDM,学习一个噪声到 zt 的生成过程。其中LDM的架构是个Unet(如果包含条件输入的话,则条件信息的编码器与LDM一起训练)。
3.2 推理
推理过程分为无条件信息和有条件信息两种情况:
没有条件信息:
- 从高斯噪声采样,经过LDM模型,得到潜空间图像zt;
- zt经过 Decoder 模型还原到原图。
有条件信息
- 从高斯噪声采样
- 条件信息经过条件处理的编码器得到的输出与初始高斯噪声以及u-net进行耦合(concat,attention),经过LDM得到潜在空间图像zt
- zt经过 Decoder 模型还原到原图。
这篇关于深入浅出 diffusion(5):理解 Latent Diffusion Models(LDMs)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








