本文主要是介绍双目立体视觉中基于深度学习的Cost Volume浅析(difference方式),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
对于双目立体视觉方向的初学者来说,基于传统方法的Cost Volume构建比较容易懂,但是基于深度学习的Cost Volume构建却和传统方法构建大为不同,严重困扰“小白”的学习兴趣和进程。今天,我将用一个简单的例子,通俗易懂的介绍基于深度学习的Cost Volume浅析(以difference方式构建),仅供参考,如有差错,欢迎留言,以便勘误,共同进步。
双目立体视觉中基于深度学习的Cost Volume(difference方式)的参考代码如下:
'''
参考:https://zhuanlan.zhihu.com/p/293304108
'''
import torch
max_disp = 2# 1.提取特征图
left_feature = torch.ones(48).reshape(1,3,4,4)
right_feature = torch.zeros(48).reshape(1,3,4,4)
print("left_feature:", left_feature.shape)
print("right_feature:", right_feature.shape)
print("left_feature:\n", left_feature)
print("right_feature:\n", right_feature)
print("---------------------------------------------------------------")# 2.特征融合
class CostVolume():def __init__(self):pass'''feature_similarity:聚合方式left_feature:左特征图right_feature:右特征图'''def forward(self, feature_similarity, left_feature, right_feature):b, c, h, w = left_feature.size()self.max_disp = max_dispself.feature_similarity = feature_similaritycost_volume = left_feature.new_zeros(b, c, self.max_disp, h, w)print("original_cost_volume shape:", cost_volume.shape)print("original_cost_volume value:", cost_volume)for i in range(self.max_disp):if i > 0:print("********************************************************")print("left_feature[:, :, :, i:](i > 0 == i = 1):\n", left_feature[:, :, :, i:])print("right_feature[:, :, :, :-i](i > 0 == i = 1)):\n", right_feature[:, :, :, :-i])cost_volume[:, :, i, :, i:] = left_feature[:, :, :, i:] - right_feature[:, :, :, :-i]print("cost_volume[:, :, i, :, i:](i > 0 == i = 1):\n", cost_volume[:, :, i, :, i:])print("final cost_volume:\n", cost_volume)else:cost_volume[:, :, i, :, :] = left_feature - right_feature # i=0,表示左右两个特征图视差为0,没有差值,直接相减即可print("cost_volume[:, :, i, :, :] (i=0):\n", cost_volume)if __name__== "__main__" :cost_volume = CostVolume()cost_volume.forward("difference", left_feature, right_feature)
(1)left_feature和right_feature的数据格式如下:
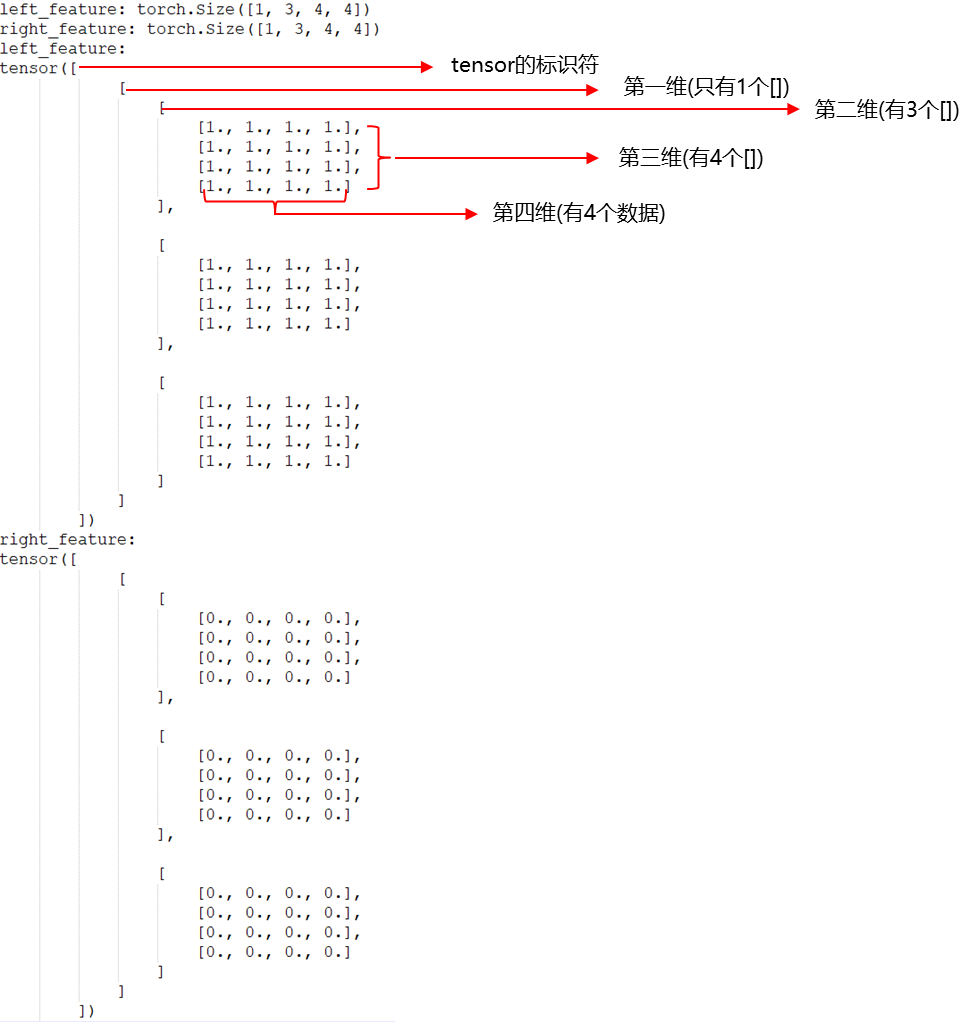
(2)原始定义的cost volume数据格式如下:

(3)当i=0时,cost volume数据格式如下:

(4)当i>0时,cost volume数据格式如下:

(5)最终的cost volume数据格式如下:
分析:对比最开始的cost volume、i=0的cost volume和最终的cost volume的区别:

在基于深度学习的双目立体视觉中,Cost Volume是一个5维数组([B,C,D,H,W]),其中B代表Batch size,C代表Channel,D代表深度Depth ,H代表特征图的高度Hight,W代表特征图的宽度Wight。暂时抛开Batch size B,那么Cost Volume就是一个4维数组([C,D,H,W]),可以表述为:在每个通道C中,每个视差D下,每个像素点的匹配代价值。
在以difference的方式进行双目匹配中。输入左右视图的特征图维度为B C H W。首先,对D(max disparity)维度进行遍历,cost volume(:, :, i, :, i:)可以理解为视差为i时,左右视图的相似度。
对于双目图像对来说,左右视图之间的存在视差,左右视图只有一部分是重合的,重合部分在左图的右边,右图的左边。因此在计算的时候,取左特征图的第i列到最后一列与右特征图的第一列到倒数第i列相减。cost volume(:,:,i,:,:)每个像素表示视差为i时,左图(x,y)像素与右图(x, y+i)像素的差异程度。输出的cost volume维度为B C D H W。
i=0,表示左右特征图中匹配点对齐,即直接left_feature和right_feature相减;
i>0, 表示左右特征图中匹配点没有对齐,这个时候就需要左右特征图错开,以视差为标准,进行左右特征图的错位相减。
cost_volume[:, :, i, :, i:] = left_feature[:, :, :, i:] - right_feature[:, :, :, :-i]从代码中还可以看到,在计算cost volume之前,判断i为否为正数。i为正表示,左图在右图左边,右图在左图右边,只有这时才符合正常的双目视图的几何模型。
模型图如下所示:
参考文献:
[1] 计算机视觉中cost-volume的概念具体指什么? - 知乎
[2]双目深度算法——基于Cost Volume的方法(GC-Net / PSM-Net / GA-Net)_Leo-Peng的博客-CSDN博客_gc-net
[3]在计算机视觉(CV)领域,针对图像的cost volume模块是什么? - 知乎
[4]https://zhidao.baidu.com/question/1741015413026869187.html
[5]Cost volume的理解及其变体 - 知乎
这篇关于双目立体视觉中基于深度学习的Cost Volume浅析(difference方式)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








