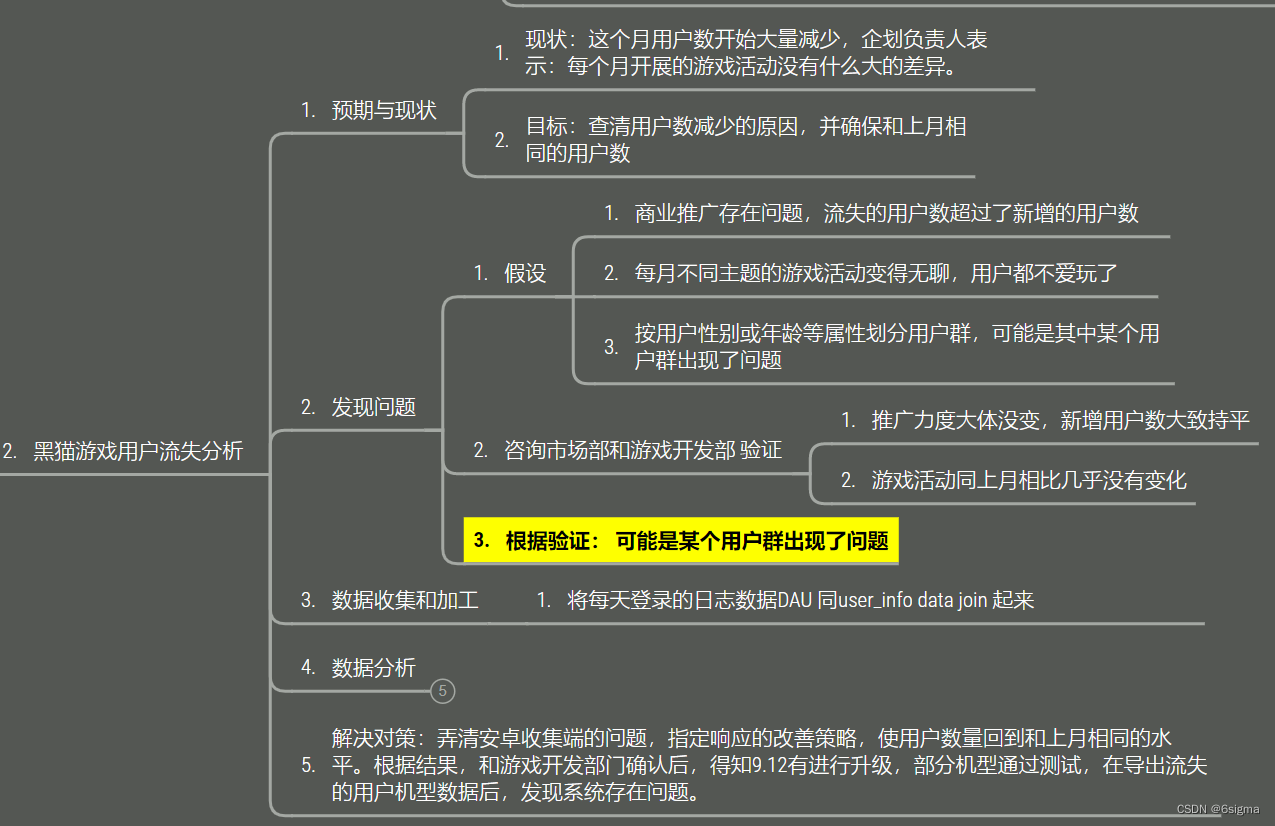
本文主要是介绍Python 数据分析实战——社交游戏的用户流失?酒卷隆治_案例2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
# 什么样的顾客会选择离开
# 数据集
DAU : 每天至少来访问一次的用户数据
数据内容 数据类型 字段名
访问时间 string(字符串) log_data
应用名称 string(字符串) app_name
用户 ID int(数值) user_id
USER_INFO:用户属性数据
数据内容 数据类型 字段名
首次使用日期 string(字符串) install_data
应用名称 string(字符串) app_name
用户 ID int(数值) user_id
性别(女性、男性) string(字符串) gender
年龄段(10、20、30、40、50) int(数值) generation
设备类型(iOS、Android) string(字符串) device_type
# 加载模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] # 用来显示中文# 导入数据
DAU = pd.read_csv("D:/data/datasource/数据分析实战_酒卷隆治/R/section4-dau.csv")
USER_INFO = pd.read_csv("D:/data/datasource/数据分析实战_酒卷隆治/R/section4-user_info.csv")# merge data
data = pd.merge(DAU,USER_INFO,on='user_id',how='left')
data['log_mon'] = data.log_date.apply(lambda x: pd.to_datetime(x).strftime('%Y-%m'))
data.head(10)# 数据分析
# 用户群分析(性别)
df_gender = pd.pivot_table(data,values='user_id',index = 'log_mon',columns='gender',aggfunc='count').reset_index()
df_gender['prop_f'] = df_gender['F']/(df_gender['F']+df_gender['M'])
df_gender['prop_m'] = df_gender['M']/(df_gender['F']+df_gender['M'])
df_gender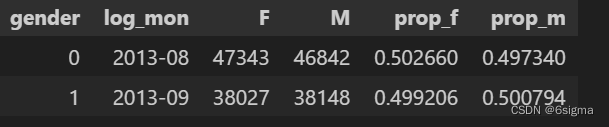
# 根据上述数据,可以发现9月份的整体数据下降,但是男女比例的构成几乎没有变。
# 由此可以判断性别属性对用户数量下降的影响很小。
# 用户群分析(年龄)
age_min = data['generation'].min()
age_max = data['generation'].max()
# print(age_min, age_max)
# 将年龄进行分组
data['age_group'] =pd.cut(data.generation,bins=[age_min-1,19,29,39,49,59],labels=['10~19','20~29','30~39','40~49','50~59']) df_age = pd.pivot_table(data,values='user_id',index = 'log_mon',columns='age_group',aggfunc='count').reset_index()
# print(df_age.columns)
# 计算不同age_group 占比
for i in df_age.columns:if i != 'log_mon':var = i+'_prop'df_age[var] = df_age[i]/(df_age['10~19']+df_age['20~29']+df_age['30~39']+df_age['40~49']+df_age['50~59'])df_age[['10~19_prop','20~29_prop','30~39_prop','40~49_prop','50~59_prop']] 
# 通过比较不同年龄段的占比,发现不同年龄群的用户在月总数据中的占比没有发生大的变化,说明年龄属性对用户的下降影响很小。
# 用户群分析(性别*年龄)
df_mix = pd.pivot_table(data,values='user_id',index = 'log_mon',columns=['gender','age_group'],aggfunc='count')
df_mix
# 通过将性别于年龄进行交叉组合,发现每个用户群所占的比例大体没变。
# 用户群分析(设备类型)
df_device = pd.pivot_table(data,values='user_id',index='log_mon',columns='device_type',aggfunc='count').reset_index()
df_device
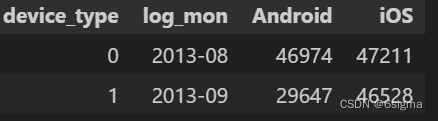
# 发现IOS设备的用户数略有下降,而Android 的用户却大量减少。
# 再进一步的通过时间序列图确认用户数变化的程度from datetime import datetime
import matplotlib
from matplotlib import dates as mdates fig = plt.figure(figsize=(10,4)) # 设置画布大小
# 生成可视化数据
df = pd.pivot_table(data,values='user_id',index='log_date',columns='device_type',aggfunc='count').reset_index()
df['log_date'] = df.log_date.apply(lambda x:pd.to_datetime(x))# 画图
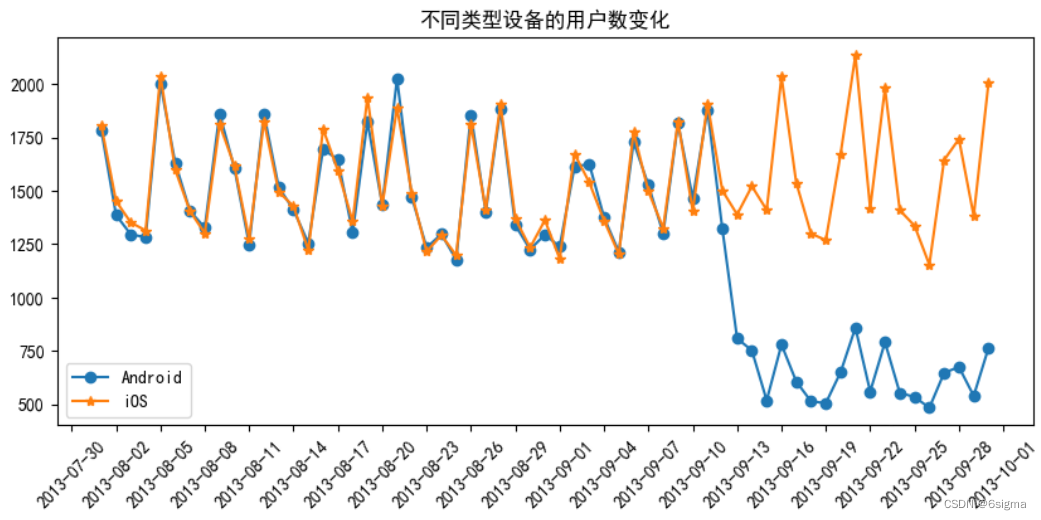
plt.plot(df.log_date, df.Android,marker='o',label='Android')
plt.plot(df.log_date,df.iOS,marker='*',label='iOS')plt.legend()
plt.title('不同类型设备的用户数变化')
# 设置坐标轴
plt.xticks(df.log_date , rotation=45)
plt.gca().xaxis.set_major_formatter(matplotlib.dates.DateFormatter('%Y-%m-%d')) # 设置显示格式
plt.gca().xaxis.set_major_locator(mdates.DayLocator(interval=3)) # 日期间隔
解决对策
# 从图可知,iOS设备的用户数和之前的大体相同,再一个区间内震荡。
# 但安卓用户数2013-09第二周开始急剧减少。经与开发部门确认,9月12号有一次设备升级,部分机型通过测试。在导出流失的用户机型数据后,发现系统版本存在问题,在修复系统后用户数据恢复正常。
这篇关于Python 数据分析实战——社交游戏的用户流失?酒卷隆治_案例2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





