本文主要是介绍AI Agents系列—— 探究大模型的推理能力,关于Chain-of-Thought的那些事儿,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、写在前面:关于AI Agents与CoT
本文是2023.07.24发表在同名公众号「陌北有棵树」上的一篇文章,个人观点是基础理论的学习现在仍是有必要的,所以搬运过来。
今天要读的论文是《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》,算是关于大模型思维链研究的开山之作。
至于为什么把它归到AI Agents系列,其实我最开始是在写一篇关于AI Agents的文章,但是写着写着发现里面的细节太多,如果只用一篇总结式的文章来写的话,有些浅尝辄止,所以决定拆开来一步步完成。我先跑个题说说AI Agents…
关于大家最近都不卷大模型了,开始卷AI Agents这件事儿,我的理解是这样的:在LLM诞生之初,大家对于其能力的边界还没有清晰的认知,以为有了LLM就可以直通AGI了,所以当时大家以为的路线是这样:

但是,过了一段时间,大家发现,LLM的既有问题(比如幻觉问题、容量限制问题…),导致它并不能直接到达AGI,于是路线变成了如下图,我们需要借助一个或者多个Agent,构建一个新的形态,来继续实现通往AGI的道路。但这条路是否能走通,以及还面临着哪些问题,都是有待进一步验证的。
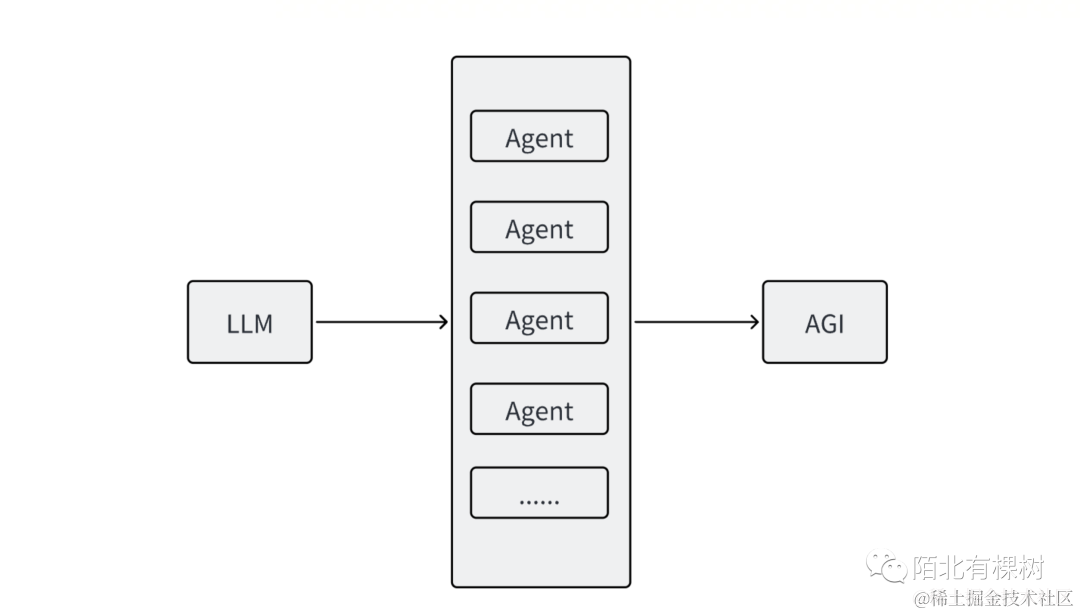
关于AI Agents这个概念也不是最近才出现,只是由于大模型的出现,衍生出了一种新的架构形式。OpenAI的应用主管写了一篇博文,详细介绍了这个架构,并将其命名为“LLM Powered Autonomous Agents”,这种基于大模型能力的自动化智能体的主要组成部分如下:

仔细地仔细的阅读了《LLM Powered Autonomous Agents》这篇文章之后,整理了一份思维导图(为了便于展示折叠了部分内容),该架构将LLM类比为大脑一样的角色,结合Memory、Tools组件,构成该体系的全貌。

在这套框架里,将最重要的「任务规划」部分完全交由LLM,而做出这一设计的依据在于默认LLM具有任务分解和反思的能力。对于任务分解,就不得不说到「思维链(CoT,Chain of thought)」和「思维树(Tree of Thoughts)」:思维链是通过提示模型“逐步思考”,以利用更多的测试时间计算将困难任务分解为更小,更简单的步骤。思维树首先将问题分解为多个思考步骤,并且每个步骤都生成多个想法,从而可以创建一个树形结构。
但无论是任务分解还是反思,目前都是在「LLM具有逻辑推理能力」这个预设上面的,基于此我们才将大脑所承担的功能交给LLM。其实说白了就都还是Prompt工程,也就是如何通过Prompt来激发LLM的任务分解能力和反思能力。而思维链和思维树,当前也还是既不能证实也不能证伪的阶段。与此同时,这种架构设计下,LLM的能力上限也就约等于AI Agents的上限。
所以我暂时把感兴趣的Generative Agents、Auto-GPT放到一边,先对思维链种草了…
二、CoT的概念和解释
先举个栗子来说明CoT Prompting,下图的左右分别是一个标准Prompting和 CoT Prompting来处理推理任务的代表。
对于标准Prompting,首先这是一个少样本学习的方法,需要给出一些问题和答案的样例,然后拼接想要求解的问题,最后再拼接一个字符串“A:”之后输入到大语言模型中,让大语言模型进行续写。大语言模型会在所提供的问题和答案的样例中学习如何求解,结果发现很容易出错 。
对于CoT Prompting,它与 Standard prompting 唯一的区别就是,CoT 在样例中在给出问题的同时,不仅给出了答案,在答案之前还给出了人为写的中间推理步骤。在把问题、中间推理步骤和答案的若干样例拼接上所想要求解的问题和字符串“A”,再输入到语言模型之后,语言模型会自动地先续写中间推理步骤,有了这些推理步骤之后,它就会更容易地给出正确答案。

论文中对于CoT(Chain of thought)的定义如下:在处理推理任务时,给出答案之前产生的一系列连贯的中间推理步骤。
如果简单点概括本文的内容,一句话就是:在问LLM问题前,手工在prompt里面加入一些包含思维过程(Chain of thought)的问答示例,就可以让LLM在推理任务上大幅提升。
然后作者介绍了COT几个值得研究的地方:
1、COT在原则上能够让模型把一个多步问题可以分解出多个中间步骤,就可以使那些需要更多推理步骤的问题,就有机会分配到更多的计算量。
这个怎么理解呢?因为语言模型在生成下一句的时候是token by token,假设你的问题越难,COT又使得你生成的中间步骤够多,那么总体上生成的token就会越多,自然在解决更难问题时,就可以用到更多的计算量。
类比我们人脑,在解决更难问题时会消耗更多的脑力,COT也可以让LLM在解决更难的问题时,消耗更多的计算资源。
2、COT提供了可解释性,也就是通过COT,可以不仅仅知道答案,也可以知道答案是怎么来的。
3、COT在原则上适用于任何人类能用语言所解的问题,不只是数学、逻辑、推理问题。
4、当一个语言模型训练好后,就可以像比如few-shot prompting这种范式,在每个样例中写入中间推理步骤,再跟上要解的问题,丢给语言模型,就能够引发语言模型帮你续写出中间的推理步骤。
三、论文中实验结果
论文中实验主要分为三类:Arithmetic Reasoning(算数推理)、Commonsense Reasoning(常识推理)、Symbolic Reasoning(符号推理),这里先用一张图列出这三类实验用到的所有例子(绿色的是算数推理、橙色的是常识推理,蓝色的是符号推理)

3.1 关于算数推理
作者人工设计了一套 8 个带有 CoT 推理链条的 few-shot 样例,并且在所有数据集中统一使用了这 8 个带有 CoT 推理链条的 few-shot 样例,在这里,所有的样例都是人工构造,同时人工构造 CoT 推理链条的 few-shot 样例的成本是很高的,不仅要找到具有代表性的问题,还要为每个问题设计中间推理步骤以及答案,而最后的性能对这些人工设计非常敏感,所以需要反复进行调试。
实验结果如下:

由实验结果可得到如下结论:
1、 CoT Prompting对于小模型的效果并不明显,只在大于100B参数的模型中才产生了优于 Standard Prompting的效果。
2、 CoT Prompting对于复杂问题的效果更明显,实验中用了三个数据集,其中GSM8K是最复杂的,从实验结果上也是它相对于Standard Prompting提升的效果大于1倍。
3、GPT-3 175B 和 PaLM 540B 结合CoT Prompting的效果是提升最高的。
3.2 关于常识推理和符号推理
其实这里和前面算数推理的结论大差不差,也就不细说了,常识推理作者选取了5种涵盖各种常识推理类型的数据集(需要先验知识的常识性问题、需要模型推断的multi-hop strategy问题、日期理解、体育问题理解、自然语言映射);符号推理作者选取了两个问题:末位字母连接、抛硬币。下面两张图分别是常识推理和符号推理的实验结果:
常识推理实验结果

符号推理实验结果

四、局限性分析
在论文的Discussion部分,作者讨论了CoT当前的局限性,主要有以下4点:
1、虽然CoT模拟了人类推理的思维过程,但是仍然不能确认神经网络是否真的在“推理”,这仍是个尚未解决的问题。
2、手动生成CoT样例的成本问题。
3、无法保证正确的推理路径。
4、CoT仅仅能在大模型上出现。
五、番外:Zero-shot CoT 和 Auto-CoT
在读这篇论文时,还看到了关于CoT的其他研究,比较有代表性的有两个:
5.1 Zero-shot CoT
Zero-shot CoT来自论文《Large language models are zero-shot reasoners. NeurIPS2022》,这篇文章发现:大模型可能不需要写一堆CoT来作为prompt,它自己可能就会推理了,秘诀就是加上一句咒语:“Let’s think step by step.”
通过实验发现,Zero-shot CoT还是可以显著提升LLM的数学推理能力的。虽然Zero-shot CoT和Few-shot CoT都会犯错,但是犯错误时的特点很不一样:Zero-shot方法在推出正确答案后,可能会继续“画蛇添足”,导致最终错误;另外,Zero-shot有时候干脆不推理,直接重复题目。Few-shot方法则是在生成的推理过程中包含三元运算的时候很容易出错,例如(3+2)*4。另外Zero-shot CoT在常识推理问题上的提升不大。
总体上,Few-shot CoT的效果还是比Zero-shot CoT更好的。
5.2 Auto-CoT
通过上面的介绍我们知道,Zero-shot CoT没有使用 In-Context-Learning,Few-shot CoT使用了 In-Context-Learning。ICL 提供了LLM更多的示范信息,可能能让LLM在输出的时候更加规范。
那是不是可以先通过 Zero-shot CoT 来让 LLM 产生很多带有推理的QA pair,然后把这些QA pair加入到prompt中,构成ICL的上文,再让LLM进行推理。
于是有了《Automatic Chain of Thought Prompting in Large Language Models》这篇论文的基本思路:
1、给定待测试的问题,从无标注问题集合中,采样一批问题;
2、使用 GPT-3 作为产生推理过程的工具,即直接使用 “Let’s think step by step.” 咒语,来对这一批采样的问题产生推理过程;
3、把产生的这些问题和推理过程,构成In-Context-Learning的上文加入到prompt中,再让LLM对问题进行回答。
对比实验结果如下:
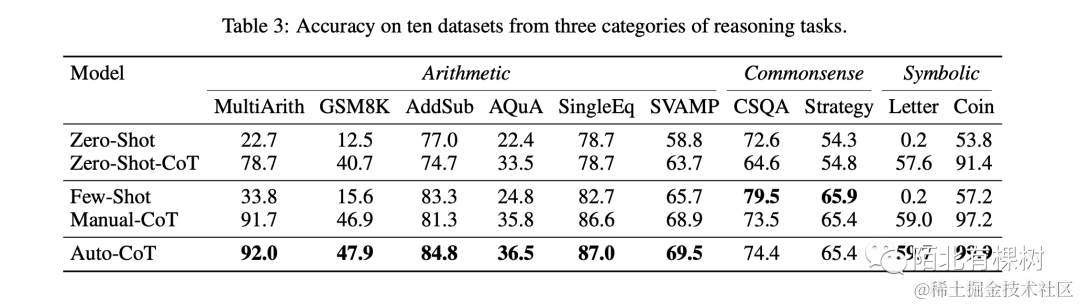
基于这个结果来看,Auto-CoT的效果是略优于Few-shot CoT的,如果再结合其省去的人工成本,就不得不说一句真香了…
但目前CoT在上文中提到的局限性,基本还都在,尤其是其作为「大模型有推理能力」的依据仍然不足,而LLM的推理能力又是其作为基于LLM的AI Agents架构的基础假设,所以仍然还需要进一步研究。
这篇关于AI Agents系列—— 探究大模型的推理能力,关于Chain-of-Thought的那些事儿的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







