本文主要是介绍基于fasttext与langid文本语种识别的python代码实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上期文章,我们分享了OpenAI开源的能识别99种语言的语音识别系统——whisper。
Whisper 是一种自动语音识别模型,基于从网络上收集的 680,000 小时多语言数据进行训练。根据 OpenAI的介绍,该模型对口音、背景噪音和技术语言具有很好的鲁棒性。此外,它还支持 99 种不同语言的转录和从这些语言到英语的翻译。
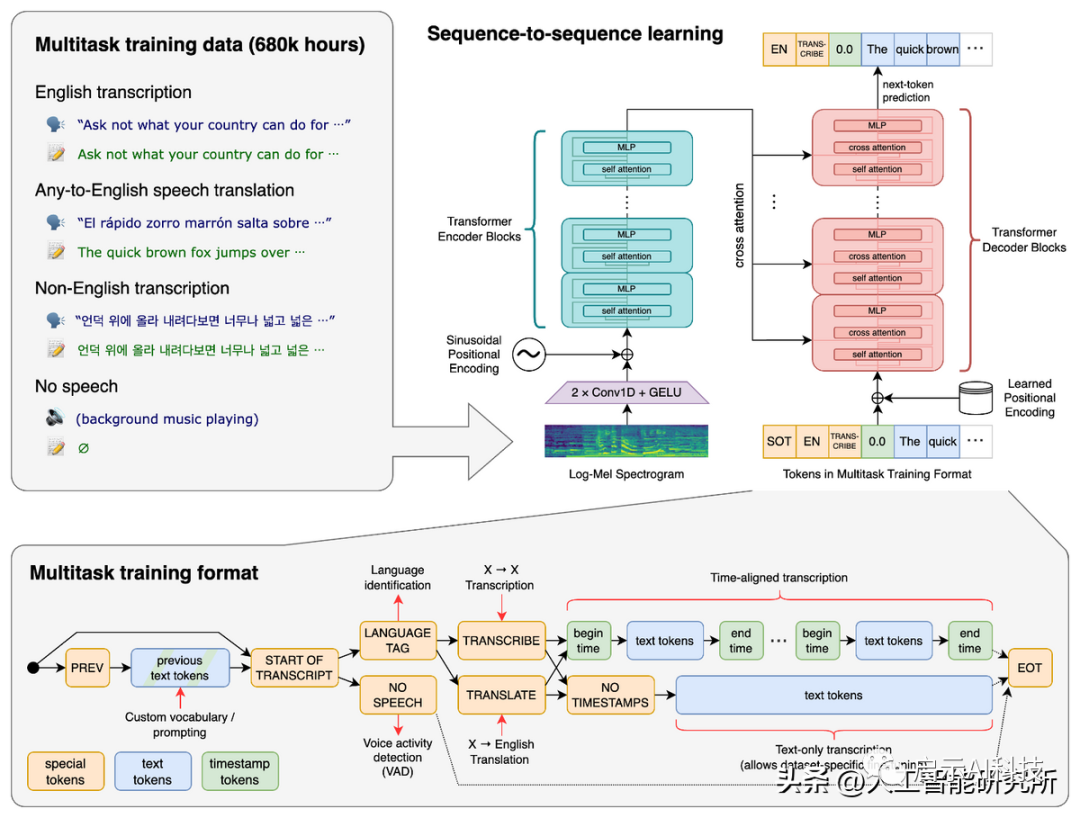
whisper语音识别系统
虽然Open AI开源的whisper语音识别系统,可以识别出不同的语音,且同样可以识别出语音的语种,但是whisper主要应用在语音识别系统上面,且我们运行whisper系统需要大型的模型。当我们仅仅来识别不同的语言文字,且要识别出语言文字的语种时,我们可以使用小型的模型来识别,比如langid,fasttext等等。
langid文本语种识别
在Facebook发布fasttext之前,比较著名的语种识别库是langid,langid是一个小型的语种识别库,其模型只有2.5MB的大小,精度已经达到了91.3以上,虽然模型较小,但是功能确实是比较强大,且可以支持97种的文本语种检测。
使用langid十分简单,我们只需要使用如下代码安装使用即可
pip install langid
langid第一步首先是使用pip安装langid即可
这篇关于基于fasttext与langid文本语种识别的python代码实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







