fasttext专题

NLP-词向量-发展:词袋模型【onehot、tf-idf】 -> 主题模型【LSA、LDA】 -> 词向量静态表征【Word2vec、GloVe、FastText】 -> 词向量动态表征【Bert】
NLP-词向量-发展: 词袋模型【onehot、tf-idf】主题模型【LSA、LDA】基于词向量的静态表征【Word2vec、GloVe、FastText】基于词向量的动态表征【Bert】 一、词袋模型(Bag-Of-Words) 1、One-Hot 词向量的维数为整个词汇表的长度,对于每个词,将其对应词汇表中的位置置为1,其余维度都置为0。 缺点是: 维度非常高,编码过于稀疏,易出

机器学习第六篇----FastText实践
最近在做对话机器人,使用了调研之后使用了fasttext,主要考虑对话机器人主要是短文本,而且与基于神经网络的文本分类算法相比它主要由两个优点 (1)首先FastText在保持高精度的同时极大地加快了训练速度和测试速度。 (2)再有就是不需要使用预先训练好的词向量,因为FastText会自己训练词向量 1.fasttext 安装: pip install fasttext 2.fastte

Word2Vec、GloVe、Fasttext等背后的思想简介
超长文, 建议收藏之后慢慢观看~ 1Efficient Estimation of Word Representations in Vector Space 本文是 word2vec 的第一篇, 提出了大名鼎鼎的 CBOW 和 Skip-gram 两大模型. 由于成文较早, 本文使用的一些术语有一些不同于现在的叫法, 我都替换为了现在的叫法. CBOW 的架构如下所示. 与作者提到的 feedfo
无法import fastText
https://github.com/facebookresearch/fastText/issues/474#issuecomment-445430211
FastText词嵌入的可视化指南
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Amit Chaudhary 编译:ronghuaiyang 导读 非常清楚的解释了FastText的来龙去脉。 单词嵌入是自然语言处理领域中最有趣的方面之一。当我第一次接触到它们时,对一堆文本进行无监督训练的简单方法产生了显示出语法和语义理解迹象的表示,这很有趣。 在这篇文章中,我们将探索由Bojanowski等人介绍的

fastText训练157种语言的词向量
公众号 系统之神与我同在 http://link.zhihu.com/?target=https%3A//github.com/facebookresearch/fastText/blob/master/docs/crawl-vectors.md 有了这个词向量,很多常见的小语种NLP任务都能够做。
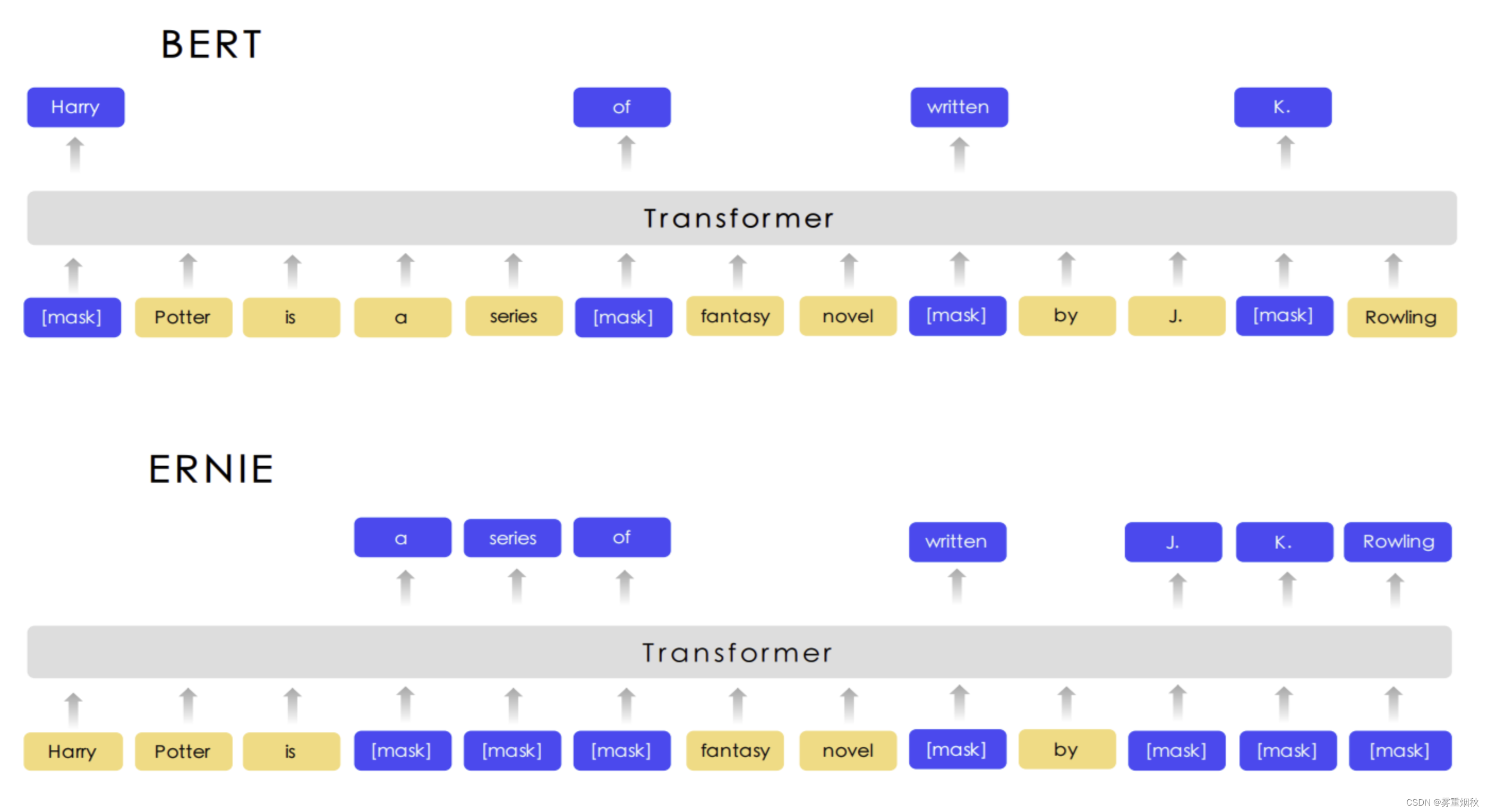
NLP实战入门——文本分类任务(TextRNN,TextCNN,TextRNN_Att,TextRCNN,FastText,DPCNN,BERT,ERNIE)
本文参考自https://github.com/649453932/Chinese-Text-Classification-Pytorch?tab=readme-ov-file,https://github.com/leerumor/nlp_tutorial?tab=readme-ov-file,https://zhuanlan.zhihu.com/p/73176084,是为了进行NLP的一些典型
fasttext源码学习(2)--模型压缩
fasttext源码学习(2)–模型压缩 前言 fasttext模型压缩的很明显,精度却降低不多,其网站上提供的语种识别模型,压缩前后的对比就是例证,压缩前126M,压缩后917K。太震惊了,必须学习一下。看文档介绍用到权重量化(weight quantization)和特征选择(feature selection),下面结合代码学习下。 说明:文章中代码皆为简化版,为突出重点,简化了逻辑,

fasttext源码学习(1)--dictionary
fasttext源码学习(1)–dictionary 前言 fasttext在文本分类方面很厉害,精度高,速度快,模型小(压缩后),总之非常值得学习。花了点时间学习了下源码,本篇主要是与dictionary相关。 dictionary主要存储词语和切分词及对应的id,因为fasttext能处理超大数据集,如果不使用一些方法,只是加载这些内容,内存就很容易爆掉,我们来看看有哪些关键方法。 一

文本处理——fastText原理及实践(四)
博文地址:https://zhuanlan.zhihu.com/p/32965521 fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新。但是它的优点也非常明显,在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CPU上, 能够训练10亿词级别语料库的词向量在
fastText-文本分类
fastText介绍 fastText是一个快速文本分类算法,与基于神经网络的分类算法相比有两大优点: 1、fastText在保持高精度的情况下加快了训练速度和测试速度 2、fastText不需要预训练好的词向量,fastText会自己训练词向量 3、fastText两个重要的优化:Hierarchical Softmax、N-gram fastText结合了自然语言处理和机器学习中最成功
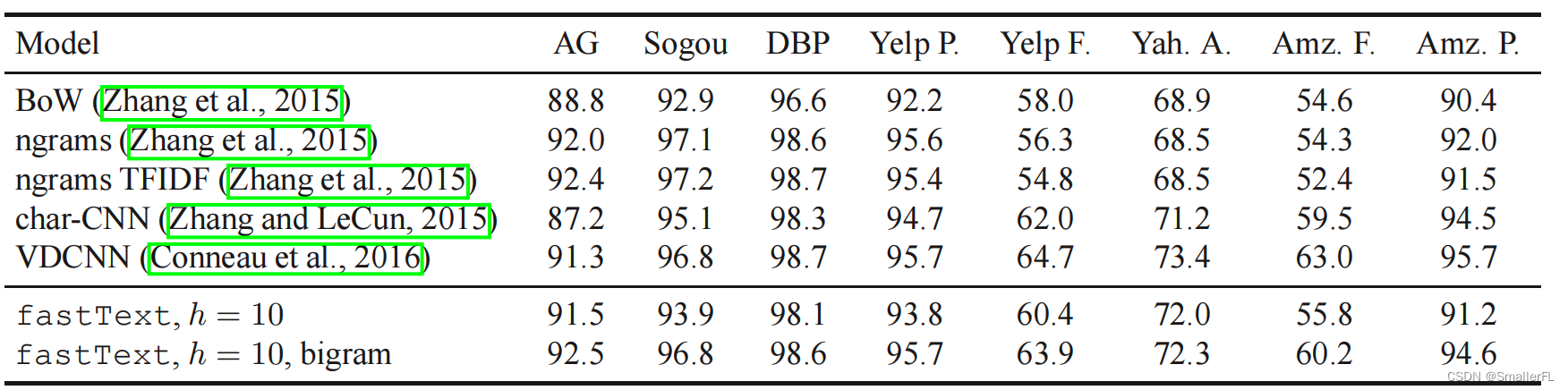
FastText 算法原理及使用方法
文章目录 1. 前言2. 模型架构2.1 Hierarchical Softmax2.2 n-gram 特征 3. 训练及评估4. 使用5. 参考 1. 前言 FastText 是一个由 Facebook AI Research 在2016年开源的文本分类器,它的设计旨在保持高分类准确度的同时,显著提升训练和预测的速度。 论文:《Enriching Word Vectors
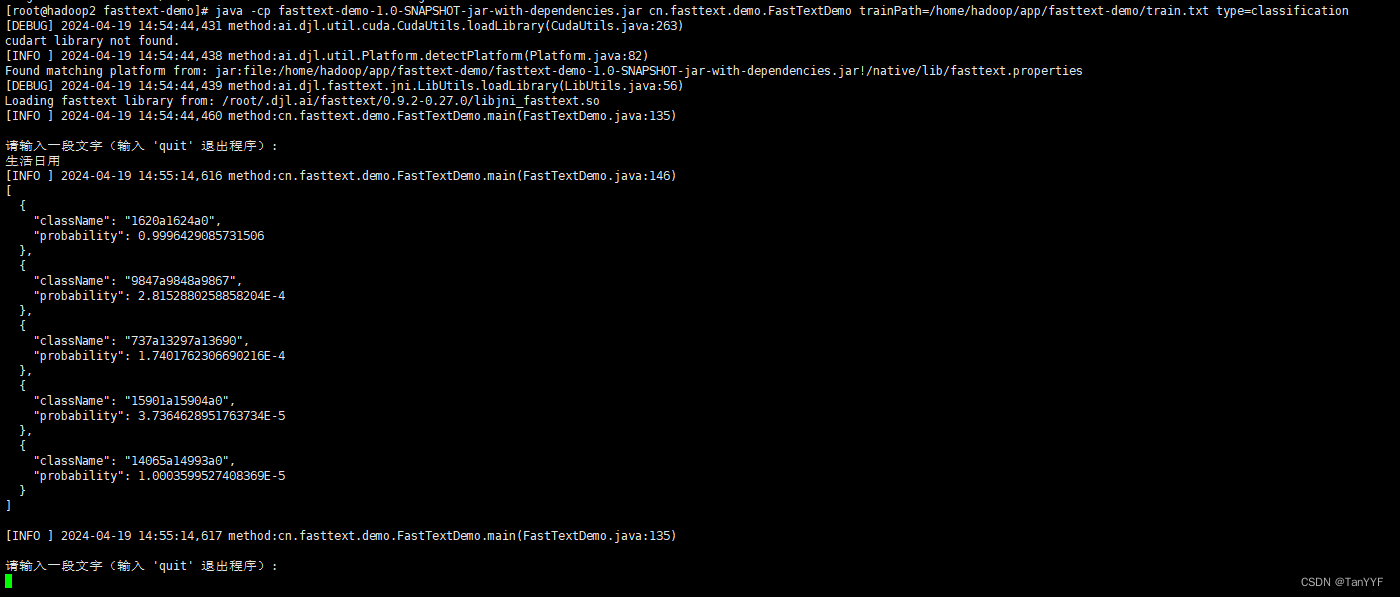
java使用fasttext实现文本分类
1.fastText 官网 fastText是一个用于有效学习单词表示和句子分类的库fastText建立在现代Mac OS和Linux发行版上。因为它使用了c++ 11的特性,所以它需要一个具有良好的c++11支持的编译器 2.创建maven项目 maven配置: <?xml version="1.0" encoding="UTF-8"?><project xmlns="http://

在windows中anaconda中安装fasttext (whl 文件安装)
Anaconda安装第三方包(whl文件) windows 安装fasttext 一直不成功,python 版本3.8 网上教程都是 https://www.lfd.uci.edu/~gohlke/pythonlibs/#fasttext 下载然后安装,但是这个网站里我没找到哈哈哈。。。 然后就是成功方案: 百度了下 fasttext pypi :https://pypi.org/proje

FastText快速文本分类
FastTest架构 fastText 架构原理 fastText 方法包含三部分:模型架构、层次 Softmax 和 N-gram 特征fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。 序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激

FastText 微调
使用教程参见https://blog.csdn.net/jingyi130705008/article/details/137153444,安装之前只需要把model.cc文件中以下几行代码注释掉即可实现【冻结词向量】。 for (auto it = input.cbegin(); it != input.cend(); ++it) {wi_->addRow(grad_, *it, 1.0)
【NLP10-fasttext工具】
了解fasttext工具的作用 了解fasttext工具的优势及其原因 掌握fasttext的安装方法 1、认识fasttext工具 1.1、作用: 进行文本分类 训练词向量 1.2、工具包优势 正如它的名字,在保持较高精度的情况下,快速的进行训练和预测是fasttext的最大优势。 1.3、fasttext优势的原因 fasttext工具包中内涵的fasttext模型具有十分
NLP之Fasttext
NLP之Fasttext 一、简介 Fasttext是2016年facebook开源的一个机器学习模型,可用于生成词向量和文本分类。文本分类方面据说有着和深度学习模型接近的效果,并且训练速度更快(其中一个原因是使用了层次化softmax加快了运算过程)。模型的输入是一个句子及其n-gram特征,输出类别。 二、语料(文本分类) 输入的数据需要经过一些简单的处理,fa
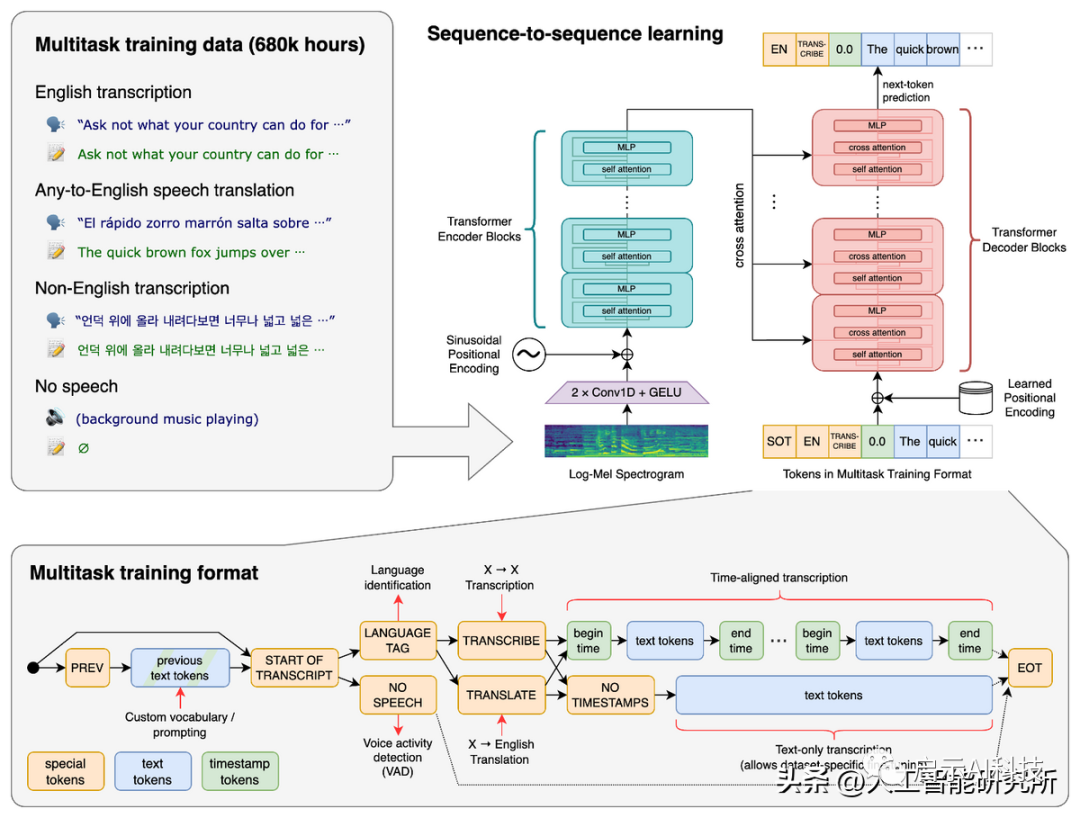
基于fasttext与langid文本语种识别的python代码实现
上期文章,我们分享了OpenAI开源的能识别99种语言的语音识别系统——whisper。 Whisper 是一种自动语音识别模型,基于从网络上收集的 680,000 小时多语言数据进行训练。根据 OpenAI的介绍,该模型对口音、背景噪音和技术语言具有很好的鲁棒性。此外,它还支持 99 种不同语言的转录和从这些语言到英语的翻译。 whisper语音识别系统 虽然Open AI开源的
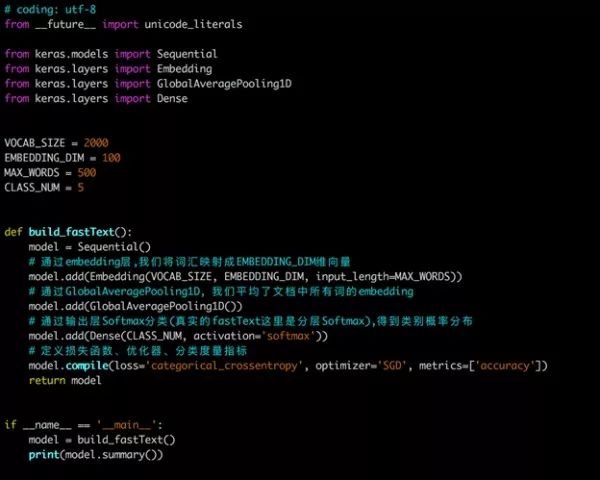
达观数据王江:fastText原理及实践
fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新。但是它的优点也非常明显,在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CPU上, 能够训练10亿词级别语料库的词向量在10分钟之内,能够分类有着30万多类别的50多万句子在1分钟之内。 本文首先会介绍一些

文本分类(TFIDF/朴素贝叶斯分类器/TextRNN/TextCNN/TextRCNN/FastText/HAN)
目录 简介TFIDF朴素贝叶斯分类器 贝叶斯公式贝叶斯决策论的理解极大似然估计朴素贝叶斯分类器TextRNNTextCNNTextRCNNFastTextHANHighway Networks 简介 通常,进行文本分类的主要方法有三种: 基于规则特征匹配的方法(如根据喜欢,讨厌等特殊词来评判情感,但准确率低,通常作为一种辅助判断的方法)基于传统机器学习的方法(特征工程 + 分类算法
windows下编译的fasttext 0.9.2 命令行工具
基于官方代码在windows下编译的命令行工具,fasttext 0.9.2最新release版本,支持autotune等功能。 csdn下载链接:fasttext0.9.2windowscommandlinetools-机器学习文档类资源-CSDN下载 或到github免费下载,大家可以帮忙star一下~:sigmeta/fastText-Windows: fastText built fo
【nlp】4.1 fasttext工具介绍(文本分类、训练词向量、词向量迁移)
fasttext工具介绍与文本分类 1 fasttext介绍1.1 fasttext作用1.2 fasttext工具包的优势1.3 fasttext的安装1.4 验证安装 2 fasttext文本分类2.1 文本分类概念2.2 文本分类种类2.3 文本分类的过程2.4 文本分类代码实现2.4.1 获取数据2.4.2 训练集与验证集的划分2.4.3 训练模型2.4.4 使用模型进行预测评估
python实现fasttext
1、用开源库 import fasttext# 准备训练数据# 数据应该是一个文本文件,其中每一行表示一个样本,每行以一个标签开头,然后是文本内容。# 标签的格式为:__label__<your-label>,例如:__label__positive I love this movie!train_data = 'path/to/your/training/data.txt'# 训练模型m
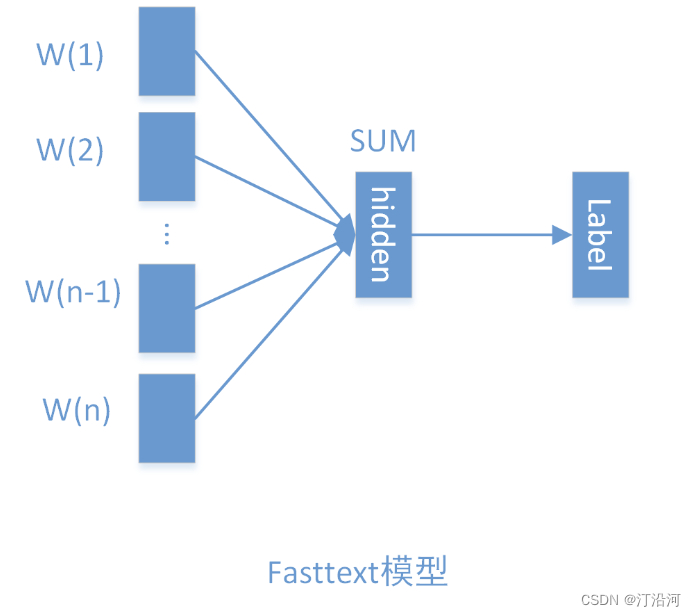
1 NLP分类之:FastText
0 数据 https://download.csdn.net/download/qq_28611929/88580520?spm=1001.2014.3001.5503 数据集合:0 NLP: 数据获取与EDA-CSDN博客 词嵌入向量文件: embedding_SougouNews.npz 词典文件:vocab.pkl 1 模型 基于fastText做词向量嵌入然后引入2-gra