本文主要是介绍K8s-持久化(持久卷,卷申明,StorageClass,StatefulSet持久化),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
POD 卷挂载
apiVersion: v1
kind: Pod
metadata:name: random-number
spec:containers:- image: alpinename: alpinecommand: ["/bin/sh","-c"]args: ["shuf -i 0-100 -n 1 >> /opt/number.out;"]volumeMounts:- mountPath: /optname: data-volumevolumes: #这里声明了卷- name: data-volumehostPath:path: /data #这个卷对应的主机路径type: Directory #这个路径的类型为文件类型
上面这个POD创建以后会生成一些随机数写到容器的/opt/number.out,由于我们将/opt路径映射到了主机目录/data所以我们在这个路径也能看到它。

特别注意:这里我们定义的POD声明的是主机路径,它只在单节点能够正常工作,因为可能只有这个节点才存在data目录。又比如我们部署了三个POD,被分配到了不同的Worker节点,这个POD的工作依赖了一个底层环境,这个环境是一些库函数需要安装到指定目录下,这个时候不可能去每个工作节点都安装一遍,因此这里就需要配置一些集群存储方案,主要目的是完成文件同步
Kubernetes支持多种不同类型的存储解决方案:
- NFS
- ClusterFS
- Flocker
- Ceph FS
- AWS EBS
- Azure
- GCP
比如是aws 存储,对应的yml可以向下面这样定义:
volumes:
- name: data-volumeawsElasticBlockStore:volumeID: <VOLUME-ID>fsType: ext4
不同的云厂商会提供一个yml标准供我们使用。
那如果没有云厂商,我们也可以自己建一个分布式文件共享系统NFS。nfs集群搭建
#前置条件你的这些节点能够相互通信
#选择一个节点作为Master 安装工具
yum install -y nfs-utils rpcbind
#创建一个目录将这个目录暴露共享
mkdir -p /usr/local/data
#修改这个配置
vim /etc/exports
##填入下面的值 (rw,sync)表示这个文件可读可写,sync同步
#ip为master的ip,24为掩码
/usr/local/data ip/24 (rw,sync)
#在Master节点启动
systemctl start nfs.service
systemctl start rpcbind.service
systemclt enable nfs.service
systemclt enable rpcbind.service
#从节点上安装nfs-utils即可
yum install -y nfs-utils
#可以查看这个节点有哪些共享目录
showmount -e 192.168.163.132
#从节点将远程目录挂载到本地 /usr/local/data 本地路径推荐和远程路径一致
mount 192.168.163.132:/usr/local/data /usr/local/data
对应的配置其实和主机路径是一样的,只是配置共享路径:
spec:volumes:- name : web-apphostPath:path:/usr/local/data#共享目录,这个目录的修改会被NFS同步到其它节点
持久卷 Persistent Volume
通过POD指定Volume 的时候我们需要配置每个POD的主机路径,那如果我们后面需要修改主机的路径就会修改每个POD的yml。并且我们还要知道主机路径的具体细节,持久卷就是为了屏蔽这些事情。持久卷是由管理员配置的群集范围的存储卷池,供在群集上部署应用程序的用户使用。用户可以使用持久卷声明从此池中选择存储。
1 先定义一个持久卷
apiVersion: v1
kind: PersistentVolume
metadata:name: pv-vol1
spec: accessModes:- ReadWriteOncecapacity:storage: 1GihostPath:path: /tmp/datapersistentVolumeReclaimPolicy: Retain
accessModes:定义了存储设备的访问模式有下面这些取值
- ReadWriteOnce:存储卷可读可写,但只能被一个节点上的 Pod 挂载
- ReadOnlyMany:存储卷只读不可写,可以被任意节点上的 Pod 多次挂载
- ReadWriteMany:存储卷可读可写,也可以被任意节点上的 Pod 多次挂载。
kubectl create –f pv-definition.yaml
#查看持久卷
kubectl get persistentvolume
生产环境中可能会使用云存储例如:
apiVersion: v1
kind: PersistentVolume
metadata:name: pv-vol1
spec: accessModes:- ReadWriteOncecapacity:storage: 1GiawsElasticBlockStore:volumeID: <VOLUME-ID>fsType: ext4
2 定义好了持久卷,我们还需要创建持久卷申明
创建持久卷声明后, Kubernetes将根据请求和卷上设置的属性将持久卷绑定到声明。每个持久卷声明都绑定到一个持久卷。在绑定的过程中会根据是否有足够的容量,访问模式是否匹配,卷模式这些条件匹配到对应的持久卷。
单个声明有多个可能得匹配项,但如果希望专门使用特定得卷, 可以使用标签与选择器绑定。如果所有其他条件都匹配,并且没有更好的选项, 则较小的声明可能绑定到较大的卷。
如果没有可用的卷,则永久卷声明将保持Pending挂起状态, 直到有更新的卷可供群集使用。一旦有更新的卷可用,声明将自动绑定到新的可用卷。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: mypvc
spec:accessModes:- ReadWriteOnceresources:requests:storage: 500Mi
kubectl create –f pvc-definition.yaml
#查看申明
kubectl get persistentvolumeclaim
kubectl get pvc
#删除申明
kubectl delete persistentvolumeclaim mypvc
删除声明, 可以选择要对卷执行的操作,持久卷persistentVolumeReclaimPolicy: Retain进行了指定
- 默认情况下, 它设置为保留Retain。持久卷将一直保留,直到管理员手动将其删除。但它不能被任何其他声明重复使用。
- 可以被自动删除Delete。一旦删除了声明,卷也将被删除。从而释放终端存储设备上的存储空间。
- 第三种是Recycle。在这种情况下, 数据卷中的数据将在可用于其他声明之前被擦除。
apiVersion: v1
kind: Pod
metadata:name: mypod
spec:containers:- name: myfrontendimage: nginxvolumeMounts:- mountPath: "/var/www/html"name: mypdvolumes:- name: mypdpersistentVolumeClaim:claimName: mypvc
如果系统里的存储资源非常多,PVC去遍历查找合适的PV会比较麻烦,可以通过给PV和PVC添加storageClassName进行匹配。
示例如下:
apiVersion: v1
kind: PersistentVolume
metadata:name: task-pv-volumelabels:type: local
spec:storageClassName: manualcapacity:storage: 10GiaccessModes:- ReadWriteOncehostPath:path: "/mnt/data"
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: task-pv-claim
spec:storageClassName: manualaccessModes:- ReadWriteOnceresources:requests:storage: 3Gi
存储类 Storage Class
假设生产环境完全上云,每次创建PV之前, 用户都必须在云上先申请存储空间。
每次应用程序需要存储时,要先在云平台购买存储空间,然后手动创建对应的持久卷定义文件。这Storage Class就是为了解决这一问题,StorageClass, 可以定义一个配置器provisioner,用来自动在云平台上配置存储卷,并在pvc创建时将存储附加到Pod,其实也就是将手动创建PV的过程自动化了。
1 创建StorageClass
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: gce-pd
provisioner: kubernetes.io/gce-pd
provisioner取决于所使用的平台,
- 公有云平台如谷歌云使用kubernetes.io/gce-pd
- 自建nfs平台使用k8s-sigs.io/nfs-subdir-external-provisioner
2 使用StorageClass
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: mypvc
spec:accessModes:- ReadWriteOncestorageClassName: gce-pdresources:requests:storage: 500Mi
StatefulSet 有状态集
StatefulSet类似于ReplicaSet, 基于模板创建, 可以扩容和缩小,执行滚动更新和回滚。它主要是为了解决依赖关系的问题。使用StatefulSet将按顺序创建Pod。在部署第一个Pod后, 等待直到处于运行和就绪状态,才部署下一个Pod。
比如我们需要部署一个高可用reids, 一个主节点,一个从节点,从节点也有自己的备份
apiVersion: apps/v1
kind: StatefulSet
metadata:name: redislabels: app: redis
spec:serviceName: redis-hselector: matchLabels:app: redisreplicas: 3template:metadata:labels: app: redisspec:containers:- name: redisimage: redis
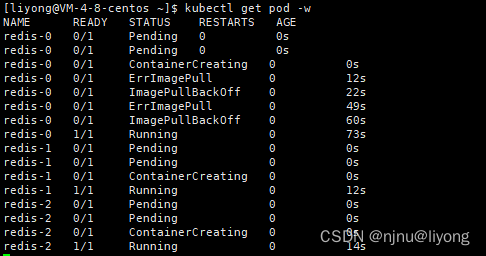
kubectl create -f statefulset-def.ymlkubectl get pod -w
#查看StatefulSet
kubectl get sts
#删除
kubectl delete sts redis
StatefulSet 持久化
假设我们希望数据库拥有主从备份和读写分离。那么StatefulSet下的每一个Pod都应该有自己单独的卷。Pod不希望共享数据, 每个Pod都需要自己的本地存储。则可以定义一个持久化的模板,来进行工作。
apiVersion: apps/v1
kind: StatefulSet
metadata:name: redislabels: app: redis
spec:serviceName: redis-hselector: matchLabels:app: redisreplicas: 3template:metadata:labels: app: redisspec:containers:- name: redisimage: redisvolumeMounts: - mountPath: /dataname: data-volumevolumeClaimTemplates: #重点在于这里的定义- metadata: name: data-volume spec: storageClassName: gce-pdaccessModes: - ReadWriteManyresources: requests: storage: 100Mi
这篇关于K8s-持久化(持久卷,卷申明,StorageClass,StatefulSet持久化)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!