本文主要是介绍实践数据湖iceberg 第二十七课 flink cdc 测试程序故障重启:能从上次checkpoint点继续工作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列文章目录
实践数据湖iceberg 第一课 入门
实践数据湖iceberg 第二课 iceberg基于hadoop的底层数据格式
实践数据湖iceberg 第三课 在sqlclient中,以sql方式从kafka读数据到iceberg
实践数据湖iceberg 第四课 在sqlclient中,以sql方式从kafka读数据到iceberg(升级版本到flink1.12.7)
实践数据湖iceberg 第五课 hive catalog特点
实践数据湖iceberg 第六课 从kafka写入到iceberg失败问题 解决
实践数据湖iceberg 第七课 实时写入到iceberg
实践数据湖iceberg 第八课 hive与iceberg集成
实践数据湖iceberg 第九课 合并小文件
实践数据湖iceberg 第十课 快照删除
实践数据湖iceberg 第十一课 测试分区表完整流程(造数、建表、合并、删快照)
实践数据湖iceberg 第十二课 catalog是什么
实践数据湖iceberg 第十三课 metadata比数据文件大很多倍的问题
实践数据湖iceberg 第十四课 元数据合并(解决元数据随时间增加而元数据膨胀的问题)
实践数据湖iceberg 第十五课 spark安装与集成iceberg(jersey包冲突)
实践数据湖iceberg 第十六课 通过spark3打开iceberg的认知之门
实践数据湖iceberg 第十七课 hadoop2.7,spark3 on yarn运行iceberg配置
实践数据湖iceberg 第十八课 多种客户端与iceberg交互启动命令(常用命令)
实践数据湖iceberg 第十九课 flink count iceberg,无结果问题
实践数据湖iceberg 第二十课 flink + iceberg CDC场景(版本问题,测试失败)
实践数据湖iceberg 第二十一课 flink1.13.5 + iceberg0.131 CDC(测试成功INSERT,变更操作失败)
实践数据湖iceberg 第二十二课 flink1.13.5 + iceberg0.131 CDC(CRUD测试成功)
实践数据湖iceberg 第二十三课 flink-sql从checkpoint重启
实践数据湖iceberg 第二十四课 iceberg元数据详细解析
实践数据湖iceberg 第二十五课 后台运行flink sql 增删改的效果
实践数据湖iceberg 第二十六课 checkpoint设置方法
实践数据湖iceberg 第二十七课 flink cdc 测试程序故障重启:能从上次checkpoint点继续工作
实践数据湖iceberg 第二十八课 把公有仓库上不存在的包部署到本地仓库
实践数据湖iceberg 第二十九课 如何优雅高效获取flink的jobId
实践数据湖iceberg 第三十课 mysql->iceberg,不同客户端有时区问题
实践数据湖iceberg 更多的内容目录
文章目录
- 系列文章目录
- 前言
- 一、初始化
- 1.1 代码
- 1.2 启动命令
- 1.3.引入库
- 1.4 sink的iceberg表查询:
- 1.5 页面查看,开启了checkpoint
- 二、停止作业
- 2.1 cancel作业
- 2.2 写入2条数据
- 三、 从checkpoint恢复
- 总结
前言
程序化部署,测试flink cdc重启恢复
测试思路:1.程序停止时,进行checkpoint记录,记录checkpoint的位置 2.程序停止时,写入数据, 记录写入的数据, 测试重启后,能否从故障点开始恢复。
结论:能
一、初始化
1.1 代码
代码思路: 1. 定义source表, 2.定义sink表 3. 写入sink from source
public static void main(String[] args) throws Exception {FromTableToIcebergSqlTemple temple = new FromMysqlToIcebergSql();String fromSql = temple.createFromTableSql();String createToTableSql = temple.createIcebergTableSql();String createIcebergCatalog = temple.createIcebergCatalogSql();System.setProperty("HADOOP_USER_NAME", "root");//TODO 1.准备环境//1.1流处理环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.enableCheckpointing(10000L);env.setParallelism(1);//1.2 表执行环境StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);//1.3 建source表tableEnv.executeSql(fromSql);//1.4 建iceberg表tableEnv.executeSql(createIcebergCatalog);tableEnv.executeSql("use catalog "+ temple.icebergCatalogName());tableEnv.executeSql("use "+ temple.icebergDbName());tableEnv.executeSql(createToTableSql);//1.5 执行sqltableEnv.executeSql("use catalog default_catalog");tableEnv.executeSql("use default_database");tableEnv.executeSql(temple.sourceToIcebergSinkSql());//TODO 6.执行任务env.execute();}
1.2 启动命令
108060 YarnCoarseGrainedExecutorBackend
[root@hadoop101 apps]# [root@hadoop101 apps]# flink run -c com.jintemg.cdc.FlinkSqlCdcRunner -C file:///opt/software/flink1.13-iceberg0131/iceberg-flink-runtime-1.13-0.13.1.jar -C file:///opt/software/flink1.13-iceberg0131/flink-sql-connector-hive-2.3.6_2.12-1.13.5.jar -C file:///opt/software/flink1.13-iceberg0131/flink-sql-connector-mysql-cdc-2.1.1.jar flink-iceberg-learning-1.0-SNAPSHOT.jar
1.3.引入库
清空表,写入3条数据
INSERT INTO `stock_basic` VALUES ('0', '000001.SZ', '000001', '平安银行', '深圳', '银行', '19910403', null);
INSERT INTO `stock_basic` VALUES ('1', '000002.SZ', '000002', '万科A', '深圳', '全国地产', '19910129', null);
INSERT INTO `stock_basic` VALUES ('2', '000004.SZ', '000004', '国华网安', '深圳', '软件服务', '19910114', '李映彤');
1.4 sink的iceberg表查询:
Time taken: 0.4 seconds, Fetched 3 row(s)
spark-sql (default)> select * from stock_basic_iceberg_sink;
22/04/07 16:06:45 WARN conf.HiveConf: HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
i ts_code symbol name area industry list_date actural_controller
0 000001.SZ 000001 平安银行 深圳 银行 19910403 NULL
1 000002.SZ 000002 万科A 深圳 全国地产 19910129 NULL
2 000004.SZ 000004 国华网安 深圳 软件服务 19910114 李映彤
Time taken: 0.519 seconds, Fetched 3 row(s)
1.5 页面查看,开启了checkpoint
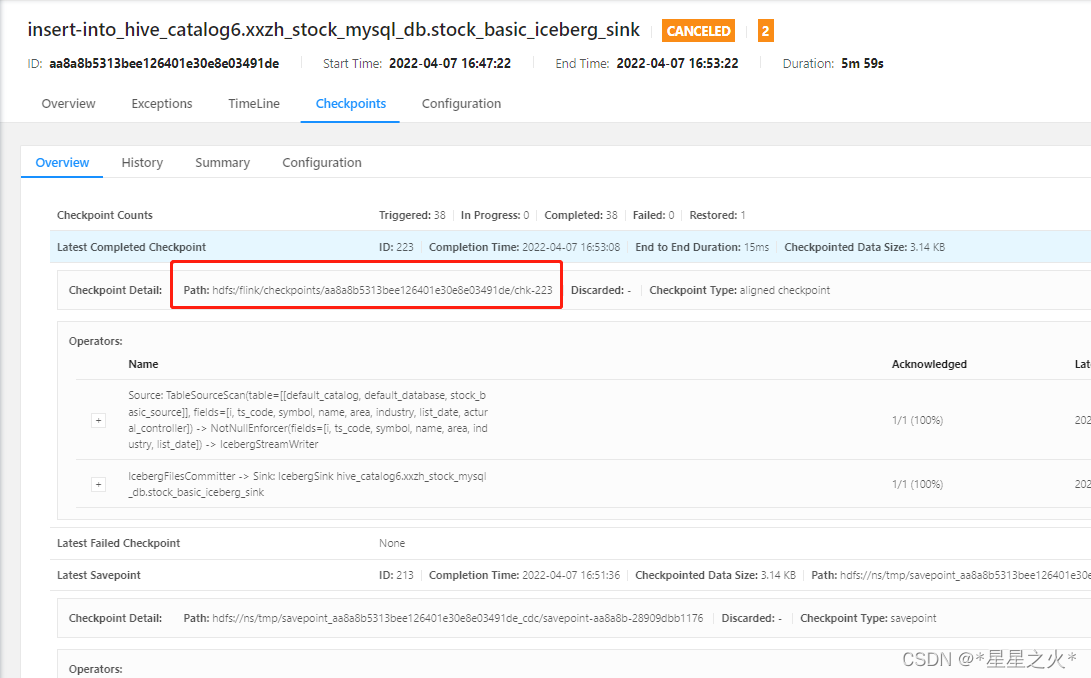
checkpint地址
Path: hdfs:/flink/checkpoints/aa8a8b5313bee126401e30e8e03491de/chk-223
二、停止作业
2.1 cancel作业
2.2 写入2条数据
写入2条数据
INSERT INTO `stock_basic` VALUES ('3', '000005.SZ', '000005', 'ST星源', '深圳', '环境保护', '19901210', '郑列列,丁芃');
INSERT INTO `stock_basic` VALUES ('4', '000006.SZ', '000006', '深振业A', '深圳', '区域地产', '19920427', '深圳市人民政府国有资产监督管理委员会');
三、 从checkpoint恢复
整体思路:检查是否从id=3开始同步,把3,4同步过来,0,1,2没有同步.
从checkpoint恢复命令:
[root@hadoop101 apps]# flink run -s hdfs:///flink/checkpoints/aa8a8b5313bee126401e30e8e03491de/chk-224 -c com.jintemg.cdc.FlinkSqlCdcRunner -C file:///opt/software/flink1.13-iceberg0131/iceberg-flink-runtime-1.13-0.13.1.jar -C file:///opt/software/flink1.13-iceberg0131/flink-sql-connector-hive-2.3.6_2.12-1.13.5.jar -C file:///opt/software/flink1.13-iceberg0131/flink-sql-connector-mysql-cdc-2.1.1.jar flink-iceberg-learning-1.0-SNAPSHOT.jar
结果: 到iceberg查,发现从上次中断消费开始继续
spark-sql (default)> select * from stock_basic_iceberg_sink;
22/04/07 16:58:55 WARN conf.HiveConf: HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
i ts_code symbol name area industry list_date actural_controller
0 000001.SZ 000001 平安银行 深圳 银行 19910403 NULL
1 000002.SZ 000002 万科A 深圳 全国地产 19910129 NULL
2 000004.SZ 000004 国华网安 深圳 软件服务 19910114 李映彤
3 000005.SZ 000005 ST星源 深圳 环境保护 19901210 郑列列,丁芃
4 000006.SZ 000006 深振业A 深圳 区域地产 19920427 深圳市人民政府国有资产监督管理委员会
总结
发现从cdc是能从checkpoint恢复,程序正常运行。
现在有下一个问题:如何在程序中获取 本任务的checkpoint位置? 本任务的jobId?
这篇关于实践数据湖iceberg 第二十七课 flink cdc 测试程序故障重启:能从上次checkpoint点继续工作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





