本文主要是介绍DSVP Dual-Stage Viewpoint Planner for Rapid Exploration by Dynamic Expansion,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- DSVP
- 整体思路:
- 主要创新点:
- 详细过程:
- 探索阶段:
- 回溯过程
- 其他:
- 自己的一些问题:
DSVP
文章来源: 2021,IROS
类型: 导航算法
阅读日期: December 16, 2021
DSVP Dual-Stage Viewpoint Planner for Rapid Exploration by Dynamic Expansion
整体思路:
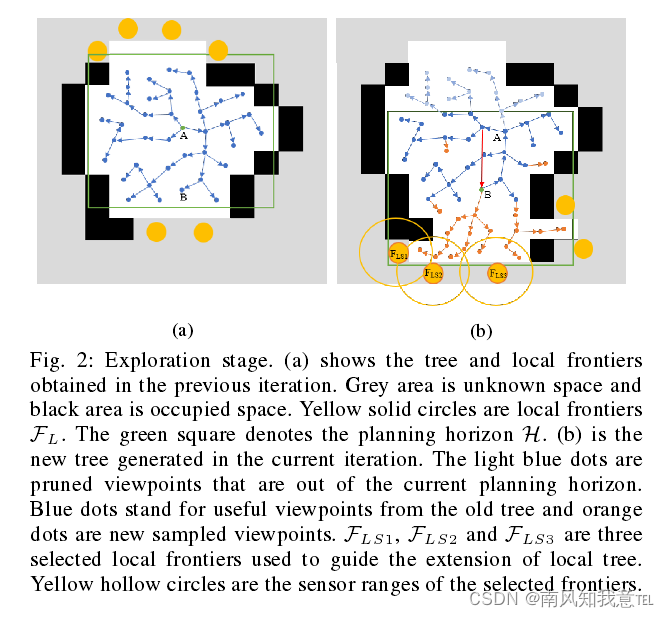
本文算法的整个探索过程被分为两个阶段。第一阶段直接命名为探索(Exploration),因为这一阶段机器人会一直收集未知的信息,真正符合探索的概念。在这一阶段,会使用RRT(Rapidly-exploring random tree)在机器人周围的局部区域内随机采样观测点,不断地扩展探索区域,并扩大全局的观测点图。大多数算法都包含这一阶段,且大多使用RRT或者RRG(Rapidly exploring random graph)延伸局部的观测点。第二阶段则命名为重定位(Relocation),因为这一阶段,机器人周围已经没有未知区域,需要被重新引导至较远处的未知区域继续探索。在这一过程中,机器人始终是在已知区域内行驶,不会收集任何的未知信息。根据这一思想,将算法命名为DSVP(Dual Stage Viewpoint Planner)。下图1是的方法的核心。蓝色点(Vi)为局部观测点,红色点(vi)为全局观测点,橙黄色圆点(FL)为局部的边界点,紫色圆点(FG)为全局边界点,当探索阶段,仍然有局部边界点时,则继续进行探索,生成探索轨迹(橙黄色轨迹线)。反之,当没有局部边界点时,进入重定位阶段,生成重定位轨迹(紫色轨迹线)。
主要创新点:
动态拓展:在两个探索阶段都在动态的拓展RRT树和全局图。RRT生成的节点被保存以达到快速回溯的目的。
混合边界:本方法使用了RRT的节点视域下的边界和机器人视域的边界来保证覆盖的更广。
参考来源:Receding horizon" next-best-view" planner for 3D exploration.(NBVP)
详细过程:
探索阶段:
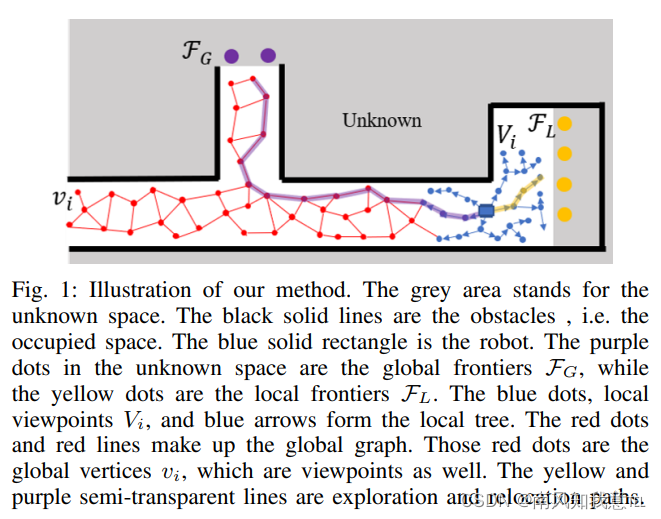
- 在每次的迭代过程中,假设点A为当前位置PR采用RRT进行动态生成观察点(viewpoint)(这时应该考虑的是蓝色的局部探索部分H,当走过局部探索后,也就是探索的绿色窗口前移,这些viewpoint就变成了红色的全局图(graph)的顶点(vertex)),这些点定义为V。
- 当机器人继续前移,到达B位置点时,删除被障碍物或者是不在当前规划窗口的节点,然后采用后文提到的算法2进行偏置采样,重新生成少部分的节点(原来在规划窗口的节点都被保留了)。
- 局部边界点FL被用来偏置采样的过程,使得树在生长的过程朝向未知区域。FL需要满足以下条件:
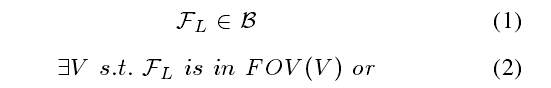
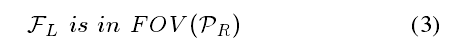
式(1)表示 F L F_{L} FL在本地边界点的抽取范围,稍大于规划窗口H,式(2)(3)表示FL应当最起码在一个viewpoint或者是机器人当前位置的视域中,以确保FL能够被viewpoint或者是机器人观察到。由于边界只是用来作为拓展方向,把边界的部分用一团团点来代替(也就是黄色的点)
- 选择在 F L F_{L} FL中,最为靠近探索方向的点作为 F L S F_{LS} FLS,如图中的 F L S 1 , F L S 2 , F L S 3 F_{LS1},F_{LS2},F_{LS3} FLS1,FLS2,FLS3。然后采用一个随机数 θ \theta θ,从0-1中进行随机生成这个数,当这个数小于 θ \theta θ的时候,就在选中的边缘点附近进行采样,从而使得树更多的往探索方向生长。
- 选择拓展的方向:利用式(4)(5)来计算每个分支的一个得分,选择一个分数最高的作为前进的路线。
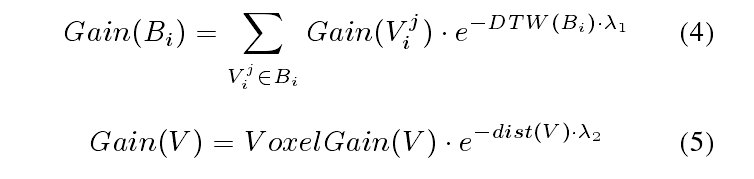
其中 B i B_i Bi代表从 V 0 V_0 V0到 V i V_i Vi这样一个分支, V i j V_i^j Vij代表了 B i B_i Bi分支中,第j个观测点, V o x e l G a i n ( V ) VoxelGain(V) VoxelGain(V)代表了在V这个观测点时的未知体素的数量, d i s t ( V ) dist(V) dist(V)代表了从 V 0 V_0 V0到当前V的距离, λ 2 \lambda_2 λ2用来惩罚距离,距离越大,则得分越低;DTW是动态时间规整函数,用于计算当前选择的路径和上次迭代选择的路径的相似度,越相似分数越低(打破平衡?) λ 1 \lambda_1 λ1是用来惩罚当前选择的路径和上次选择的路径的不同的一个参数。(这里应该是作者笔误,论文中写错了符号)
- 总述:局部边界点以一定的频率更新,初始的时候选择一些 F L S F_{LS} FLS来引导新的节点的生成,然后计算每个支路的得分以选择最终走的轨迹
回溯过程
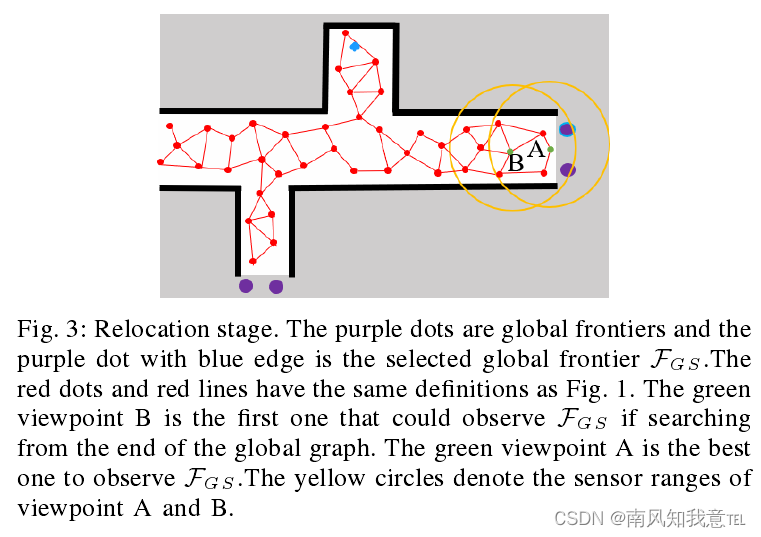
当局部规划的窗口没有了局部边界点的时候,开始进行回溯过程,寻找新的未知位置进行探索。主要涉及到全局图和全局边界。全局图就是在局部探索过程中的观测点组成,全局边界则是局部探索过程中发现的未被探索的边界点。
在构建全局图的过程中,有正值的观测点都会被加入全局图中,当加入一个 V n e w V_{new} Vnew的时候,会在其最近的位置找一个点,从而连上线,加入图中。此外,现有的一个顶点V满足以下(6)时也会被加入全局图中以保证构建的图不要太稠密。
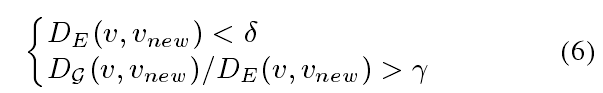
- 从当前位置(自己理解的,手动添加的蓝色点是当前位置),选一个最近位置的全局边界点作为选中的全局边界点 F G L F_{GL} FGL(越近,则需要回溯的路越少,这里作者用生成的角标来标识时间先后,数字越大,则越最近生成,距离越近,所以算法寻找也是从数字大的往下找)
- 从V的集合中,找一个可以观测到这个全局边界点的点,这时标记这个点为目标点 V s V_s Vs,如图中的B点,,计算这个点到边界点的距离Dist(对应算法3-14行)。其中j代表的是全局边界点的遍历序号,i代表的是全局图的节点V的序号。(我认为算法3中作者有个笔误,5行代码处,应该是 F j F_j Fj)
- 再遍历一次图的点V,找一个离观测点最近的点作为 V s V_s Vs,如图中的A点。
- 此时目标点就是A点,规划一个从当前位置到A点的路线即可完成回溯。

其他:
主要提供了写测试的仿真环境和可视化界面,详细可以参考CMU的探索主页。
测试的结果详见论文结果。
自己的一些问题:
1.混合边界:机器人视域或是viewpoint的视域
2. 探索方向怎么定?
3. 探索轨迹怎么定的?The best branch is then obtained and taken as the trajectory by computing the reward of each branch in the tree.
4. VoxelGain(V ) is the number of unknown voxels in the FOV of viewpoint V .啥意思?
5. (4)(5)的具体计算方法没有理解,去看相关的文献
6. First,the planner searches for a vertex that is able to observe anyglobal frontier in G determined by ray tracing,这个点啥意思?
这篇关于DSVP Dual-Stage Viewpoint Planner for Rapid Exploration by Dynamic Expansion的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






