本文主要是介绍GaitSet学习笔记(不包括三元数损失,仅含主干网络),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文
1 Introduction
1.1 旧方法
① 将步态轮廓压缩为一张图(损失了时序信息与细粒度系信息)
② 直接从原始步态轮廓序列中提取特征(极易受到外部条件影响)

1.2 我们提出的方法
步态序列可以看做一个周期,而特定帧有其特定的步态形态,人类很容易可以复原打乱的步态序列的顺序。因此,顺序信息不必需提供给网络,而将步态序列帧看做一个个具有位置信息的帧组成的集合,网络可以通过学习得到序列的时序信息。

基于步态具有位置信息的假设,我们提出了一个端到端的网络,并且具有以下的三大优点:
① 灵活:输入不受到约束
② 快速:直接对二维剪影序列进行特征提取,减少计算(相比于机器学习方法)
③ 高效:缓解协变量影响,提高鲁棒性与泛化能力

2 Related Work
受到PointNet(处理点云信息)的启发,采用了无序集作为网路输入数据。点云模型是三维图形的一种表示模型,点云具有顺序无关性。PointNet利用无序集可以避免量化带来的噪声和数据扩展,并获得高性能。

3 GaitSet
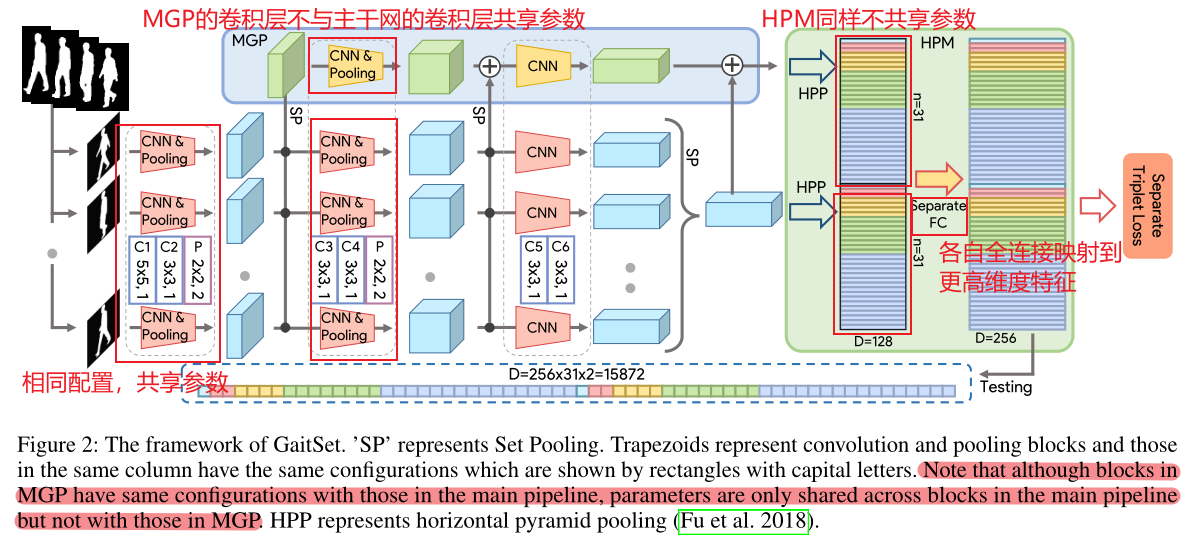
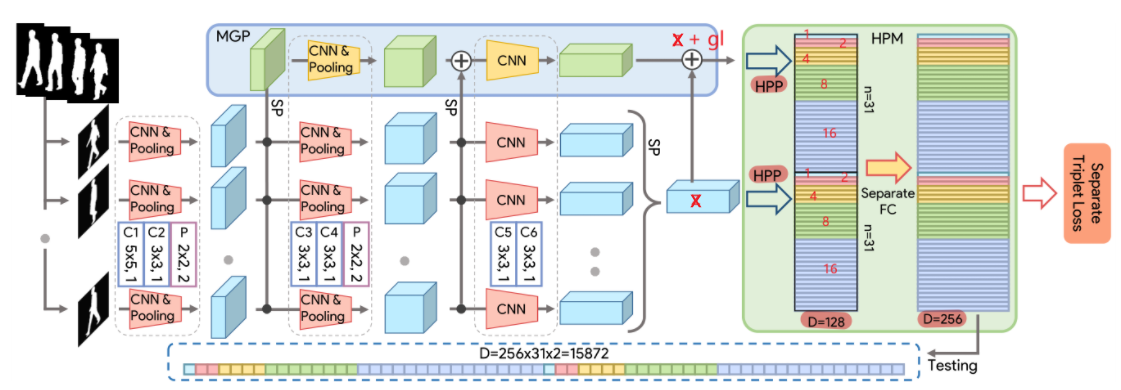
3.1 主干网络简介
F:通过卷积层,得到序列的帧级别特征
G:通过集合池化(Set Pooling),将帧级别特征映射到集合级别特征
H:通过水平金字塔映射,学习集合级别特征的判别性表示

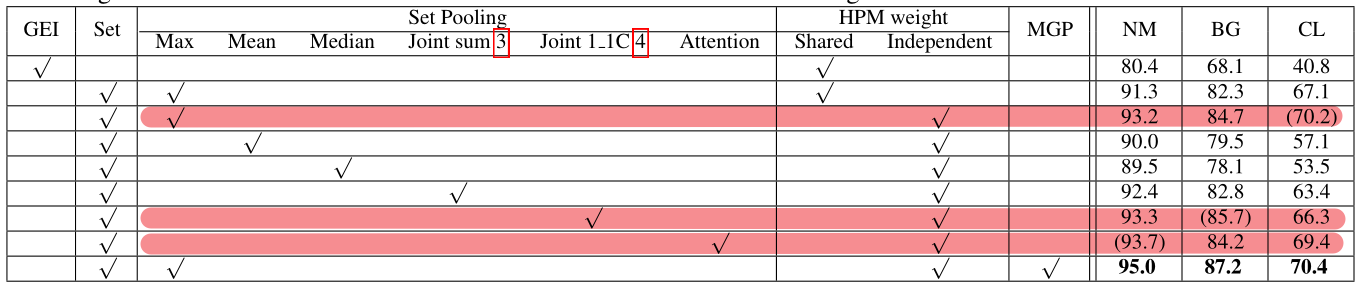
3.2 集合池化(Set Pooling)
作用:集合元素的步态信息,将帧级别特征映射为集合级别特征
两个限制:
① 必须是排列不变函数
② 接受任何数量的集合输入
SP的几个实例:
① Statistical Functions:为了满足排列不变,可以引入max,mean和median这类统计函数
② Joint Functions:上述统计函数的两种连接方式
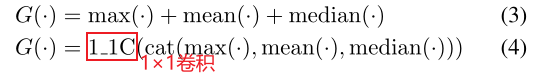
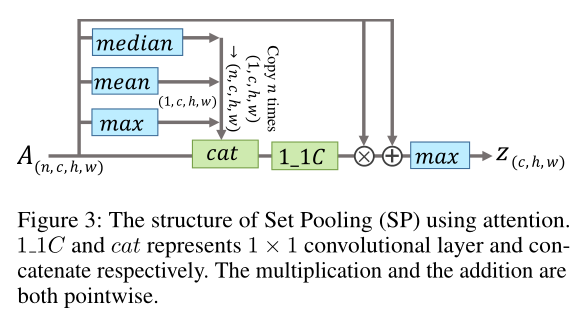
③ Attention:利用全局信息为每个帧级特征学习一个元素级的注意映射,并对其进行细化
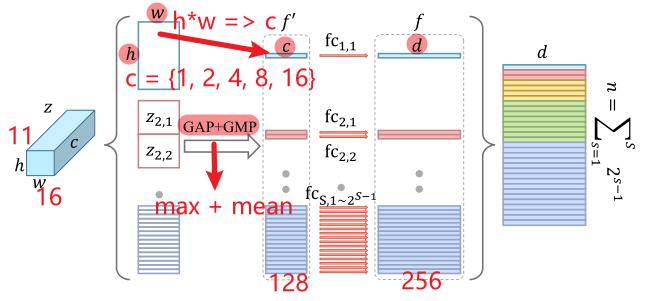
3.3 水平金字塔映射(Horizontal Pyramid Mapping)
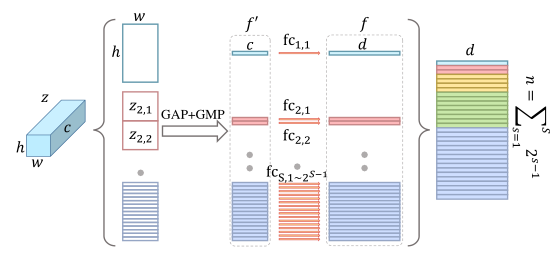

① 通过划分水平条的方式来获得多尺度的特征,该算法通常划分为S个尺度,由集合池化提取后的特征图在高度尺寸上被分成2^(k-1)条
② 不同的水平条在不同的尺度上描述着不同的感受野,同时在每个尺度上描述不同空间位置的运动特征
③ 结合使用平均与最大池化策略对不同尺度的空间条信息进行提取:平均池化可以感知空间条的全局信息,最大池化可以提取最具判别性的信息,结合两种池化得到的融合特征将具有更强的判别能力
④ 通过独立权重的全连接层将特征映射到更具判别力的空间,从而获得步态特征的判别性表示
⑤ MGP模块和主网络模块分别经过HPP操作,宽度和高度这两个维度被压缩成1,2,4,8,16这样的1个维度
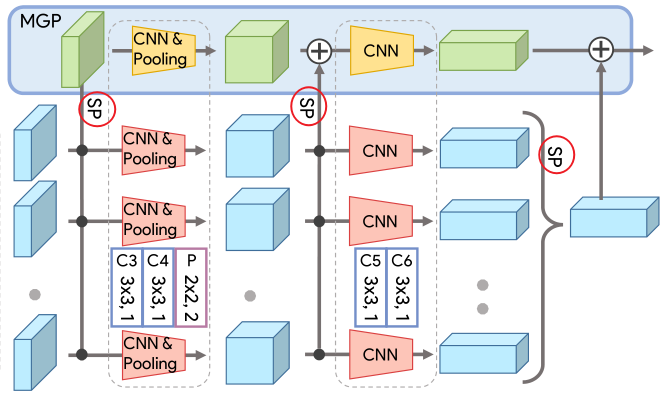
3.4 多层全局管道(MGP)

众所周知,浅层的网络学习局部信息以及细粒度信息,深层网络学习全局信息以及粗粒度信息。MGP的提出正是为了收集不同层次网络的集合级别特征信息。
注意,MGP后的HPM与主干网后的HPM不共享参数。
代码
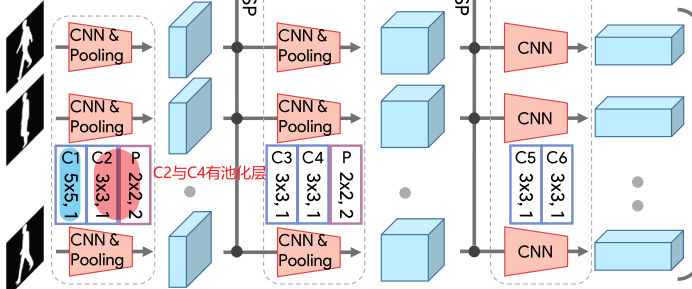
1 主干网卷积网
# 基本卷积核
class BasicConv2d(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, **kwargs):super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, bias=False, **kwargs)def forward(self, x):x = self.conv(x)return F.leaky_relu(x, inplace=True)# 卷积核 + 池化层
class SetBlock(nn.Module):def __init__(self, forward_block, pooling=False):super(SetBlock, self).__init__()self.forward_block = forward_blockself.pooling = poolingif pooling:self.pool2d = nn.MaxPool2d(2) # 2×2池化def forward(self, x):n, s, c, h, w = x.size() # n人物数量,s序列数量,c通道数量,h图片高,w图片宽x = self.forward_block(x.view(-1, c, h, w)) # [bs, 30, 1, 64, 44] => [bs * 30, 1, 64, 44]if self.pooling:x = self.pool2d(x)_, c, h, w = x.size()return x.view(n, s, c, h ,w)_set_in_channels = 1
_set_channels = [32, 64, 128]
self.set_layer1 = SetBlock(BasicConv2d(_set_in_channels, _set_channels[0], 5, padding=2)) # C1:1, 32, 5, 2
self.set_layer2 = SetBlock(BasicConv2d(_set_channels[0], _set_channels[0], 3, padding=1), True) # C2:32, 32, 3, 1 + pooling
self.set_layer3 = SetBlock(BasicConv2d(_set_channels[0], _set_channels[1], 3, padding=1)) # C3:32, 64, 3, 1
self.set_layer4 = SetBlock(BasicConv2d(_set_channels[1], _set_channels[1], 3, padding=1), True) # C4:64, 64, 3, 1 + pooling
self.set_layer5 = SetBlock(BasicConv2d(_set_channels[1], _set_channels[2], 3, padding=1)) # C5:64, 128, 3, 1
self.set_layer6 = SetBlock(BasicConv2d(_set_channels[2], _set_channels[2], 3, padding=1)) # C6:128, 128, 3, 1
2 MGP

_gl_in_channels = 32
_gl_channels = [64, 128]
self.gl_layer1 = BasicConv2d(_gl_in_channels, _gl_channels[0], 3, padding=1) # 32, 64, 3, 1
self.gl_layer2 = BasicConv2d(_gl_channels[0], _gl_channels[0], 3, padding=1) # 64, 64, 3, 1
self.gl_layer3 = BasicConv2d(_gl_channels[0], _gl_channels[1], 3, padding=1) # 64, 128, 3, 1
self.gl_layer4 = BasicConv2d(_gl_channels[1], _gl_channels[1], 3, padding=1) # 128, 128 3, 1
self.gl_pooling = nn.MaxPool2d(2)
3 Set Pooling
def frame_max(self, x):return torch.max(x, 1) # 第二维度(frame)的最大值。论文表示,利用max作为SP,且不采用1×1卷积的综合效果最好:

4 HPM + FC
self.bin_num = [1, 2, 4, 8, 16] # 水平条的尺度
# 全连接层,hidden_dim = 256
# sum(self.bin_num) * 2, 128, hidden_dim = 31 * 2, 128, 256 = 62, 128, 256
# 反向传播过程中,利用该全连接矩阵与最后特征做tensor乘法以实现维度扩展,注意实现参数初始化
self.fc_bin = nn.ParameterList([nn.Parameter(nn.init.xavier_uniform_(torch.zeros(sum(self.bin_num) * 2, 128, hidden_dim)))])
5 参数初始化
for m in self.modules():if isinstance(m, (nn.Conv2d, nn.Conv1d)):nn.init.xavier_uniform_(m.weight.data)elif isinstance(m, nn.Linear):nn.init.xavier_uniform_(m.weight.data)nn.init.constant(m.bias.data, 0.0)elif isinstance(m, (nn.BatchNorm2d, nn.BatchNorm1d)):nn.init.normal(m.weight.data, 1.0, 0.02)nn.init.constant(m.bias.data, 0.0)
6 前向传播过程
6.1 主干网 + MGP
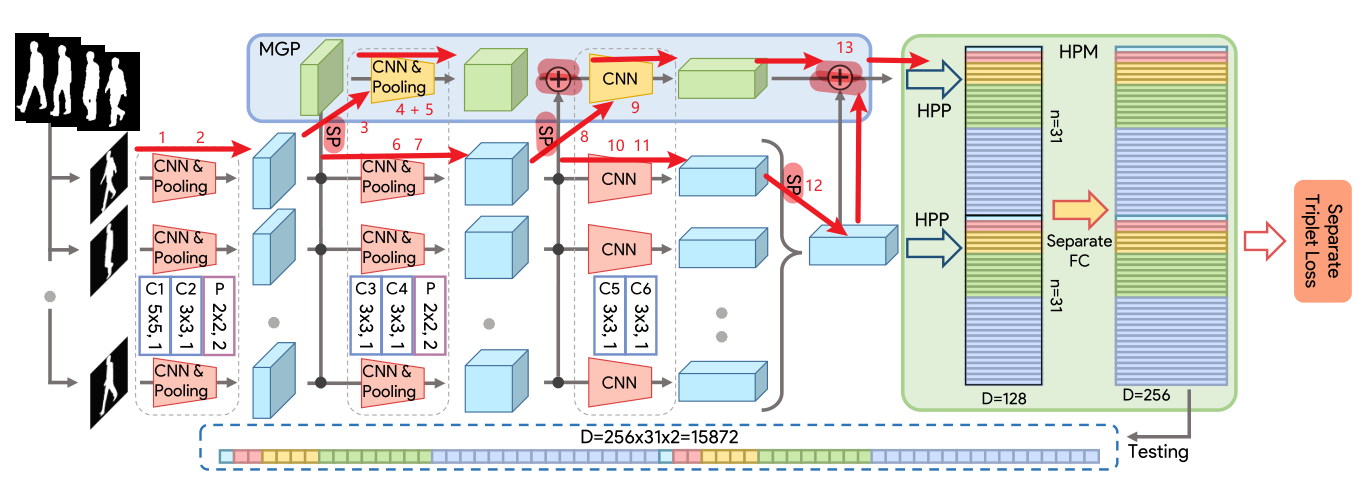
'''bs: batch_size'''x = silho.unsqueeze(2) # [bs, 30, 64, 44] => [bs, 30, 1, 64, 44] 扩展通道# 主干网卷积层1
x = self.set_layer1(x) # 1:[bs, 30, 32, 64, 44] Conv
x = self.set_layer2(x) # 2: [bs, 30, 32, 32, 22] Conv + Pooling# MGP卷积层1
gl = self.gl_layer1(self.frame_max(x)[0]) # 3: [bs, 64, 32, 22] SP + Conv
gl = self.gl_layer2(gl) # 4: [bs, 64, 32, 22] Conv
gl = self.gl_pooling(gl) # 5: [bs, 64, 16, 22] Pooling# 主干网卷积层2
x = self.set_layer3(x) # 6: [bs, 30, 64, 32, 22] Conv
x = self.set_layer4(x) # 7: [bs, 30, 64, 16, 11] Conv + Pooling # MGP卷积层2
gl = self.gl_layer3(gl + self.frame_max(x)[0]) # 8: [bs, 128, 16, 11] SP + Concat + Conv
gl = self.gl_layer4(gl) # 9: [bs, 128, 16, 11] Conv# 主干网卷积层3
x = self.set_layer5(x) # 10: [bs, 30, 128, 16, 11] Conv
x = self.set_layer6(x) # 11: [bs, 30, 128, 16, 11] Conv
x = self.frame_max(x)[0] # 12:[bs, 128, 16, 11] SPgl = gl + x # 13: [bs, 128, 16, 11] Concat
6.2 HPM + FC
feature = list()
n, c, h, w = gl.size() # 8, 128, 16, 11for num_bin in self.bin_num: # 1 2 4 8 16,不同尺度的感受野# 主干网 + HPPz = x.view(n, c, num_bin, -1) # 将长和宽压缩为一维,16*11 => 1,2,4,8,16 # [bs, 128, 1, 176], [bs, 128, 2, 88], [bs, 128, 4, 44], [bs, 128, 8, 22], [bs, 128, 16, 11]z = z.mean(3) + z.max(3)[0] # 第四维度的平均池化 + 最大池化 # [bs, 128, 1], [bs, 128, 2], [bs, 128, 4], [bs, 128, 8], [bs, 128, 16]feature.append(z) # 将水平条放入feature列表# 主干网 + MGP + HPPz = gl.view(n, c, num_bin, -1) # 操作同上z = z.mean(3) + z.max(3)[0]feature.append(z)feature = torch.cat(feature, 2).permute(2, 0, 1).contiguous() # [62, bs, 128] 连接水平条并对换维度
feature = feature.matmul(self.fc_bin[0]) # [62, bs, 256] 使用矩阵乘法实现全连接层
feature = feature.permute(1, 0, 2).contiguous() # [bs, 62, 256] 对换维度,得到最终网络输出
这篇关于GaitSet学习笔记(不包括三元数损失,仅含主干网络)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








