本文主要是介绍图像处理算法:白平衡、除法器、乘法器~笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考:
基于FPGA的自动白平衡算法的实现
白平衡初探 (qq.com)
FPGA自动白平衡实现步骤详解-CSDN博客
xilinx 除法ip核(divider) 不同模式结果和资源对比(VHDL&ISE)_ise除法器ip核-CSDN博客
数字信号处理-04- FPGA常用运算模块-除法器(二)-阿里云开发者社区 (aliyun.com)
【FPGA】:ip核--Divider(除法器)_除法器ip核-CSDN博客
数字信号处理-04- FPGA常用运算模块-除法器_tlast-CSDN博客
目的:还原出真实的白色
色温的概念和示例:
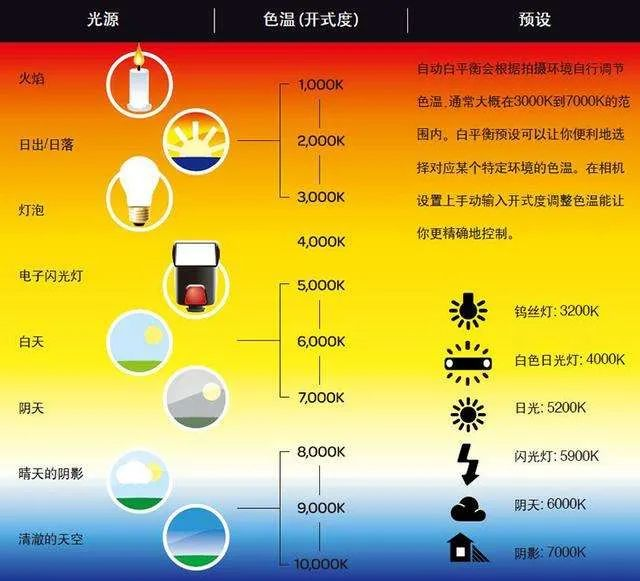
涉及的资源:除法器、乘法器
除法器基本介绍
LUTMult.
Radix-2.
High Radix.
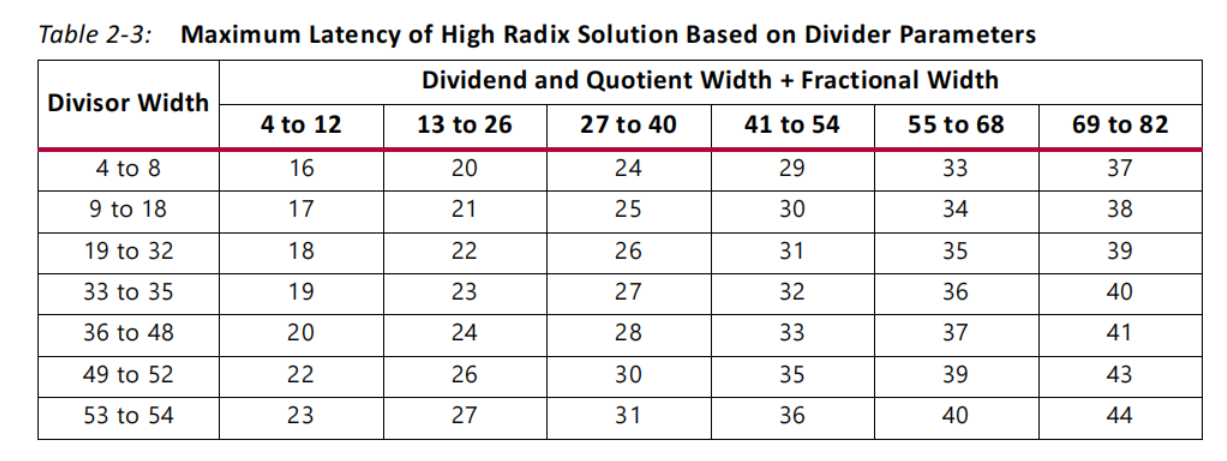
延迟测算
LUTMult
Radix-2
Radix-2 全流水线除法器的延迟(内核生成第一个有效输出之前所需的启用时钟周期数)是被除数位宽的函数。如果需要小数输出,则完全流水线延迟也是小数位宽度的函数。一般来说:

High Radix Solution

除法器配置
Common Options
Describes parameters common to both implementations and allows the selection of the divider implementation.
描述两种实现方式共有的参数,并允许选择分频器实现方式。
• Algorithm Type: This selects between Radix-2, LUTMult and High Radix division solutions.
Radix-2 Options计算频次
Clocks Per Division: Determines the throughput of the Radix-2 solution (interval in clocks between inputs (or outputs)). A low value for this parameter results in high throughput, but also in greater resource use.
每分频时钟数:确定 Radix-2 解决方案的吞吐量(输入(或输出)之间的时钟间隔)。此参数的值较低会导致吞吐量较高,但也会导致资源使用量增加。
High Radix and LUTMult Options
Number of iterations (High Radix only): Read-only text field that reports the number of iterations performed by the High Radix engine for each divide. This sets the maximum throughput of the divider. To achieve this throughput, the operands must be supplied as soon as requested by the core s_axis_dividend_tready and s_axis_divisor_tready outputs.
迭代次数(仅限高基数):只读文本字段,报告高基数引擎为每次划分执行的迭代次数。这设置了分频器的最大吞吐量。为了实现此吞吐量,必须在核心 s_axis_dividend_tready 和 s_axis_divisor_tready 输出请求时立即提供操作数。
Throughput (High Radix only): Read-only text field that reports the maximum throughput that can be sustained by the divider when operands are supplied at a constant rate. In AXI blocking modes, throughput might be slightly higher due to Send Feedback Divider Generator v5.1 26 PG151 February 4, 2021 www.xilinx.com Chapter 4: Design Flow Steps buffering. This rate applies when FlowControl is set to NonBlocking and the output channel DOUT has no tready.
吞吐量(仅限高基数):只读文本字段,报告以恒定速率提供操作数时分频器可以维持的最大吞吐量。在 AXI 阻塞模式下,由于发送反馈分频器生成器设计流程步骤缓冲,吞吐量可能会稍高。当FlowControl 设置为NonBlocking 并且输出通道DOUT 没有tready 时,适用此速率。
Common Options
Detect Divide-by-Zero: Check box. Determines if the core has a DIVIDE_BY_ZERO field in the output tuser port (m_axis_dout_tuser) to signal when a division by zero has been performed
检测除零:复选框。确定内核的输出 tuser 端口 (m_axis_dout_tuser) 中是否有 DIVIDE_BY_ZERO 字段,以在执行除以零时发出信号
AXI4-Stream Options
Flow Control: Blocking or NonBlocking. This is more fully explained in AXI4-Stream Considerations in Chapter 3. NonBlocking mode provides an easier migration path from the previous version of the Divider Generator core. Blocking mode eases data flow management to/from other AXI4-Stream blocking mode cores at the expense of some additional resource and latency
流量控制:阻塞或非阻塞。第 3 章中的 AXI4-Stream 注意事项对此进行了更全面的解释。NonBlocking 模式提供了从先前版本的 Divider Generator 核心的更简单的迁移路径。阻塞模式简化了进出其他 AXI4-Stream 阻塞模式内核的数据流管理,但会带来一些额外的资源和延迟
Optimize Goal: This applies only to blocking mode. When ACLKEN is selected and Optimize Goal is set to Resources, performance might be reduced. See Resource Utilization in Chapter 2.
优化目标:这仅适用于阻塞模式。当选择 ACLKEN 并将优化目标设置为资源时,性能可能会降低。请参阅第 2 章中的资源利用。
• Output has TREADY: Selects whether the output channel has a tready signal. This is required to allow back pressure from downstream, for example, if connected to another AXI4-Stream Blocking core. Without tready, downstream circuitry cannot halt dataflow from the divider, but some resource is saved
• 输出有TREADY:选择输出通道是否有TREADY 信号。这是允许来自下游的背压所必需的,例如,如果连接到另一个 AXI4-Stream Blocking 核心。如果没有tready,下游电路无法停止来自分频器的数据流,但可以节省一些资源
Output TLAST Behavior: Selects the source of the output channel tlast signal. When neither or only one input channel has a tlast then the output tlast is not present or derives from the input tlast appropriately. When both input channels have tlast, the output channel tlast can derive from either alone, the logical OR of both inputs, or the logical AND of both inputs.
输出 TLAST 行为:选择输出通道 tlast 信号的源。当没有或只有一个输入通道具有 tlast 时,则输出 tlast 不存在或从输入 tlast 适当导出。当两个输入通道都有 tlast 时,输出通道 tlast 可以单独源自两个输入的逻辑“或”或两个输入的逻辑“与”。
Latency Options配置流水
Latency Configuration: Automatic (fully pipelined) or manual (determined by following field). Latency configuration for Radix2 solution is configurable only when clocks per division is set to 1. This is due to iterative feedback and hence non-optional registers when clocks per division is greater than 1.
延迟配置:自动(完全流水线)或手动(由以下字段确定)。仅当每分频时钟设置为 1 时,Radix2 解决方案的延迟配置才可配置。这是由于迭代反馈,因此当每分频时钟大于 1 时,寄存器是非可选的。
Latency: When Latency Configuration is set to Automatic, this field provides the latency from input to output in terms of clock enabled clock cycles. When Manual, this field is used to specify the latency required. When high performance (clock frequency) is not required, a lower value in this field can save resources
延迟:当延迟配置设置为自动时,此字段以时钟启用的时钟周期提供从输入到输出的延迟。当手动时,该字段用于指定所需的延迟。当不需要高性能(时钟频率)时,该字段的值较低可以节省资源
Control Signals
ACLKEN: Determines if the core has a clock enable input (ACLKEN).
ARESETn: Determines if the core has an active-Low synchronous clear input (ARESETn).
Note:
a. The signal ARESETn always takes priority over ACLKEN, that is, ARESETn takes effect regardless of the state of ACLKEN.
b. The signal ARESETn is active-Low.
c. The signal ARESETn should be held active for at least two clock cycles. This is because, for performance, ARESETn is internally registered before being fed to the reset port of primitives
除法器输出:
Output Channel
• Remainder Type: This selects between remainder types Fractional and Remainder presented on the FRACTIONAL field of the output tdata port (m_axis_dout_tdata). Fractional remainder type is the only option for High Radix.
• 余数类型:在输出tdata 端口(m_axis_dout_tdata) 的FRACTIONAL 字段上显示的余数类型Fractional 和Remainder 之间进行选择。小数余数类型是高基数的唯一选择。
• Fractional Width: If Fractional remainder type is selected, this determines the number of bits provided on the FRACTIONAL field of the output channel (m_axis_dout_tdata). When High Radix is selected, the total output width (quotient part plus fractional part) is limited to 82. The width of the quotient is equal to the width of the dividend and is set in the Dividend channel section. The width of the tuser port is the sum of the present input channel tuser fields plus one if divide_by_zero detect is active. See AXI4-Stream Considerations in Chapter 3 for the internal structure of the tuser port. This channel also has a tlast port if either of the input channels has a tlast port
• 小数类型:
如果选择小数类型,则这个选择将确定输出通道的小数字段上提供的位数(m_axis_dout_tdata)。
当选择 High Radix 时,总输出宽度(商部分加小数部分)限制为 82。商的宽度等于被除数的宽度,并在 Dividend Channel 部分中设置。如果divide_by_zero 检测处于活动状态,tuser 端口的宽度是当前输入通道tuser 字段的总和加一。有关 tuser 端口的内部结构,请参阅第 3 章中的 AXI4-Stream 注意事项。
如果任一输入通道有 tlast 端口,则该通道也有 tlast 端口
TDATA Structure for Output (DOUT) Channel The structure of m_axis_dout_tdata is more complex. This port contains both quotient and, if present, remainder or fractional outputs. When the remainder type is set to remainder, the two outputs are considered separate and so are byte-oriented before being concatenated to make the m_axis_dout_tdata signal. When remainder type is fractional, the fractional part is considered an extension of the quotient so these two fields are concatenated before being padded to the next byte boundary.
输出 (DOUT) 通道的 TDATA 结构 m_axis_dout_tdata 的结构更为复杂。该端口包含商以及余数或小数输出(如果存在)。
当余数类型设置为余数时,两个输出被视为独立的,因此在连接形成 m_axis_dout_tdata 信号之前是面向字节的。
当余数类型为小数时,小数部分被视为商的扩展,因此这两个字段在填充到下一个字节边界之前会被连接起来。
WITH REMAINDER:PAD+QUOTIENT+REMAINDER+PAD
WITH FRACTIONAL PART:PAD+QUOTIENT+FRACTIONAL
这篇关于图像处理算法:白平衡、除法器、乘法器~笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







