本文主要是介绍状态空间模型(SSM)是近来一种备受关注的 Transformer 替代技术,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
状态空间模型(SSM)是近来一种备受关注的 Transformer 替代技术,其优势是能在长上下文任务上实现线性时间的推理、并行化训练和强大的性能。而基于选择性 SSM 和硬件感知型设计的 Mamba 更是表现出色,成为了基于注意力的 Transformer 架构的一大有力替代架构。
近期也有一些研究者在探索将 SSM 和 Mamba 与其它方法组合起来创造更强大的架构。近日,波兰一个研究团队发现,如果将 SSM 与混合专家系统(MoE/Mixture of Experts)组合起来,可望让 SSM 实现大规模扩展。MoE 是目前常用于扩展 Transformer 的技术,比如近期的 Mixtral 模型就使用了这一技术:超越Mixtral 8x7B!Nous | 发布最好的开源 LLM 模型,达到了 SOTA 性能!
这个波兰研究团队给出的研究成果是 MoE-Mamba,即将 Mamba 和混合专家层组合起来的模型。

论文地址:https://arxiv.org/pdf/2401.04081.pdf
MoE-Mamba 能同时提升 SSM 和 MoE 的效率。而且该团队还发现,当专家的数量发生变化时,MoE-Mamba 的行为是可预测的。
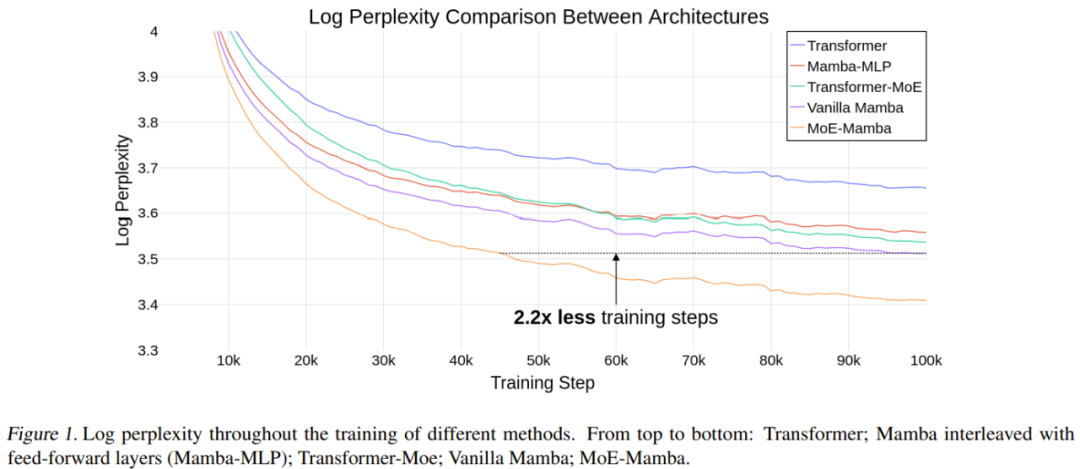
该团队也进行了实验论证,如图 1 所示,结果表明:相比于 Mamba,MoE-Mamba 达到同等性能时所需的训练步骤数少 2.2 倍,这彰显了新方法相较于 Transformer 和 Transformer-MoE 的潜在优势。这些初步结果也指出了一个颇具潜力的研究方向:SSM 也许可以扩展到数百亿参数!
相关研究
状态空间模型
状态空间模型(SSM)是一类用于序列建模的架构。这些模型的思想源自控制论领域,可被看作是 RNN 和 CNN 的组合。尽管它们具有相当大的优势,但也有一些问题,因此难以成为语言建模任务的主导架构。但是,近期的一些研究突破却让深度 SSM 可以扩展到数十亿参数,同时还能维持计算效率和强大的性能表现。
Mamba
Mamba 是基于 SSM 构建的模型,能实现线性时间的推理速度(对上下文长度而言),并且其还通过硬件感知型设计实现了高效的训练流程。Mamba 采用了一种工作高效型的并行扫描方法,可以减轻循环的序列性的影响,而融合 GPU 操作则可无需实现扩展状态。反向传播所必需的中间状态不会被保存下来,而是会在反向通过过程中被重新计算,由此可以降低内存需求。Mamba 优于注意力机制的优势在推理阶段尤其显著,因为其不仅能降低计算复杂度,而且内存使用量还不会取决于上下文长度。
Mamba 能解决序列模型的效率和效果之间的根本性权衡,这就凸显了状态压缩的重要性。高效的模型必需要小状态,而有效的模型所需的状态应当包含上下文的所有关键信息。不同于其它 SSM 对时间和输入不变性的需求,Mamba 引入了一种选择机制,可以控制信息沿序列维度传播的方式。这一设计选择的灵感来自对选择性复制和归纳头等合成任务的直观理解,让模型可以分辨和保留关键信息,同时滤除无关信息。
研究发现,Mamba 有能力高效地利用更长的上下文(长达 1M token),并且随着上下文长度增长,预训练困惑度也会得到改善。Mamba 模型是由堆叠的 Mamba 块构成的,在 NLP、基因组学、音频等多个不同领域都取得了非常好的结果,其性能可以媲美和超越已有的 Transformer 模型。因此,Mamba 成为了通用序列建模骨干模型的一个有力候选模型,参阅:热门!CMU & 普林斯顿 | 提出Mamba新架构,推理速度暴增5倍,完虐Transformer!。
混合专家
混合专家(MoE)这类技术能极大提升模型的参数数量,同时不会影响模型推理和训练所需的 FLOPs。MoE 最早由 Jacobs et al. 于 1991 年提出,并在 2017 年由 Shazeer et al. 开始用于 NLP 任务。
MoE 有一个优势:激活很稀疏 —— 对于处理的每个 token,只会用到模型的一小部分参数。由于其计算需求,Transformer 中的前向层已经变成了多种 MoE 技术的标准目标。
研究社区已经提出了多种方法用于解决 MoE 的核心问题,即将 token 分配给专家的过程,也称路由(routing)过程。目前有两种基本的路由算法:Token Choice 和 Expert Choice。其中前者是将每个 token 路由到一定数量(K)的专家,至于后者则是路由到每个专家的 token 数量是固定的。
Fedus et al. 在 2022 年的论文《Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity》中提出的 Switch 是一种 Token Choice 架构,其是将每个 token 路由到单个专家(K=1),而他们使用该方法将 Transformer 的参数规模成功扩增至了 1.6 万亿。波兰的这个团队在实验中也采用了这种 MoE 设计。
最近,MoE 也开始进入开源社区,比如 OpenMoE。
项目地址:https://github.com/XueFuzhao/OpenMoE
尤其值得一提的是 Mistral 开源的 Mixtral 8×7B,其性能可比肩 LLaMa 2 70B,同时所需的推理计算预算只有后者的约六分之一。
模型架构
尽管 Mamba 的主要底层机制与 Transformer 中使用的注意力机制大不相同,但 Mamba 保留了 Transformer 模型的高层级、基于模块的结构。使用这一范式,由相同模块构成的一层或多层会彼此堆叠在一起,而每一层的输出都会被添加到残差流(residual stream)中,见图 2。之后,这个残差流的最终值会被用于预测语言建模任务的下一个 token。
MoE-Mamba 利用了这两种架构的兼容能力。如图 2 所示,在 MoE-Mamba 中,每间隔一个 Mamba 层就会被替换成一个基于 Switch 的 MoE 前馈层。
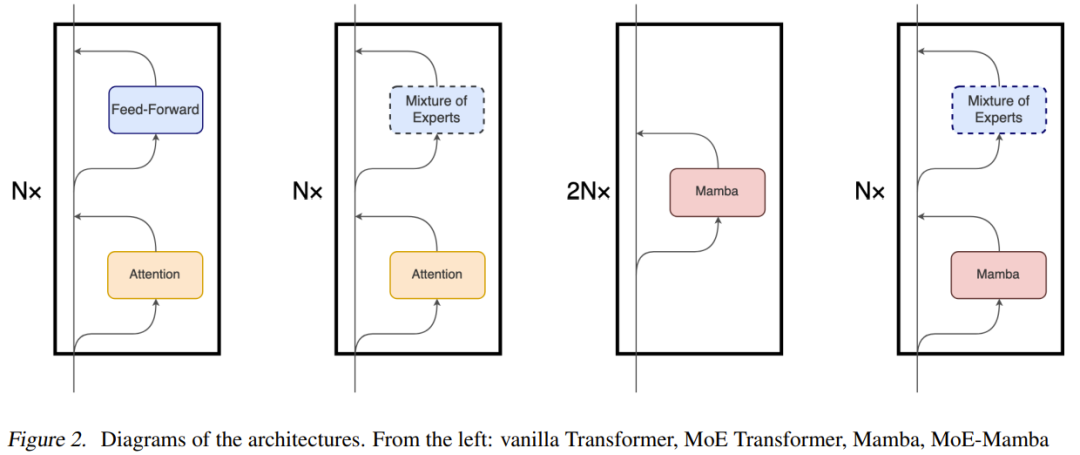
不过该团队也注意到这一设计和《Mamba: Linear-time sequence modeling with selective state spaces》的设计有些相似;后者交替堆叠了 Mamba 层和前馈层,但得到的模型相比于单纯的 Mamba 还略有不及。该设计在图 1 中被记为 Mamba-MLP。
MoE-Mamba 分开了 Mamba 层执行的每个 token 的无条件处理和 MoE 层执行的有条件处理;其中的无条件处理可高效地将序列的整个上下文整合到一个内部表征中,而有条件处理可为每个 token 使用最相关的专家。这种将有条件处理和无条件处理交替起来的思路在一些基于 MoE 的模型中已经得到了应用,不过它们通常是交替基本的和 MoE 的前馈层。
主要结果
训练设置
该团队比较了 5 种不同设置:基本 Transformer、Mamba、Mamba-MLP、MoE 和 MoE-Mamba。
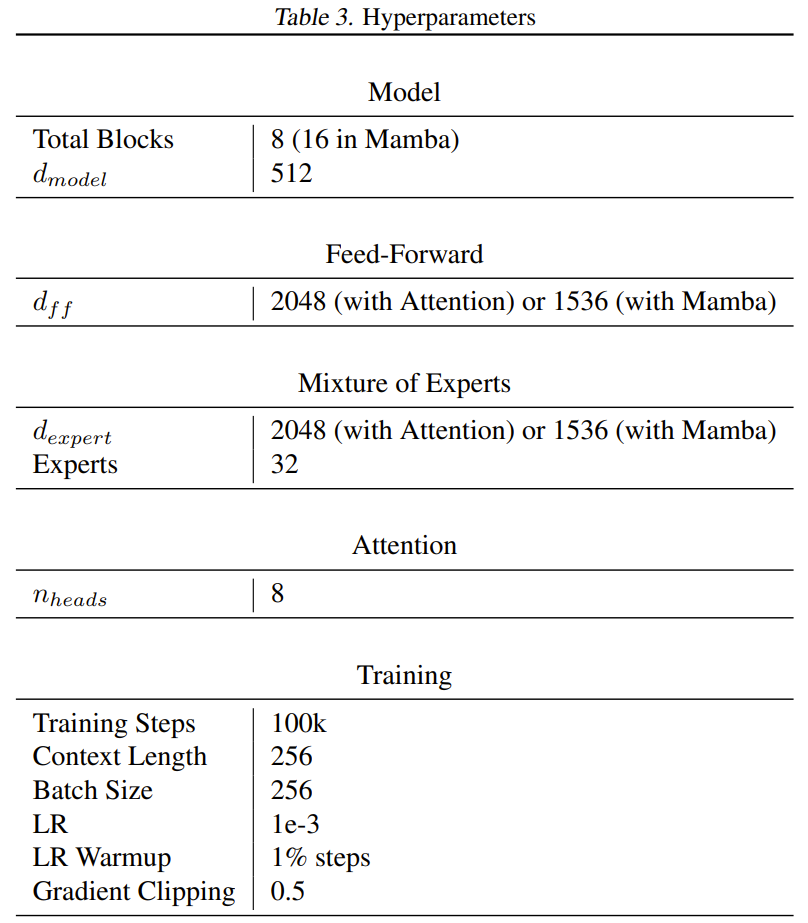
在大多数 Transformers 中,前馈层包含 8dm² 个参数,而 Mamba 论文中则让 Mamba 更小一些(约 6dm²),这样两个 Mamba 层的参数数量与一个前馈层和一个注意力层加起来差不多。为了让 Mamba 和新模型中每个 token 的活动参数数量大致一样,该团队将每个专家前向层的大小缩小到了 6dm²。除了嵌入层和解除嵌入(unembedding)层,所有模型都是每个 token 使用大约 2600 万参数。训练过程使用了 65 亿个 token,训练步骤数为 100k。
训练使用的数据集是 English C4 数据集,任务是预测下一 token。文本的 token 化使用了 GPT2 tokenizer。表 3 给出了超参数的完整列表。
结果
表 1 给出了训练结果。MoE-Mamba 的表现显著优于普通 Mamba 模型。
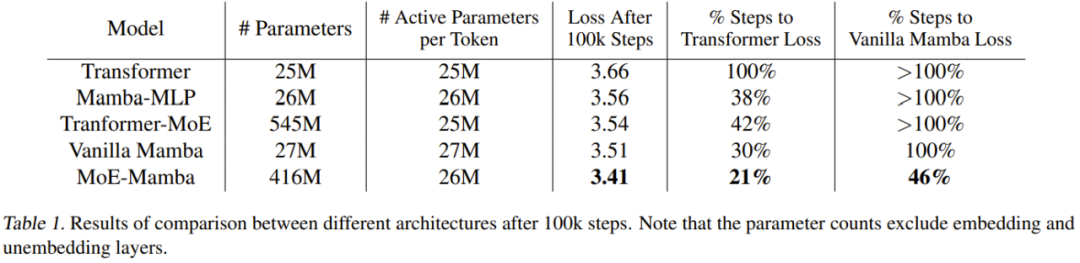
值得注意的是,MoE-Mamba 只用仅仅 46% 的训练步骤就达到了与普通 Mamba 同等的结果水平。由于学习率是针对普通 Mamba 进行调整的,因此可以预计,如果再针对 MoE-Mamba 对训练流程进行一番优化,MoE-Mamba 的表现还会更好。
消融研究
为了评估 Mamba 是否能随专家数量的增长而很好地扩展,研究者比较了使用不同数量专家的模型。
图 3 展示了使用不同数量的专家时的训练运行步骤情况。
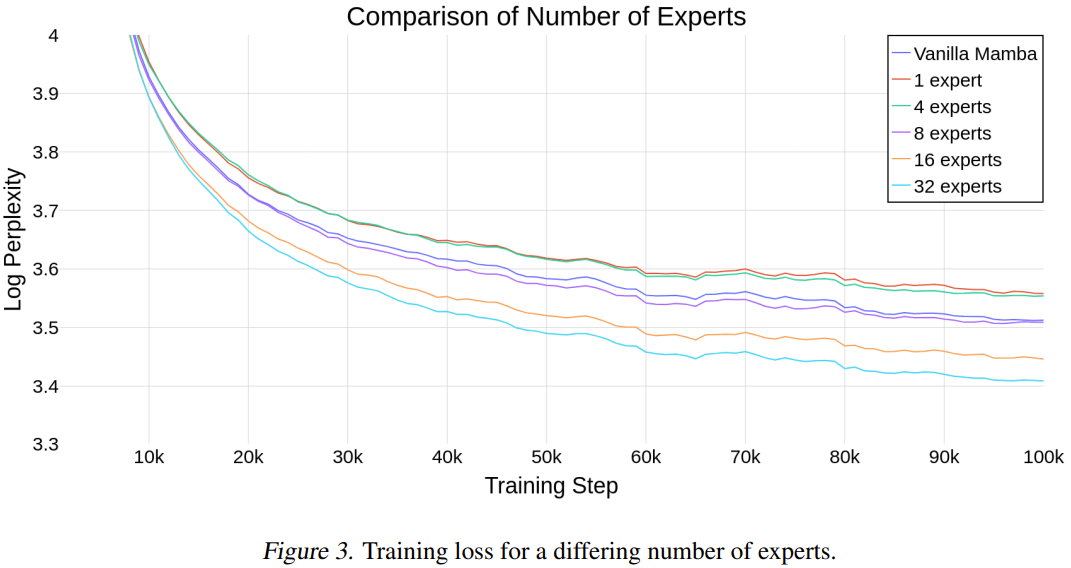
表 2 给出了 100k 步骤后的结果。
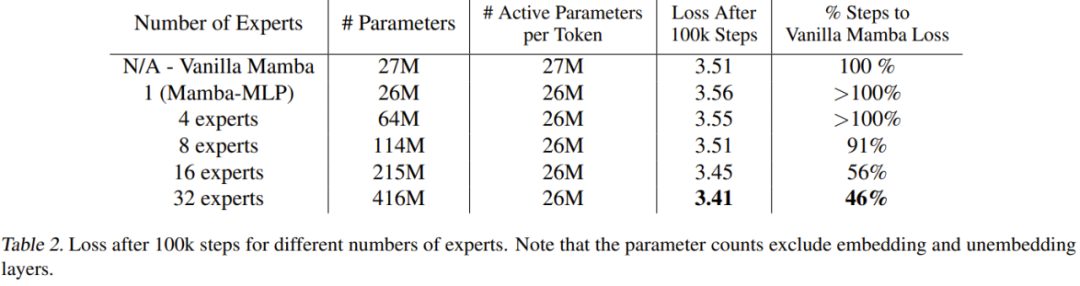
这些结果表明新提出的方法能随专家数量而很好地扩展。如果专家的数量为 8 或更多,新模型的最终性能优于普通 Mamba。由于 Mamba-MLP 比普通 Mamba 差,可以预见使用少量专家的 MoE-Mamba 的性能表现会比 Mamba 差。当专家数为 32 时,新方法得到了最佳结果。
这篇关于状态空间模型(SSM)是近来一种备受关注的 Transformer 替代技术的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






