本文主要是介绍《论文阅读》Poisson Surface Reconstruction for LiDAR Odometry and Mapping,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
留个笔记自用
Poisson Surface Reconstruction for LiDAR Odometry and Mapping
做什么
Lidar Odometry激光雷达里程计,里程计作为移动机器人相对定位的有效传感器,为机器人提供了实时的位姿信息。移动机器人里程计模型决定于移动机器人结构和运动方式,即移动机器人运动学模型。
简单来说,里程计是一种利用从移动传感器获得的数据来估计物体位置随时间的变化而改变的方法

用建图的方式来理解,要实现机器人的定位与导航,就需要知道机器人走了多远,往哪走,也就是初始位姿和终点位姿,只有知道了里程计,才能准确将机器人扫描出来的数据进行构建。
做了什么
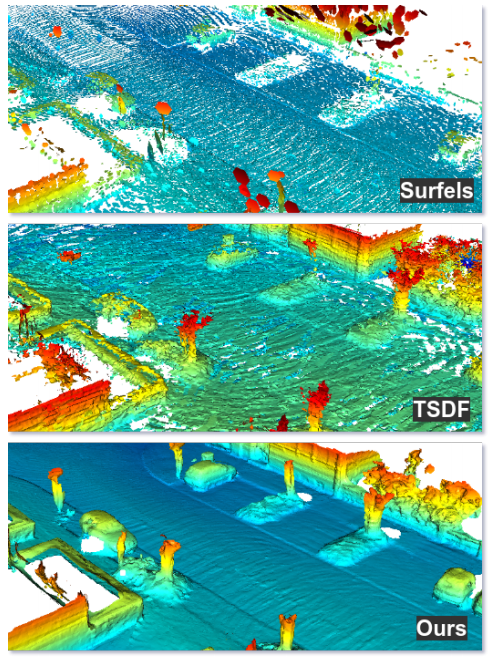
这里的方法是将地图表示为通过泊松表面重建计算的三角形网格,在一系列过去的扫描中以滑动窗口的方式执行表面重建,可以获得非常精确的局部地图,这种地图是环境的几何精确表示
怎么做
整体过程分为三步,输入是一个整体的点云集,第一步,计算逐点法向量,第二步,将扫描点云注册(register,也可以称为点云配准)到分别的局部地图上,第三步,将注册的扫描融合到全局地图上
首先是第一步,逐点法向量计算
这里采用的方法是将点云集球面投影至2D平面,就像大多数Odometry论文做的Range-Image一样,然后在2D层次上与上下左右邻域计算cross product也就是叉乘得到各点法向量结果
然后是第二步和第三步,局部点云配准和全局地图,这是文章的核心
这里采用的方法是迭代进行点云集的点云与三角形网格的数据进行数据关联来确定匹配对应关系,采用的关联方法是ray-triangle也就是射线三角形网格交点的方法,具体方法是这样的
首先对于时间帧t-1和t,将估计的位姿转换Tt-1∈R4×4应用在t-1帧上。将现在的扫描作为初始对准,构造N个射线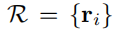
每个ri为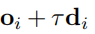
其中
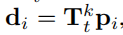
这里的o是模拟原点,模拟的是估计的传感器位置,d是传感器方向,pi是现在这个扫描中的所有点,Ttk是第k个迭代的预测位姿转换,ttk∈R4是大T的平移部分,简单来说就是以估计传感器位置为原点,从原点射出n条射线传过这n个点,而这个估计是迭代式的,是由每次估计的位姿转换得到的
将每条射线(经过每个点云的点的射线)与三角形网格的交点设置为qi,法线设置为ni,然后就可以设置loss去计算扫描和网格之间的相对转换
然后再做一下离群点剔除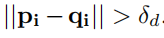
简单来说就是防止射线与三角形网格的交点过远或者直接没有交点的情况
最后就是设置优化目标
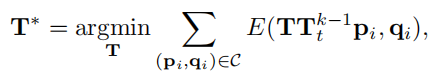
这里的E()就是前面有提到的相对转换误差,这里的设计方法有很多,文中提到的比如论文《A Method for Registration of 3D Shapes》中的,论文《Efficient variants of the ICP algorithm》中的,具体的就不做了解了,只要了解大致用处就行。
这里的pi和qi设计与前面相同,点与点对应的网格交点,C则是表示属于这个对应关系(离群点剔除之后)
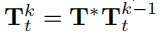
也就是第k个迭代得到的位姿转换,简单来说这里的意思就是,根据当前迭代得到的位姿转换转换点p,最小化每个点p和其对应的交点q的Point-Plane误差
然后是最核心的部分,三角形网格的构造方法
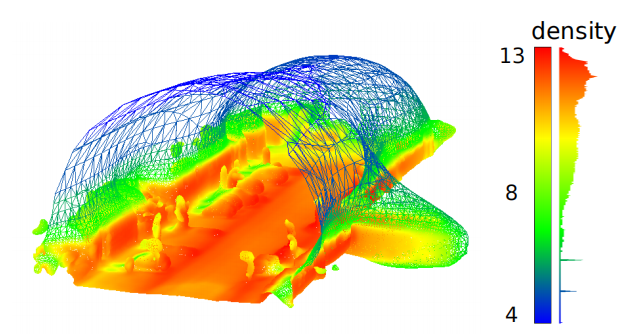
常见的三维表面重建的方法是建立一个函数f(R3->R),这个函数的作用就是找点数据的底层表面,这里采用的是泊松表面重建,这种方法借鉴了之前的论文《Screened poisson surface reconstruction》
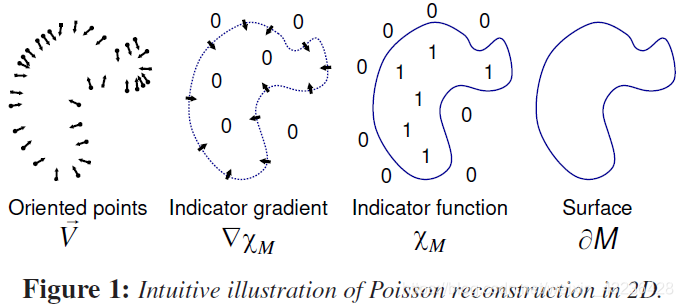
具体的方法论文里没有提到,就说反正这么用了,需要更加深入研究的是这个网格在SLAM中的使用,就略过了
接下来针对泊松重建做了一些改进,由于该文用到的部分数据集是外部数据集,外围空间不存在完整的封闭表面,但泊松重建是对每个点恢复表面,所以可能出现天空也被重建成封闭的情况,这种情况需要避免
这里采用的方法很简单,对于网格上的顶点v计算它的密度,也就是在原点云中有多少个点是支持这个重建的表面顶点的,根据密度进行筛选,也就是这里的深度图
这里还提到了有趣的一点,这种密度图的方法还过滤掉了场景中的动态对象,由于移动对象表面上的3D点通常只支持少量的网格点,是因为每次扫描表面位置均会产生变化,而这些低密度点就不会给它重建表面
最后是局部地图和全局地图的方法
这里的方法是将N次最近的扫描构建局部地图,全局仅用于可视化,在最初的N次扫描中禁用网格重建模块,依靠点到面的ICP去估计位姿,然后再每N次扫描配准后更新全局网格
总结
1.主要方法就是用了泊松重建,用构造逐点射线和三角形网格交点的方法去进行位姿优化,挺好的一种方法
2.文章没有用到太多DL的方法,之类的重建和交点设计是否可以用到DL,这是一个值得考虑的问题
这篇关于《论文阅读》Poisson Surface Reconstruction for LiDAR Odometry and Mapping的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
