本文主要是介绍客户案例:EDLP助力金融行业打造高效数据防泄露体系,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
客户背景
某金融机构是一家以金融科技为核心,致力于为客户提供全方位、智能化、便捷化金融服务的综合性企业。公司总部位于南京,业务范围覆盖全国,拥有强大的技术研发团队和优秀的业务精英,为客户提供全方位的金融服务解决方案。
客户需求
随着《数据安全法》和《个人信息保护法》等法律法规的正式实施,金融行业的数据安全监管得到了进一步加强。在此严格的监管环境下,金融行业更加重视数据应用的安全性和合规性,以满足相关法规要求。
自被某大型银行收购以来,该金融机构始终严谨遵守上级单位的要求,同时提高了邮件安全级别,以确保符合相关法规。
如何有效应对数据安全挑战
数据防泄漏是保障数据安全的关键措施之一,因其功能及产品特性的差异,可分为多个不同类别。其中Coremail在22年推出的CACTER邮件数据防泄露产品(简称“CACTER-EDLP”),专注于邮件领域的数据泄露防护,能够有效预防并阻止有意或无意的邮件数据泄露行为,保障企业数据安全。
尤其是金融行业,客户个人信息、证券交易数据和保险业务等,涉及的都是非常敏感的数据,必须对邮件外发、域内互发的行为进行严格管控,实现金融数据安全全方位保护。
1、审批制度:邮件敏感性检测
EDLP支持对外发、域内邮件进行审批,可以很大程度上减少员工误操作或恶意泄露的行为。
通过附件解析引擎和图片OCR引擎的配套使用,可以实现对文档内容的全面检测,系统一旦发现邮件违规传输敏感数据的情形,便会触发邮件审批管控机制,揭露涉及敏感内容的部分,及时进行阻断并通知相应审批人。
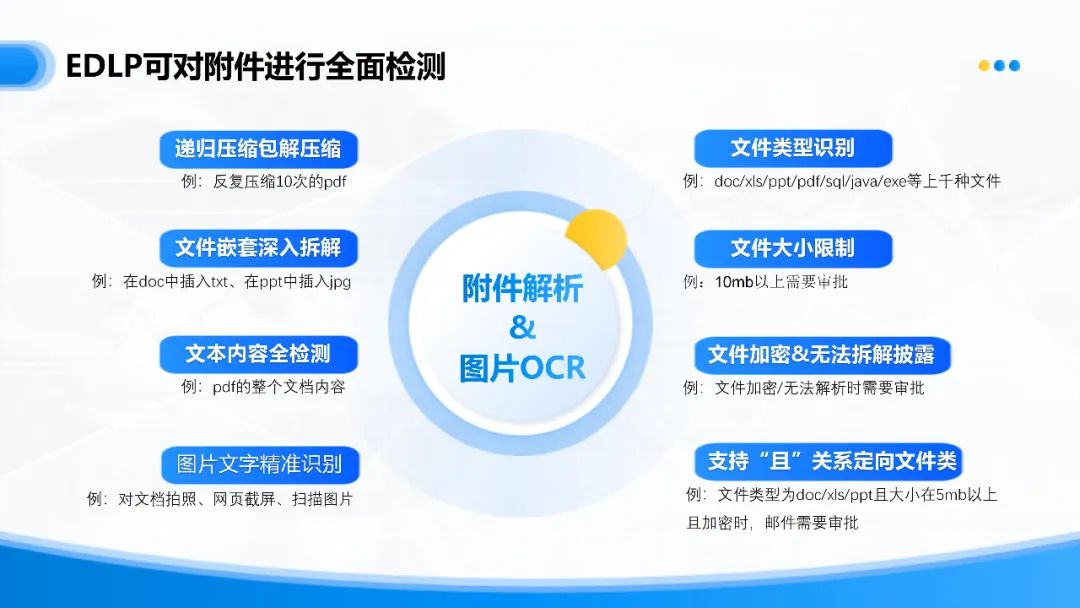
2、灵活设置:邮件审批自定义
同时,EDLP给予管理员高度自定义的系统操作权限管理,以满足各种管理需求。比如:管理员可以设置多级审批和各级审批人,也可以添加发件人自审批的环节,通过二次检查确认来提高审批的准确性和安全性。
此外,根据业务需求,管理员可以选择实时审批或批量审批。对于频繁发送邮件的账号,使用批量审批可以按照时间频率进行集合审批,从而提高审批效率。
更提供多项审批业务保护策略,包括审批超时提醒、超时未审批时的跳过或拦截、未分组员工的默认分组等。这些功能能够为整体的审批流程提供保护,确保审批业务的顺利进行。
3、邮件交互:审批流程简洁化
EDLP不仅能够维护审批数据和审批结果的安全性,还提供更灵活、便捷的审批流程,满足各种不同的业务需求。
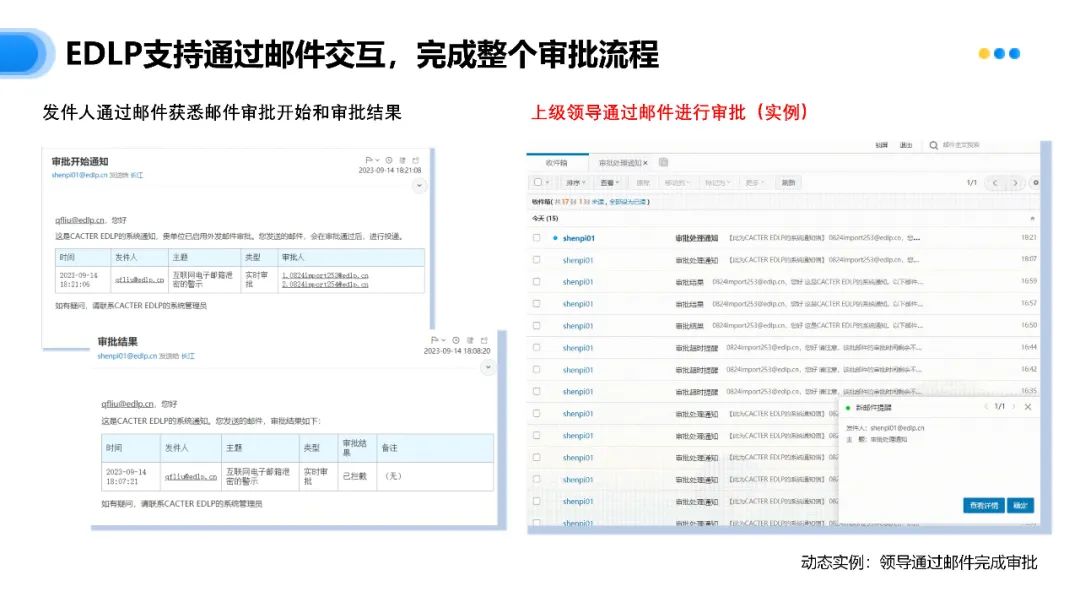
发件人可以通过邮件随时追踪审批进度,上级领导也能直接在邮件中完成审批操作,无需跳转至其他平台,大大提高了审批效率。这无疑为企业管理者减轻了审批工作带来的负担,使他们能够将更多的时间和精力投入到其他重要工作中。
客户评价
该金融机构对EDLP邮件审批全流程表示非常满意,他们认为EDLP显著提高了审批过程的效率,并且灵活自定义审批设置使整个审批流程更加规范和精准。同时,EDLP保障了信息安全和隐私保护,让该金融机构能够更加安心地进行内部沟通和为客户提供服务。
在满足合规需求的前提下,CACTER-EDLP可以有效增强金融机构的安全防护能力,保障敏感数据的安全性和机密性,降低数据泄露的风险,提高整体安全水平。这将为金融行业营造一个安全可靠的网络环境,”主动防御“愈发严峻的恶意邮件攻击,同时也有助于促进金融行业的稳定发展。
这篇关于客户案例:EDLP助力金融行业打造高效数据防泄露体系的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






