本文主要是介绍【20210924】【机器/深度学习】基于亚洲球队数据,讲解K-Means算法原理和 Python 函数库使用方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、问题
下面整理了 2015-2019 年亚洲球队的排名,如下表所示。其中 2019 年国际排名和 2015 年亚洲杯排名均为实际排名。2018 年世界杯中,很多球队没有进入到决赛圈,只有进入到决赛圈的球队才有实际的排名。如果是亚洲区预选赛 12 强的球队,排名会设置为40;如果没有进入到亚洲区预选赛 12 强,球队排名会设置成 50。
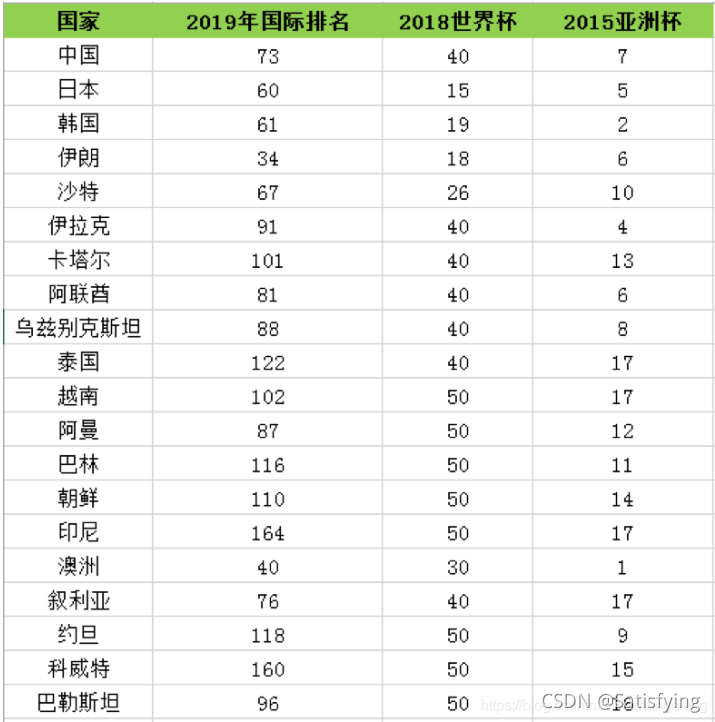
数据集:cystanford kmeans实战图片及代码 31804b9
(参考:白话机器学习算法理论+实战之KMearns聚类算法)
基于亚洲球队数据集,按照成绩划分成 3 个等级,此时可以使用聚类算法实现,这里介绍 K-Means 算法的原理和使用方法。
二、算法原理
K-Means 是一种非监督学习,解决的是聚类问题。K 代表的是 K 类,Means 代表的是类中心。K-Means 算法的目标是:使类内差异最小化,使类间差异最大化。
【算法步骤】
第一步:首先选取 K 个类中心点,一般是随机抽取的;
第二步:计算其余样本点距 K 个中心点的距离(常用欧氏距离),将每个点分配到最近的类中心点,这样就初步形成了 K 个类;
第三步:重新计算每个类的中心点(常用取平均值);
重复第二步和第三步,直到迭代结束。
迭代结束的条件通常有两个:(1)达到最大迭代次数;(2)类不再发生变化。
三、代码实现
'''功能:基于亚洲球队数据,使用 K-Means 算法做聚类
'''import numpy as np
import pandas as pd
import scipy.io as scio
from sklearn.cluster import KMeans
from sklearn import preprocessing# 导入数据
data = pd.read_csv('data.csv', encoding='gbk')
myData = data[['2019年国际排名', '2018世界杯', '2015亚洲杯']]# 对数据进行 min-max normalization 归一化
min_max_scaler = preprocessing.MinMaxScaler()
myData = min_max_scaler.fit_transform(myData)# 训练模型并预测
kmeans = KMeans(n_clusters=3)
kmeans.fit(myData)
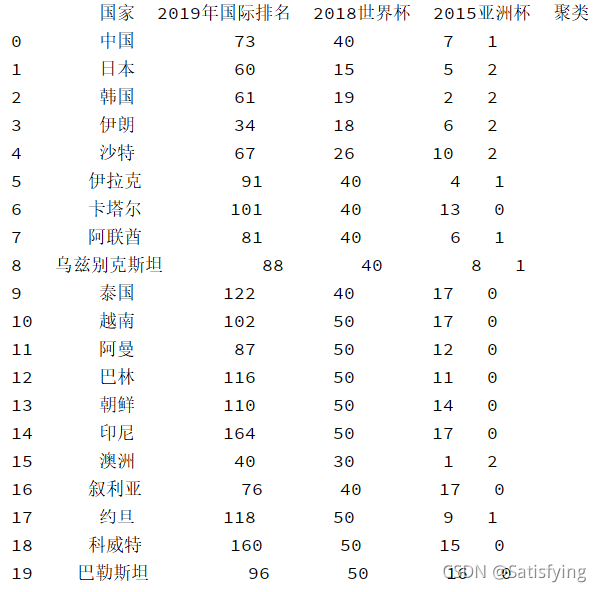
labels_pre = kmeans.predict(myData)# 合并聚类结果,插入到原数据中
result = pd.concat((data, pd.DataFrame(labels_pre)), axis=1)
result.rename({0:u'聚类'}, axis=1, inplace=True)
print(result)运行结果:
四、K-Means 算法的优缺点
1. 优点:
(1)原理简单,容易实现,收敛速度快;
(2)聚类效果较优;
(3)算法的可解释性强
(4)参数少,只有一个簇数 k 需要调。
2. 缺点:
(1)K 值选择不容易;
(2)对于非凸数据集较难收敛;
(3)如果各隐含类别的数据不平衡,则聚类效果不佳;
(4)最终结果和初始点的选择有关,容易陷入局部最优
(5)对噪声和异常点比较敏感。
(参考:K-means原理、优化及应用)
五、Python 函数库参数详解
KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distance='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm='auto')# n_cluster:即 k 值;
# max_iter:设置最大的迭代次数,如果聚类很难收敛,设置最大迭代次数可以及时得到反馈结果,否则程序运行时间会很长;
# n_init:初始化中心点的运算次数,程序会运行 n_init 次,取其中最好的作为初始的中心点;
# init:初始值选择方式;
# algorithm:k-means的实现算法,有 auto, full(传统的k-means), elkan 三种。(参考:白话机器学习算法理论+实战之KMearns聚类算法)
(参考:sklearn kmeans 聚类中心_数据分析|k-means聚类原理)
六、K-Means 算法和 KNN 算法的联系和区别
1. 联系
两者都包含给定一个点,在数据集中找离它最近的点这一步骤,也都用到了 NN(Nears Neighbor) 算法。
2. 区别
(1)K-Means 是聚类算法,而 KNN 是分类算法;
(2)K-Means 是无监督学习(数据集不带标签),而 KNN 是分类算法(数据集带标签);
(3)K-Means 有前期的训练过程,而 KNN 没有明显的前期训练过程,属于 memory-based learning;
(4)K-Means 算法的参数 K 是类别个数(物以类聚,人以群分),而 KNN 的参数 K 是邻居个数(近朱者赤,近墨者黑)。
(参考:K-means原理、优化及应用)
(参考:sklearn kmeans 聚类中心_数据分析|k-means聚类原理)
(参考:KNN与K-Means的区别)
七、知识点
1. pd.concat() 的使用
Pandas 数据的拼接可以使用:pd.concat()。
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)# objs:需要连接的对象,例如:[df1, df2]
# axis:axis=0 表示纵向拼长,axis=1 表示横向拼长;
# join:'outer' 表示 index 全部需要,'inner' 表示只取 index 重合的部分;
# join_axes:传入需要保留的 index;
# ignore_index:忽略需要连接的 frame 本身的 index;
# keys:可以给每个需要连接的 df 一个 label。(参考:pd.concat() Pandas 数据的拼接)
2. 使用 df.rename() 修改 dataframe 的列名
DataFrame.rename(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False, level=None)# mapper:映射器(字典值),键表示旧名称,值表示新名称;
# index:索引(字典值),键表示旧名称,值表示新名称;
# columns:列(字典值),键表示旧名称,值表示新名称;
# axis:int 或字符串值,'0'表示行,'1'表示列;
# copy:如果为 True,表示复制基础数据;
# inplace:如果为 True,则在原始 DataFrame 中进行更改;# 返回类型:具有新名称的 DataFrame(参考:Python Pandas Dataframe.rename()用法及代码示例)
(参考:Pandas中DateFrame修改列名 rename的使用方法)
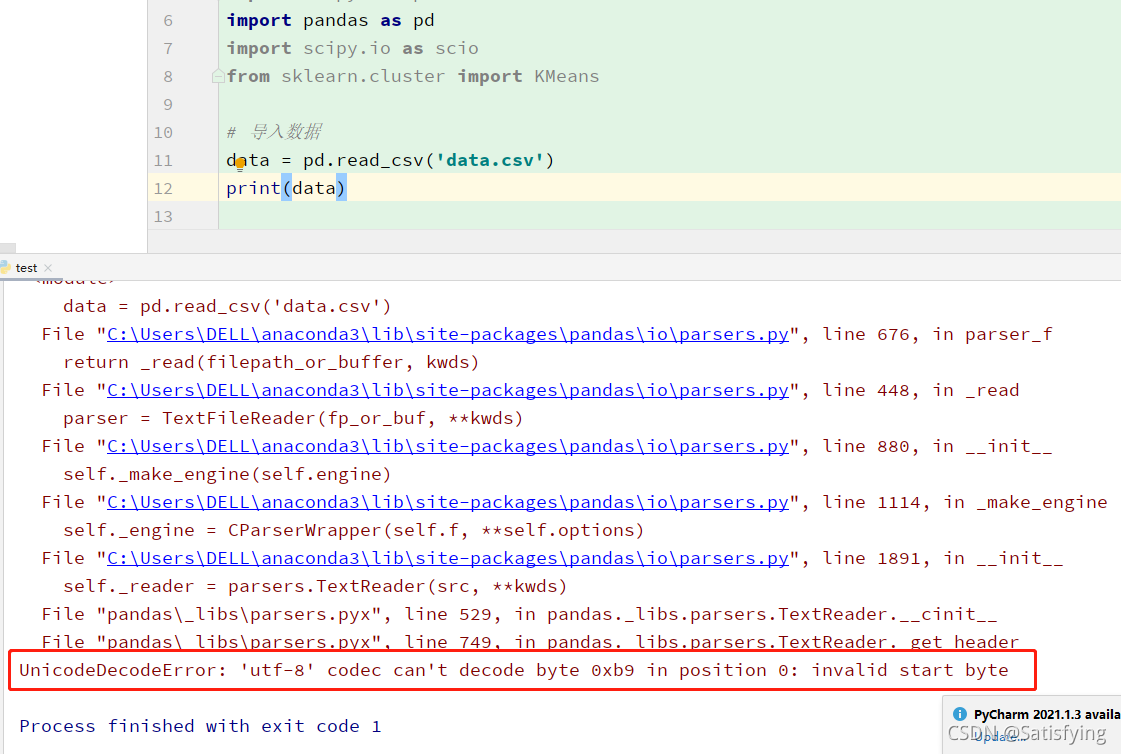
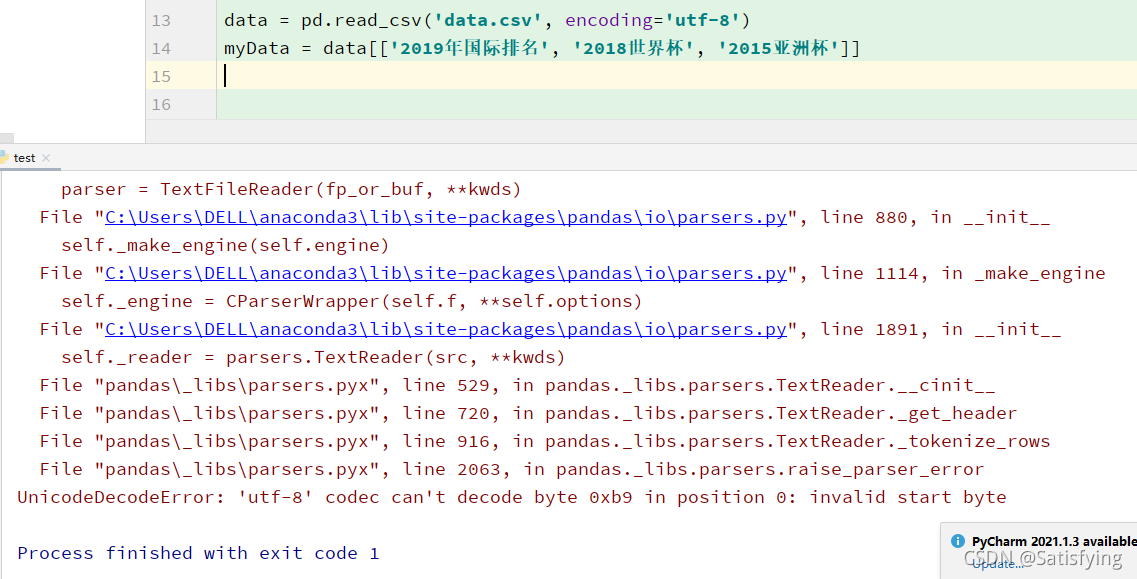
3. pd.read_csv() 时编码问题
当使用 pd.read_csv() 读取 csv 文件时,常常会因为文件中存在中文字符而产生字符编码错误。此时,可以尝试设置 encoding 参数为 'gbk' 或 'utf-8' 或 'utf-8-sig' 。
(参考:pandas中pd.read_csv()方法中的encoding参数)
(参考:pd.read_csv()中encoding='utf-8'和'utf-8-sig'的区别)
这篇关于【20210924】【机器/深度学习】基于亚洲球队数据,讲解K-Means算法原理和 Python 函数库使用方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




