本文主要是介绍大数据工作岗位需求分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:随着大数据需求的增多,许多中小公司和团队也新增或扩展了大数据工作岗位;但是却对大数据要做什么和能做什么,没有深入的认识;往往是招了大数据岗位,搭建起基础能力后,就一直处于重复开发和任务运维的状态;后续大数据人员也做了其他很多工作,仿佛什么都在做,就是不知道集中精力该往哪个方向努力。本文从基础大数据开发岗开始分析,思考大数据工作细分有哪些岗位,分别需要什么能力,以此来提供大数据能力发展方向参考。
一、大数据工作岗位需求分析
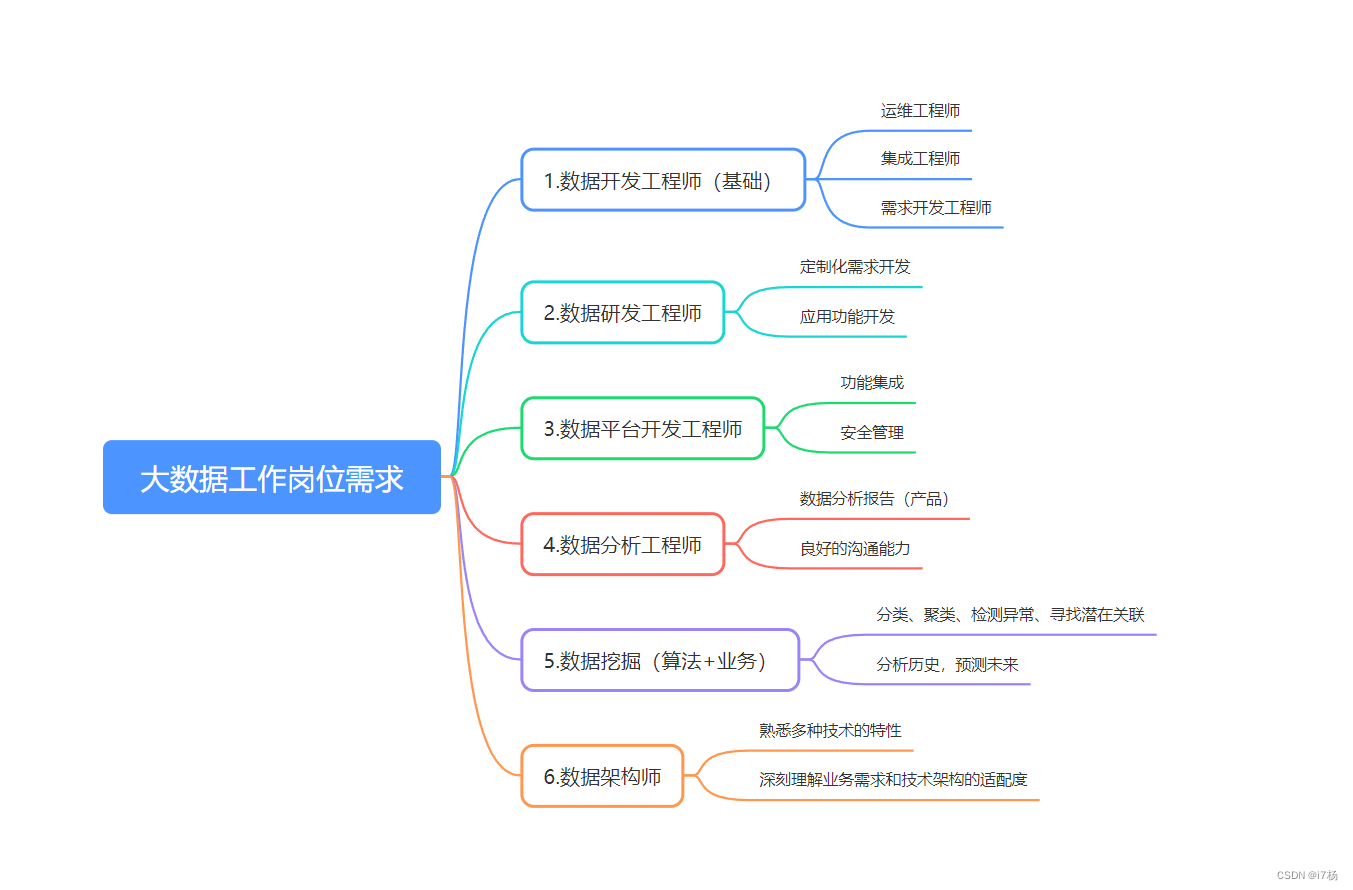
1.1 大数据开发工程师
相信很多公司和团队招聘的第一个大数据岗位就是大数据开发,然后围绕业务或项目需求,搭建大数据能力基础生态。
从零开始的大数据开发,不光要做数据处理,还要兼职实现数据采集,处理,存储,数仓构建,任务调度,监控告警,基础运维这些工作;才能满足大数据开发工程师的生产发布环境。 基础的大数据开发工程师,就是业务和项目需求的实现;理解开源产品应用能力,知道如何基于开源软件的功能实现业务需求就行。
从功能上划分,需要有大数据组件运维工程师,数据集成工程师,大数据开发工程师这几类,很多时候就是一两个人就都做了;
从需求上划分,可分为离线数据开发工程师和实时开发工程师;需要掌握的技术栈有一些区别:
- 离线大数据开发工程师的核心能力是离线数仓理论的掌握,技术栈要理解HIVE、yarn、HDFS、Spark等组件的使用规则和原理;
- 实时大数据开发工程师需要掌握实时数仓的构建生态,处理实时数仓理论,还需要保障任务的处理性能,技术栈需要理解Kafka、Spark-Streaming、Storm、Flink、ES、CK、Doris、StarRocks等,因为面对的场景更复杂,需要掌握数据定制化处理的能力,还需要对各种组件底层架构有了解。
1.2 大数据研发工程师
有些时候,大数据开发工程师会对类似的场景反复开发,相似需求增多后,这类工作就变成了繁琐的重复;这个时候就有一个期盼,希望类似的工作可以更简单的完成,大数据研发工程师的需求就诞生了。
包装一些通用功能,前端页面只需要配置些参数,点击执行就可以,将之前相似场景的需求开发抽象出来,配置化实现。比如:公司使用ES作为存储系统,使用ES做历史数据处理的需求时非常不方便,时常用logstash将数据导出到kafka再做处理;大数据研发,可以基于功能包装配置化功能,把logstash的能力包装到集成页面,配置源端、目标端和选择数据时间范围,填充logstash的任务配置,驱动执行就能实现数据从ES到Kafka这样的能力;或者使用计算框架,比如Flink,将功能包装成SDK或jar包,实现功能性定制化引擎,将任务参数配置暴露出来,然后通过配置化调度,实现功能的需求开发。
1.3 大数据平台开发工程师
将大数据开发和研发的通用能力集成到一起,就是平台工程师要做的事;平台工程师技术栈能力偏向后端,但是因为集成的是大数据场景的需求功能,所以需要到对大数据技术栈有一定的了解。
对大数据平台定位,一些公司叫数据平台,一些叫数据中台。这是有区别的,数据平台是将大数据的应用能力集成到一起,拥有数据处理的能力,侧重于大数据应用技术能力的包装;数据中台更侧重于提供业务数据服务能力,在平台上不一定需要集成各种数据处理的功能,但是需要保障对外提供数据服务的灵活。
大数据平台能力模块细分下来有:多源集成,处理(离线,实时),存储(结构化,半结构化,对象数据),分析,仪表盘看板(UI),数据应用,推送,数据API,数据安全,调度,任务监控,基础资源监控,租户管理,告警管理等。平台能力可以围绕这些包装或建设,一些业务中特殊高频应用的功能,可以让大数据研发工程师做定制化处理,将需求抽象出来做配置化管理。
1.4 大数据分析工程师
这个岗位偏向于沟通和理解,技术要求不高,对人的软实力比较看重;职能通常归属运营和产品经理,但是只能基于认知,做简单的大数据分析,最终需求出来后,对数据分析的应用深度不够;一个资深的大数据分析工程师,能将数据还原成行为,并能指导大数据开发工程师去实现深层次的数据分析;比如基础的数据分析,可能提出的需求就是PV、UV这种维度统计的指标;但是数据分析工程师,能从数据模型里提取出用户之间的关联关系,或者两种行为之间的因果性可能;其主要是研究数据的,对于大数据开发与算法能提供很好的开发思路指导,以及真正价值指标的挖掘。
1.5 数据挖掘工程师
这个岗位的技术要求和业务理解要求会更高,需要对业务理解之外,还需要有数据处理和算法挖掘的技术知识储备;能力结构偏向于分析工程师和算法能力结合的大数据工程师,其可以基于大数据平台,构建特征工程,然后基于特征工程分析潜在的关系或异常;大数据本身对数据处理是擅长的,所以一些这样的工作是建立在大数据开发工程师的特征处理之上,算法工程师再基于特征跑算法模型,大数据工程师理解算法执行原理也可以调用算法模型分析预测;这些结果可能是特征划分、异常检测、分类、聚类、智能决策等;可直接应用在面向市场业务的搜索、推荐、广告系统,或者智能运维的异常检测告警等。
1.6 大数据架构师
随着大数据生态的不断发展,各种应用场景的产品方案鳞次栉比,使用不同的技术方案实现同样业务需求,在易用性、可用性、容错性、稳定性、资源消耗、安全性、各种性能等存在较大的差异;对于各种组件的熟悉,大数据新产品的预研,应用需求的整合与复用,这些都需要有人评估和把关,这就是大数据架构师的工作。
大数据架构师,要对应用各个环节的的设计和实施有经验和深刻理解,比如数据采集、处理、存储、安全、分析、调度,告警等;对各种应用需求场景都熟悉,并对各种技术的应用能力和技术实现架构都有深刻的认识,能指导每种技术方案应用落地,并对各种技术方案的优势和劣势有清晰的认识,能给技术方案劣势兜底;在对应的技术架构上,现阶段市场上各种大数据产品正在快速发展阶段,要解耦应用能力,预留应用整改的口径。
二、各种大数据工作岗位技能要求
将以上大数据岗位能力需求取一个交集,大致可以分为以下几类:
2.1 技术能力
基础技术能力:
对大数据组件的熟悉程度:如Hive、Hbase、Yarn、Spark、Flink、Redis、Kafka、Minio、ElasticSearch、ClickHouse、Doris/StarRocks、Iceberg/Hudi、dolphinscheduler等OLAP和MPP存储系统和计算引擎有生成应用和深入理解; 数据开发,研发能力;
数据管理能力:
熟悉数仓领域知识和管理技能,包括:元数据管理、数据质量、性能调优等;对于不同的存储系统,数据建模的差异也要明白和理解;数据治理能力;大数据工程师基本能力;
功能管理能力:
按照数据集成,数据处理,数据管理,数据开发,数据分析,任务调度,监控告警,数据安全,数据推送,租户管理等能力,集成管理功能; 数据开发、平台工程师的能力;
数据处理和应用:
数据的ETL、开发、建模、分析,以及特征工程的数据处理,核心算法的实现,满足个性化推荐、趋势预测、异常检测、智能运维等数据应用;算法、资深数据研发的核心能力;
编程语言能力:
掌握一门或多门编程语言,如Java、Scala、Pyhron、SQL、Shell等;
数据开发工程师,数据研发工程师,平台开发工程师,数据挖掘工程师,大数据架构师是以上能力集合,掌握深度的递进;
2.2 软实力
经历相关:
学历,本科研究生或工作年限,英语读写、交流等要求限制;
行业相关要求:
互联网、物联网、人工智能、金融、体育、医疗、在线教育、工业、安全、交通、物流、电商等,每个具体的行业还会细分业务领域;这些相关性考量的是入职和团队的融入速度。另外,大户据开发应该比产品更懂业务,大方向上产品和领导愿景一致,但在细节上,开发要有从数据抽象业务的能力,这个能力可以让技术和应用解耦,能在不同的行业按照应用需求落地技术能力;
性格要求:
开创性岗位侧重激情和学习热度;业务功能岗位需要稳重;和外部门沟通多的需要沟通能力;或者领导能力,抗压能力,团队精神、钻研热情等。
三、结语
技术岗位以硬实力为主,能以大数据技术实现生产需求,并能高效和稳定的运行任务,持续产生价值,是大数据岗位的生命线;这些年大数据技术的发展是很快的,能力成长,实践和学习相辅相成,不能沉浸在业务开发里,也不能只学不落地;关注市场开源产品发展的同时,结合具体的业务,从公司需求和业务实际的情况推广应用,确保真正能解决大数据岗位需求面临的痛点问题。
持续成长,持续进步;从技术深度上,让大数据工作更高效和合理;从应用广度上,甚至可以跨界熟悉产品、后端,算法,运维这些原理和工作,这些都会辅助大数据更好的去支撑,优化这些岗位的工作,让大数据应用能力得到更多拓展。
最后,祝愿大家大数据技术更上一层楼,能利用大数据技术解决更多实际中的应用需求。
如果这份博客对大家有帮助,希望各位给i7杨一个免费的点赞👍作为鼓励,并评论收藏一下⭐,谢谢大家!!!
制作不易,如果大家有什么疑问或给i7杨的意见,欢迎评论区留言。
这篇关于大数据工作岗位需求分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






