本文主要是介绍Elastic Stack AIOps Labs 8.12:日志率分析的正式发布,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:来自 Elastic Walter Rafelsberger

Elastic Stack AIOps Labs 8.12 引入了日志率分析的正式版本,该功能使用高级统计方法来确定日志率增加或减少的原因。 该工具可在 Kibana® 的机器学习部分中找到,它简化了识别导致日志率异常峰值或下降的原因的任务:根本原因是堆栈中的特定服务吗? 是否仅限于特定地区? 导致此更改的日志消息之间是否存在共同特征? 从历史上看,解决这些调查需要 SRE 花费大量时间手动比较日志和元数据,以确定日志速率的变化是否代表真正的问题,如果是,则确定其根本原因。 借助 Elastic® 的日志率分析工具,这个繁琐的过程现在被简化为只需几秒钟。
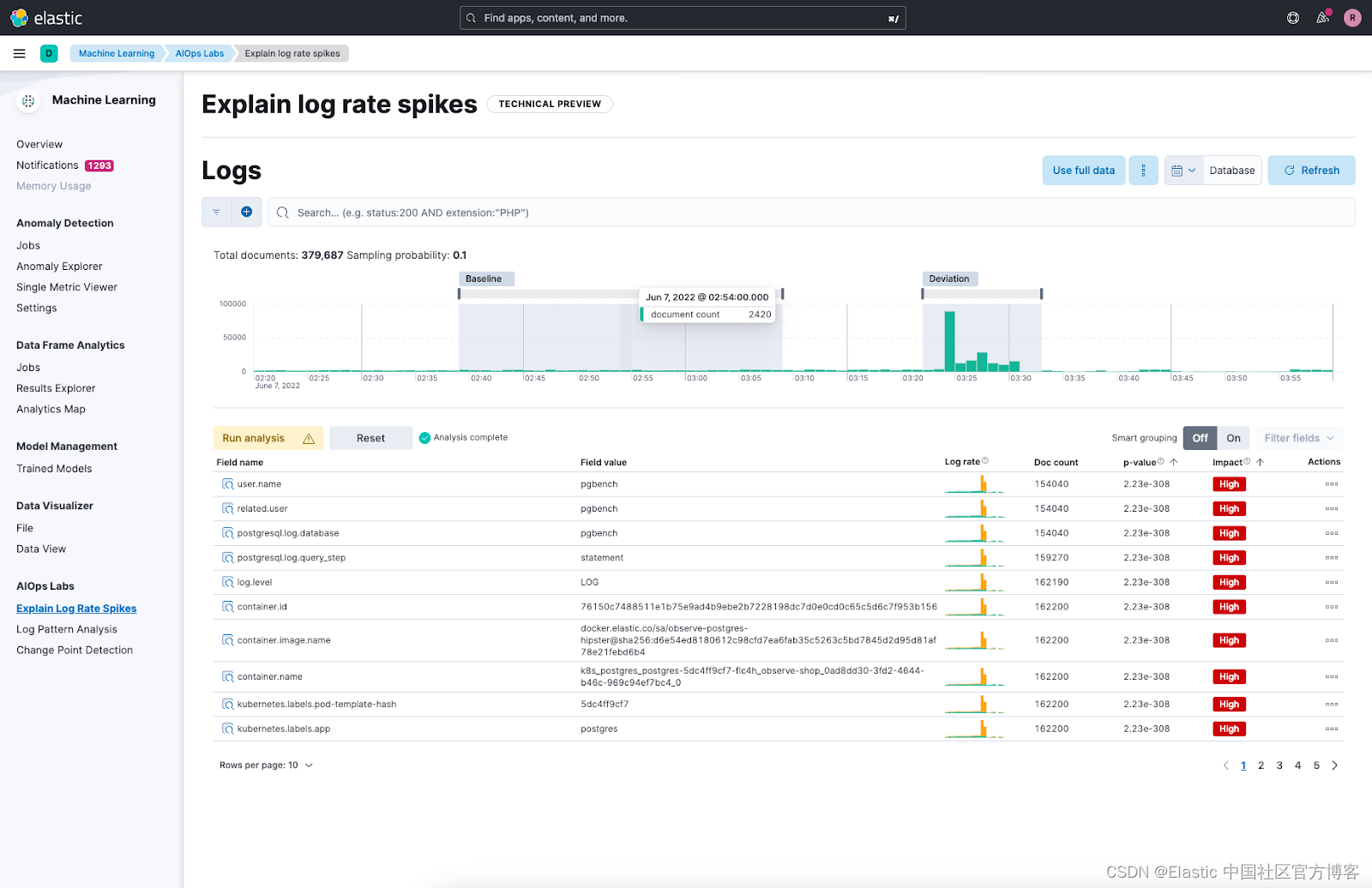
我们最初在 Elastic Stack 8.4 版的技术预览版中发布了该功能,名为 “解释日志速率峰值(explain log rate spikes)”。 在过去的几个月里,我们一直忙于扩展功能集(因此在 8.10 中引入对分析日志下降的支持时,将其重命名为日志速率分析 - log rate analysis),提高其可靠性并使其能够处理越来越大的数据集。
Elasticsearch 支持的 AIOps 功能
经过团队的巨大努力,这个工具才得以投入使用并最终普遍可用。 Elasticsearch® 搜索分析引擎中提供的多项功能对于实现这一目标至关重要:
重要术语聚合的 p_value 评分启发式可以识别日志中具有统计意义的字段/值对。 这种聚合有助于比较这些对与基线日志率的偏差。 它有助于查明哪些字段对偏差影响最大,从而提供初步解释,作为深入研究根本原因的宝贵起点。 例如,在分析网络日志时,它可以识别导致日志激增的源 IP 或 URL。
frequent_item_sets 聚合采用数据挖掘技术,能够在大型数据集中找到频繁且相关的模式。 它作为 Elasticsearch 聚合的实现使其可以作为许多用例的构建块,例如推荐系统、行为分析或欺诈检测。 对于日志率分析,我们使用聚合来识别相关统计显着字段/值对的组。 再次以网络日志为例,这可以使你能够识别哪些类型的用户正在访问某些 URL,从而导致日志活动增加或减少。
最后,random_sampler 聚合使我们能够有效地扩展当今可观察性工作负载的功能。 聚合以统计上稳健的方式对文档进行随机采样,使我们能够在查询时平衡速度和准确性,而不是在提取或汇总数据时必须考虑预先采样的方法。
为 Kibana 内的从业者提供易于使用的用户界面
除了所描述的 Elasticsearch 功能之外,我们还构建了一个易于使用的 UI,作为 Kibana 机器学习部分中 AIOps Labs 的一部分。 第一步是在直方图中选择日志速率峰值或下降。 然后,用户界面使你能够比较偏差和基线选择的结果。 分析结果显示对偏差影响最大的字段及其值,同时支持关键字和非结构化文本类型字段。 然后,你可以通过对结果进行分组和过滤来采取进一步的操作,或者深入使用其他 Kibana 工具(例如 Discover 或日志模式分析)来调查特定结果。

可观察性和 AI 助手集成
日志率分析也集成到 Kibana 的警报系统中,作为可观测性解决方案中创建的阈值警报的警报详细信息页面的一部分。 在此警报视图中,日志率分析是根据警报元数据中的可用信息自动运行的,因此用户无需手动选择偏差和基线时间范围。 在同一页面上,日志率分析的结果作为上下文传递给 Observability 的 AI 助手。 作为此过程的一部分,预构建的提示将发送到你配置的 LLM,你不仅可以获得问题的描述和上下文,还可以获得有关如何继续的一些建议。 此外,你还可以与人工智能助手启动聊天并深入调查。
用于可观察性的 Elastic AI 助手
正如你所看到的,日志率分析本身就是一个强大的工具,但它只是 Elastic 可观测性解决方案中的 AIOps 工具套件的一部分。 要了解更多信息,请查看这些附加日志记录资源:
- 客户为什么选择 Elastic 做日志?
- 使用日志进行根本原因分析:Elastic Observability 的 AIOps 实验室
- 使用 Elastic AI Assistant for Observability 获得情境感知洞察
带有日志的常见用例示例:
- 通过 Elastic Observability 轻松分析 AWS VPC 流日志
- 如何使用机器学习通过 Elastic AIOps 识别 PostgreSQL 日志的日志峰值和模式
准备好开始了吗? 注册 Elastic Cloud 并尝试上述特性和功能。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
原文:Elastic Stack AIOps Labs 8.12: GA of log rate analysis | Elastic Blog
这篇关于Elastic Stack AIOps Labs 8.12:日志率分析的正式发布的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






