本文主要是介绍Meta-Learning with Latent Embedding Optimization (LEO)论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 论文阅读
Meta-Learning with Latent Embedding Optimization该文是DeepMind提出的一种meta-learning算法,该算法是基于Chelsea Finn的MAML方法建立的,主要思想是:直接在低维的表示 z z z上执行MAML而不是在网络高维参数 θ \theta θ上执行MAML。
2. 模型及算法

如图所示,假设执行N-way K-shot的任务,encoder和relation net的输出是一个 2 N 2N 2N个类别独立的高斯分布的参数 z ∈ R n z z \in \mathbb{R}^{n_z} z∈Rnz,即
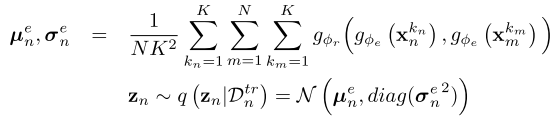
Decoder是一个随机参数生成器,输出的是分类器参数 w n w_n wn,用于对输入 x x x做预测。
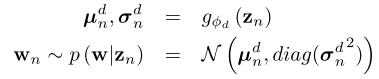
训练过程
- 首先在meta-training set预训练一个28层的WRN-28-10的网络,然后取前21层,并接上global average pooling layer。给定一张图片,输出特征 x ∈ R 640 x \in \mathbb{R}^{640} x∈R640,上图的 D t r D^{tr} Dtr, D v a l D^{val} Dval都是预处理得到的640维特征。
- 内循环:计算在support set上的损失,并只更新z而不是在模型的所有参数上,该过程重复多步。该步骤的目的为在线自适应。
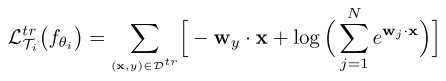
- 外循环:利用上一步内循环得到的分类器参数,计算在query set上的损失,用于更新网络encoder, relation net, decoder。


3. 实验结果

从实验结果可以看出:
- 单独使用了MAML的方法Meta-SGD的效果最差,而使用了Conditional generator only的效果相比单独使用MAML的提升很大,已经接近LEO了,这证明了参数生成方法是这个算法中是最有效的部分。
- 加入了MAML,也就是有fine-tuning的算法,相比没有使用的也有一定的提升。但是,通过对比LEO(no fine-tuning)和LEO(ours),可以发现fine-tuning对结果的影响并不显著。
- 通过对比deterministic及LEO(ours)的结果,似乎表明引入的随机性并不重要。
4. 总结
通过结果发现,最有效的部分似乎不在于低维表示空间的adaptation,也不在于模型引入的随机性,这与论文大篇幅强调的似乎有所出入,总的来说,虽然模型比较臃肿,但该算法本身是比较创新的,也实现了state-of-the-art,是一篇值得研究的论文。
这篇关于Meta-Learning with Latent Embedding Optimization (LEO)论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)