本文主要是介绍编写脚本下载gazebo仿真器公开的模型数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
编写脚本下载gazebo仿真器公开的模型数据集
- 问题描述
- 解决步骤
- 找到url
- 提取 name 和 owner,并格式化 URL
- 编写代码
- 运行效果
问题描述
编写脚本把gazebo仿真器公开的模型数据集中的所有的models和worlds下载收集。每个模型页面有下载链接,不过页面元素是动态生成的,需要用selenium库模拟点击动作。
解决步骤
找到url
进入gazebo官方网站,点击进入
点击models,进入models模块
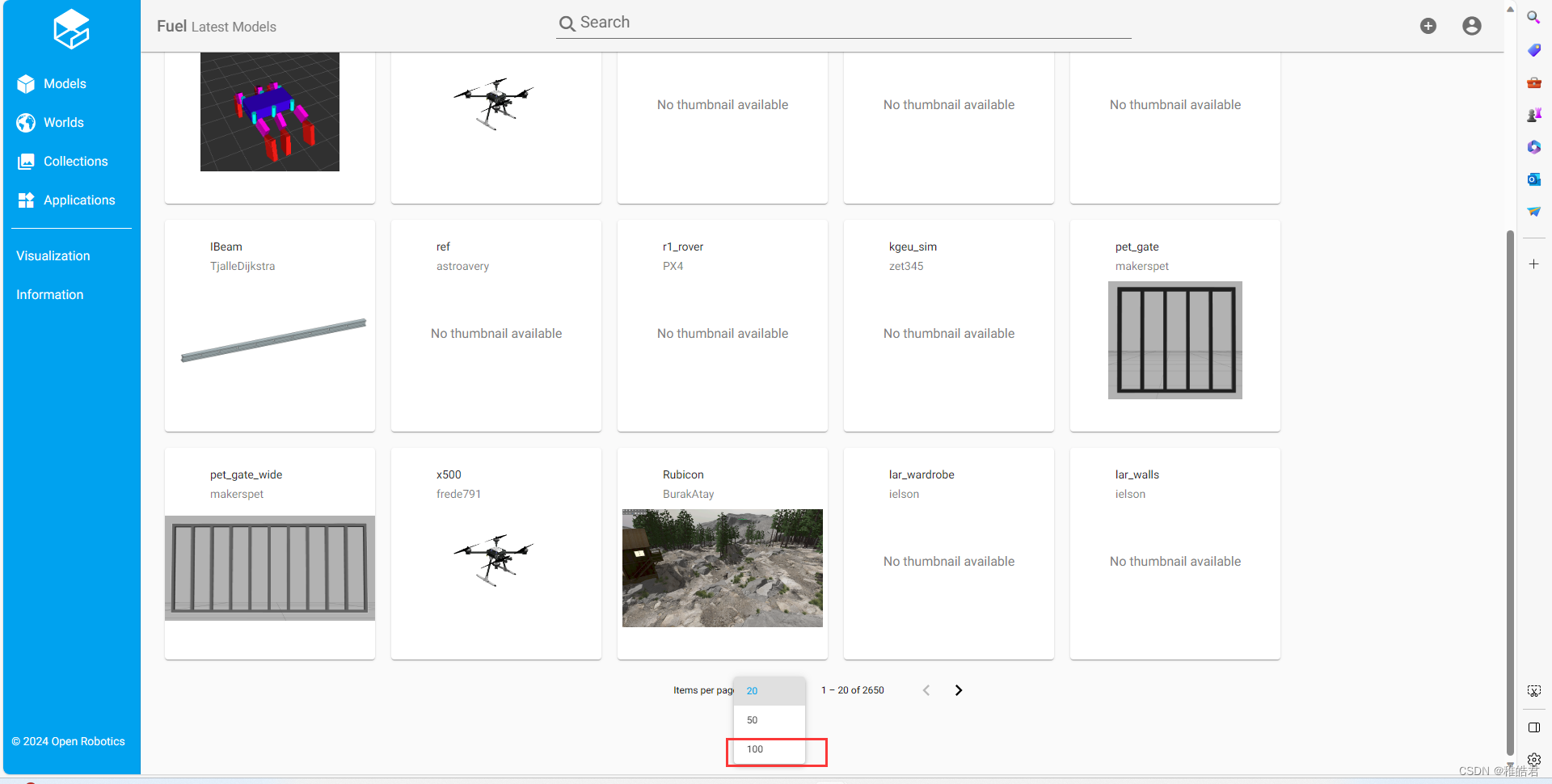
进入models界面后,下拉选择“100”,表示该界面可包含100个模块
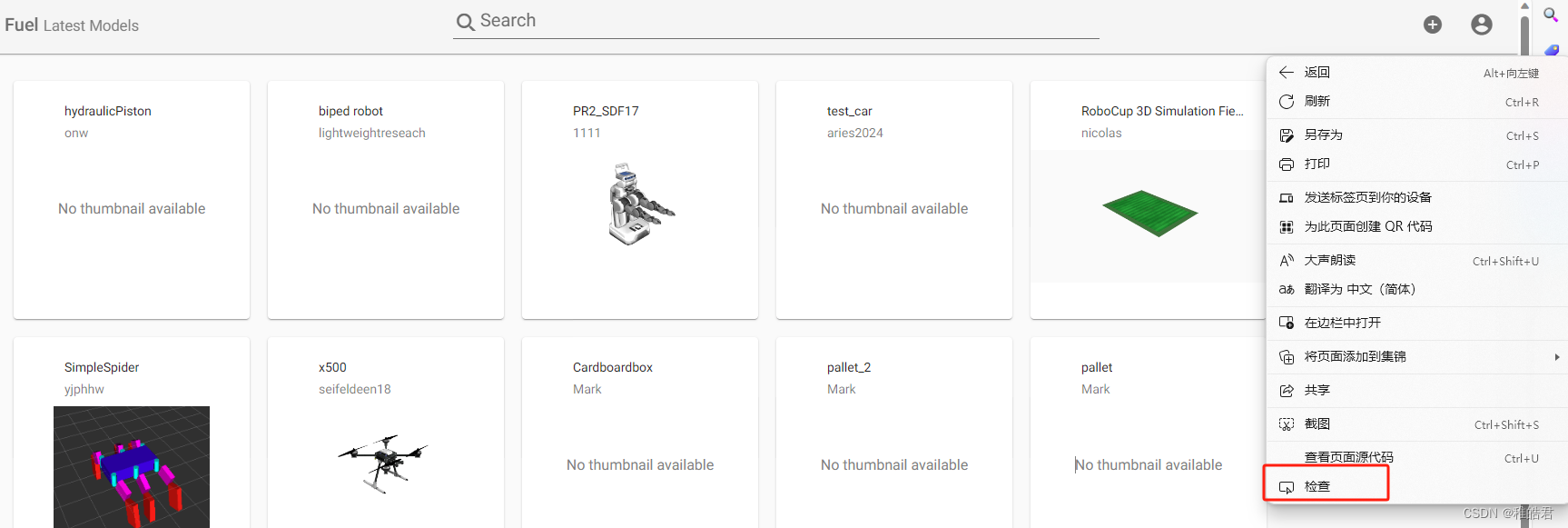
鼠标点击右键,点击“检查”
按图中所示进行点击,随后并按住”CTRL R"进行刷新
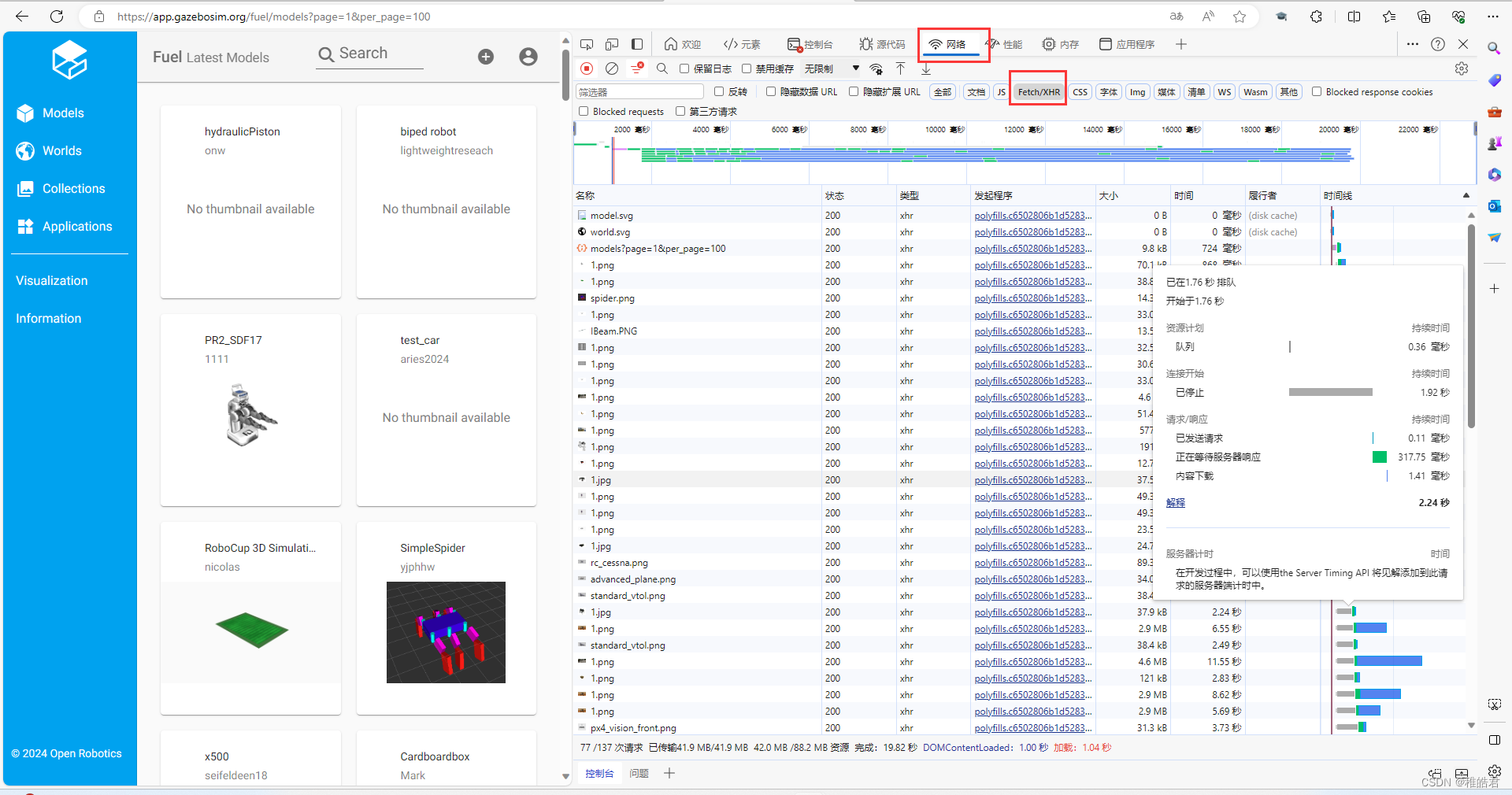
找到url,并复制
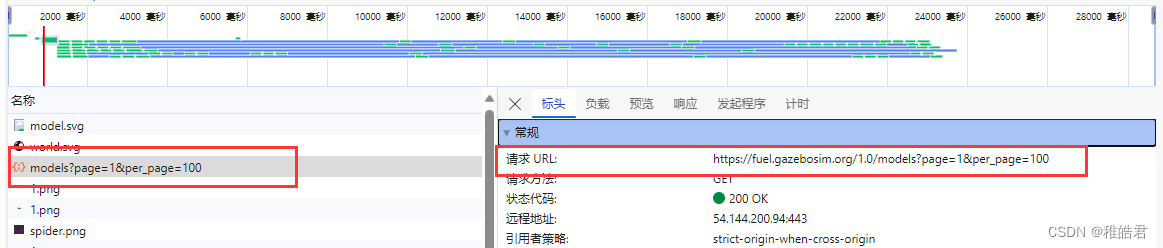
提取 name 和 owner,并格式化 URL
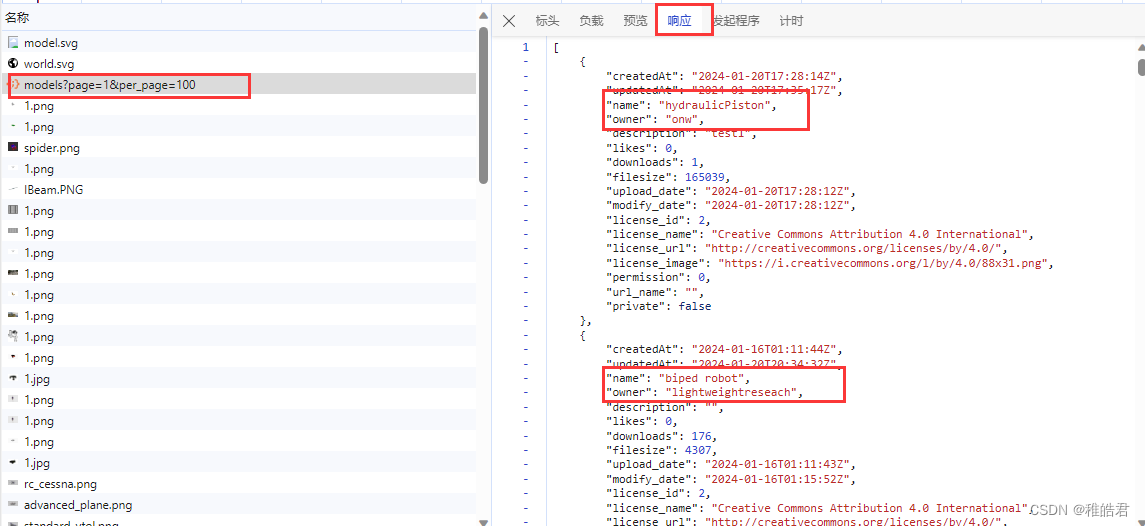
name+owner作为每个模块的唯一标识符
编写代码
import requests
from urllib.parse import quote
# 请求的 URL
# page可以自己更改,比如下载完1页后,改为2进行下载第2页,以此类推下载所有,per_page=100代表的是整个页面含有100个模块
url = "https://fuel.gazebosim.org/1.0/models?page=1&per_page=100"# 发送请求并获取响应
response = requests.get(url)# 解析 JSON 数据
data = response.json()# 创建一个空数组来存储格式化后的 URL
formatted_urls = []# 遍历每个元素,提取 name 和 owner,并格式化 URL
for item in data:name = item.get('name', '')name = quote(name)owner = item.get('owner', '')owner = quote(owner)formatted_url = f"https://app.gazebosim.org/{owner}/fuel/models/{name}"formatted_urls.append(formatted_url)# 打印结果
for url in formatted_urls:print(url)#模拟下载
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
import time
# 配置 Chrome 以自动处理下载
options = Options()
prefs = {"download.default_directory" : "D:\\Code\\models13","download.prompt_for_download": False,"download.directory_upgrade": True}
options.add_experimental_option("prefs", prefs)# 初始化 WebDriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
# 设置显式等待
wait = WebDriverWait(driver, 10) # 最多等待10秒# 遍历 URL 列表
#for url in formatted_urls:
# driver.get(url)
# 循环打开新标签页并加载URL
i = 0
for url in formatted_urls:# 执行JavaScript来在当前窗口中打开新标签页driver.execute_script('window.open()')# 切换到新打开的标签页driver.switch_to.window(driver.window_handles[-1])# 加载URL到新标签页driver.get(url)# time.sleep(5) # 例如等待 10 秒# 找到下载按钮并点击# 等待下载按钮出现并可点击download_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button[title='Download this model']")))# 点击下载按钮download_button.click()# 这里你可以添加适当的延时等待下载完成# 在控制台输出正在下载的文件信息print(f"正在下载:{url}")i+= 1print(i)# 等待下载完成或者加入适当的延时# time.sleep(10) # 例如等待 10 秒
# 关闭浏览器
#driver.quit()
inp=input("按回车键结束程序! ")
运行效果
脚本运行,数据集自行下载到指定文件夹
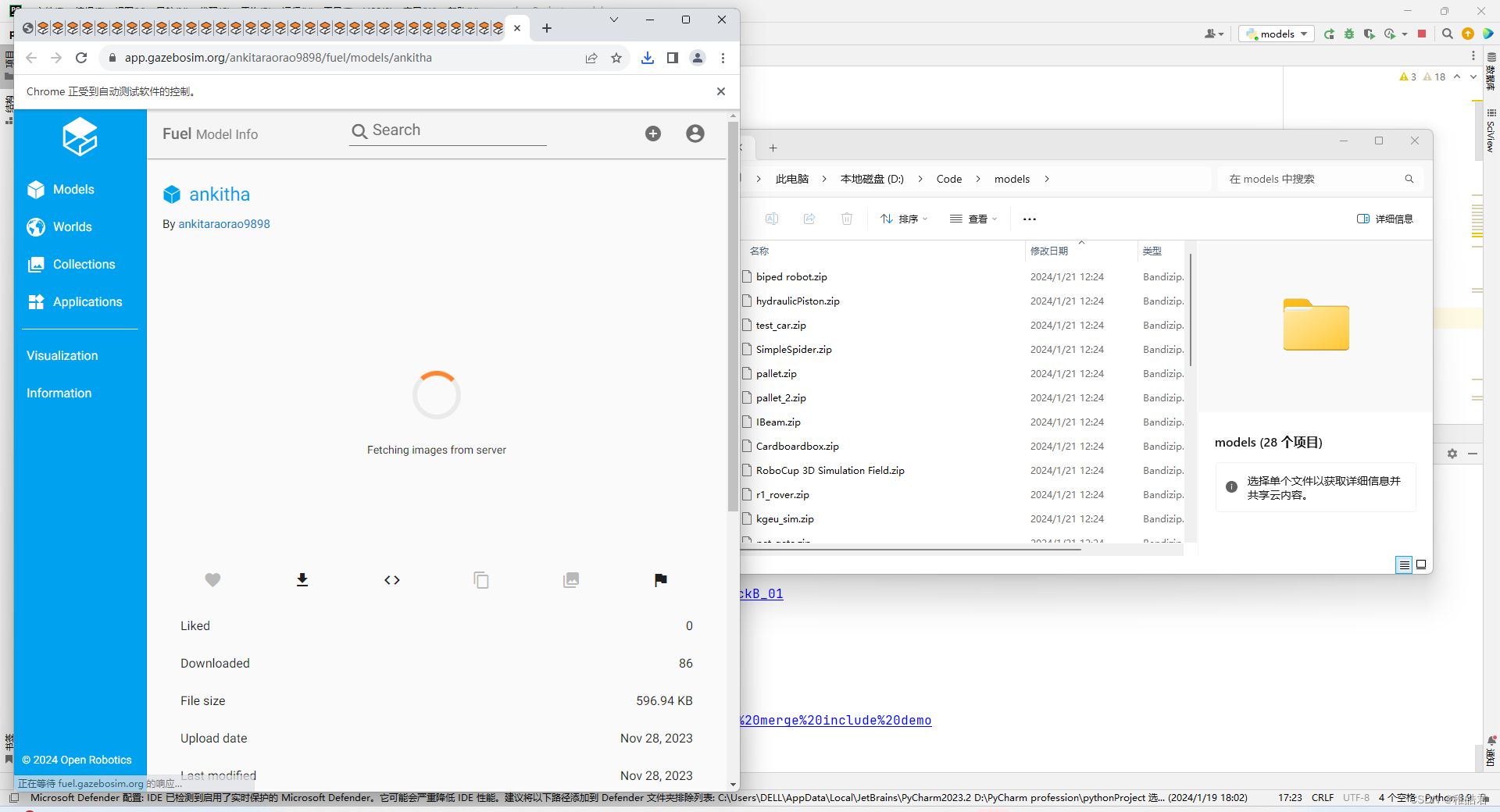
已经显示访问了100个模块的所有界面了
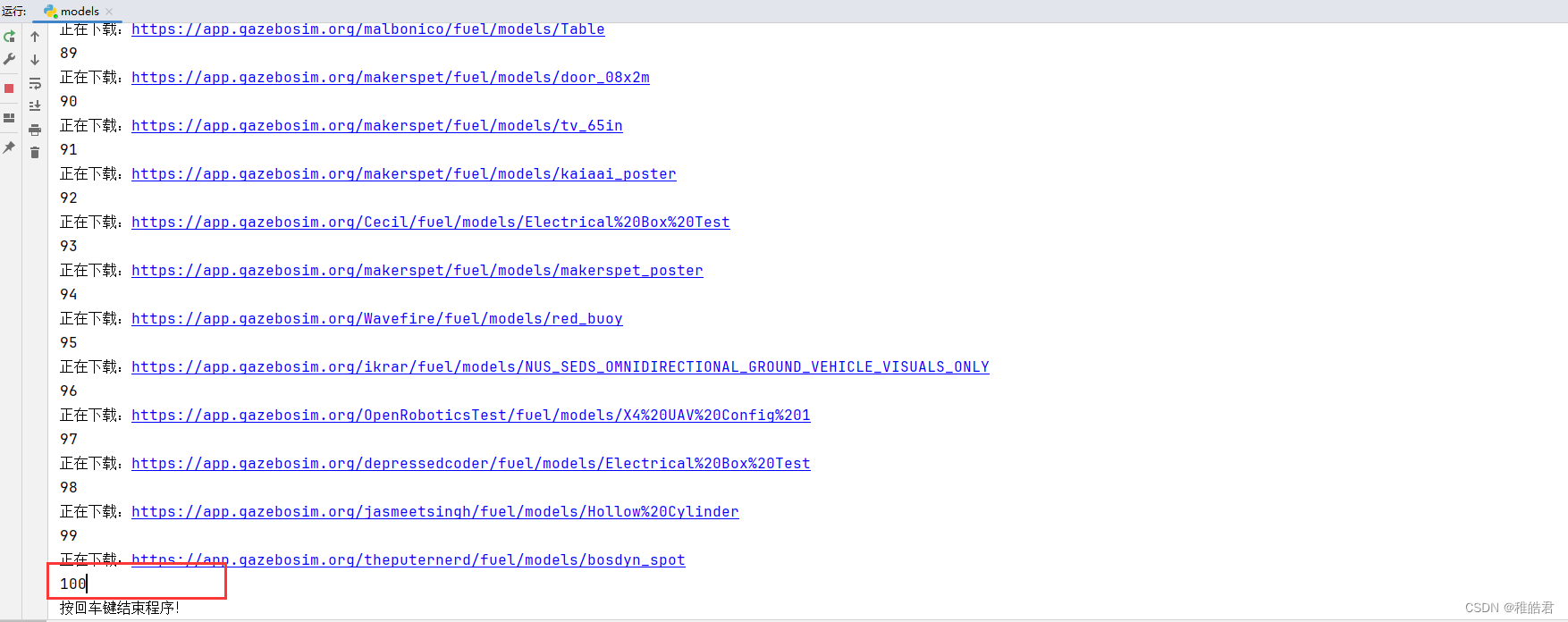
但需要等所有100个模块数据集下载完成才可结束程序,不然有的数据集还没下载完成。
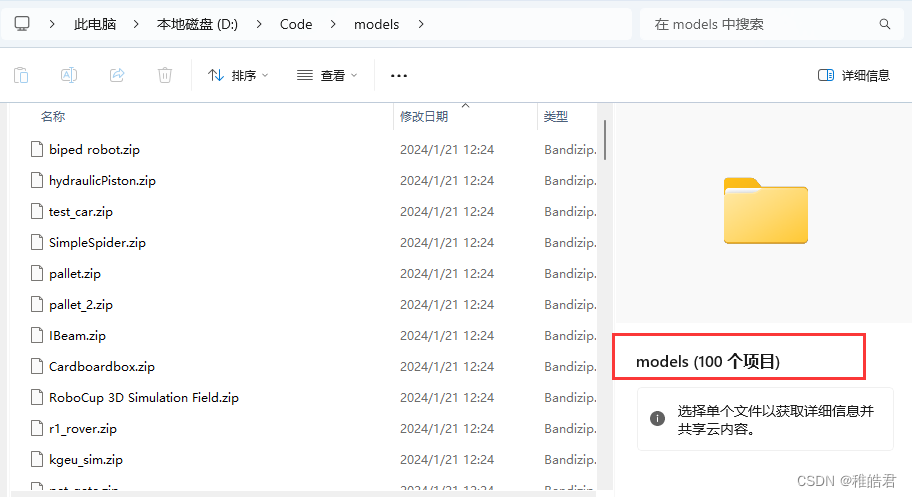
已经显示100个模块的数据集已经全部下载完成,这时可以进行结束程序。

接下来,可以进行下载第二页的100个模块的数据集,只需要修改代码中的page=2即可,随后几页的数据集以此类推即可完成全部的下载。

这篇关于编写脚本下载gazebo仿真器公开的模型数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





