本文主要是介绍【python爬虫】邮政包裹物流查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【python爬虫】邮政包裹物流查询
- 目标网站 ems 邮政快递包裹查询:
https://www.ems.com.cn/
- 截图
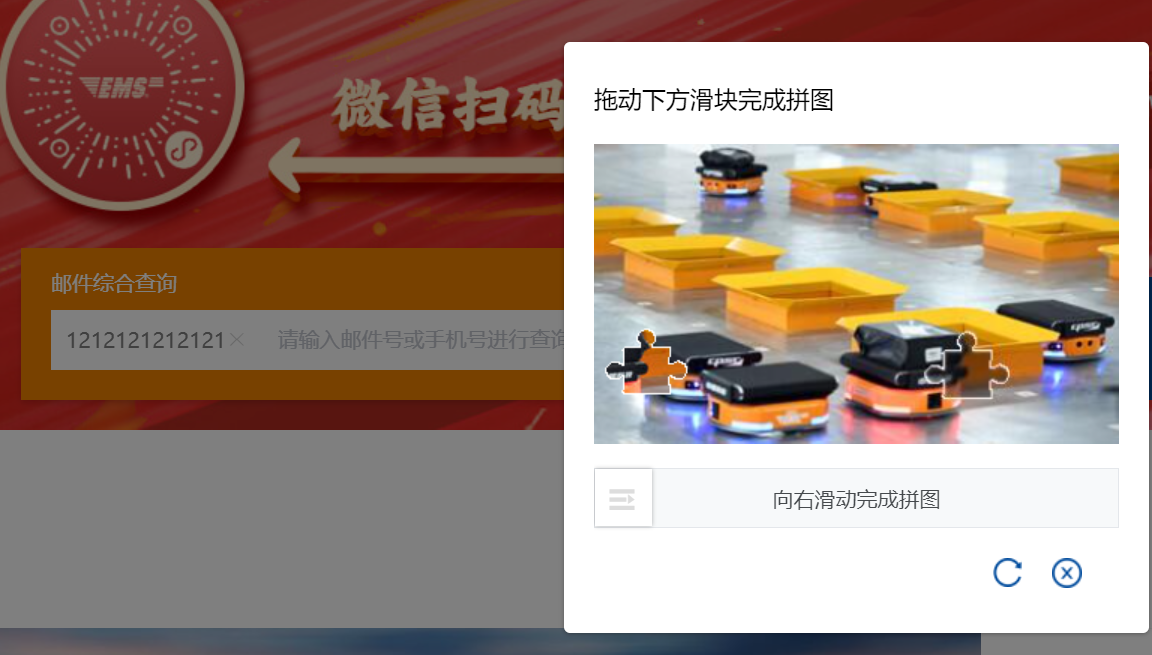
-
接口预览
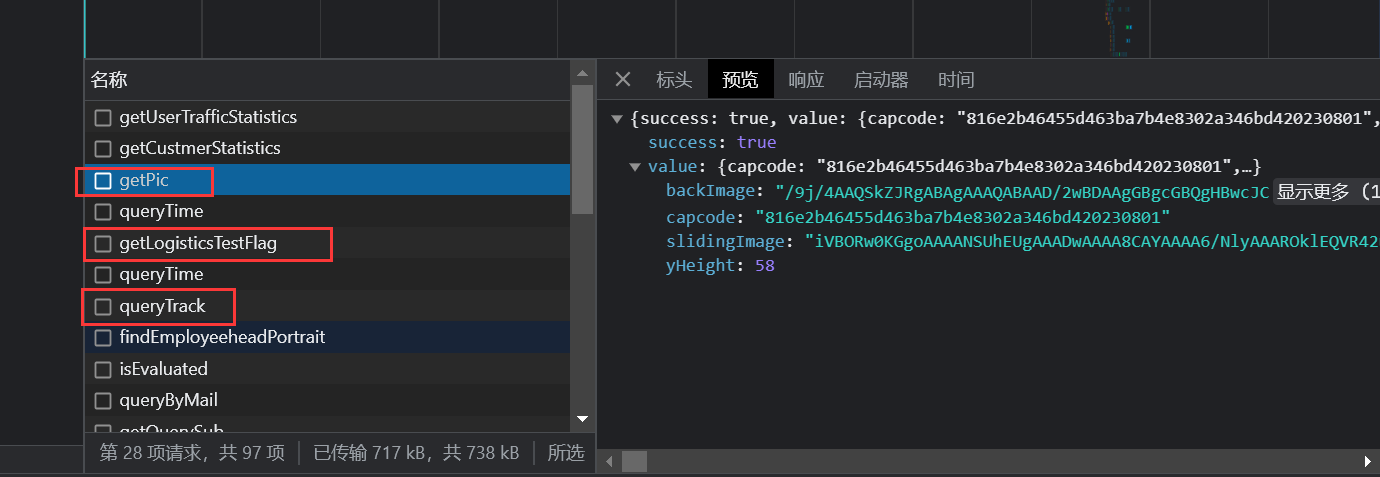
-
getPic请求滑动验证码的背景图片和滑块图片,返回的是base64编码的图片 -
getLogisticsTestFlag发送验证码的验证信息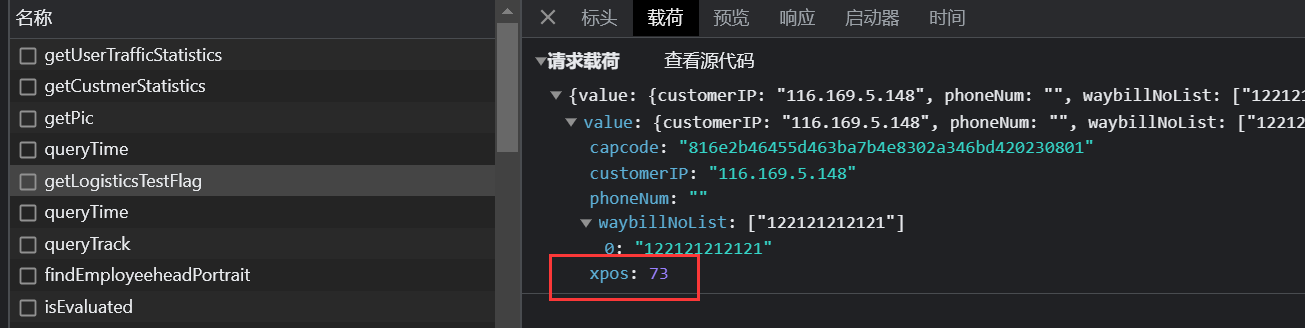
xpos为滑动的距离,本站没有验证轨迹一说,属于验证码简单的一类waybillNoList为需要查询的单号
-
queryTrack为查询物流的api
-
请求头的加密参数
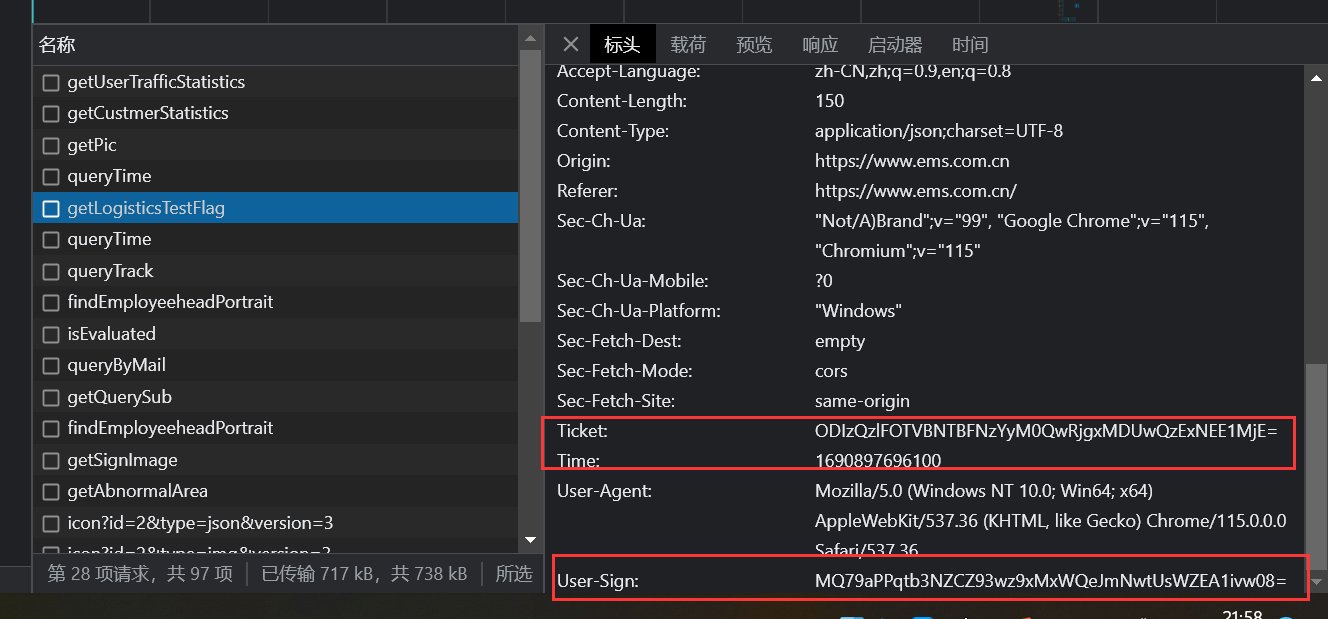
ticket、time必须校验user-sign没有校验
-
-
解决思路
- 滑动验证码采取
ddddocr识别 - 逆向
ticket、time请求头参数即可
- 滑动验证码采取
-
js调试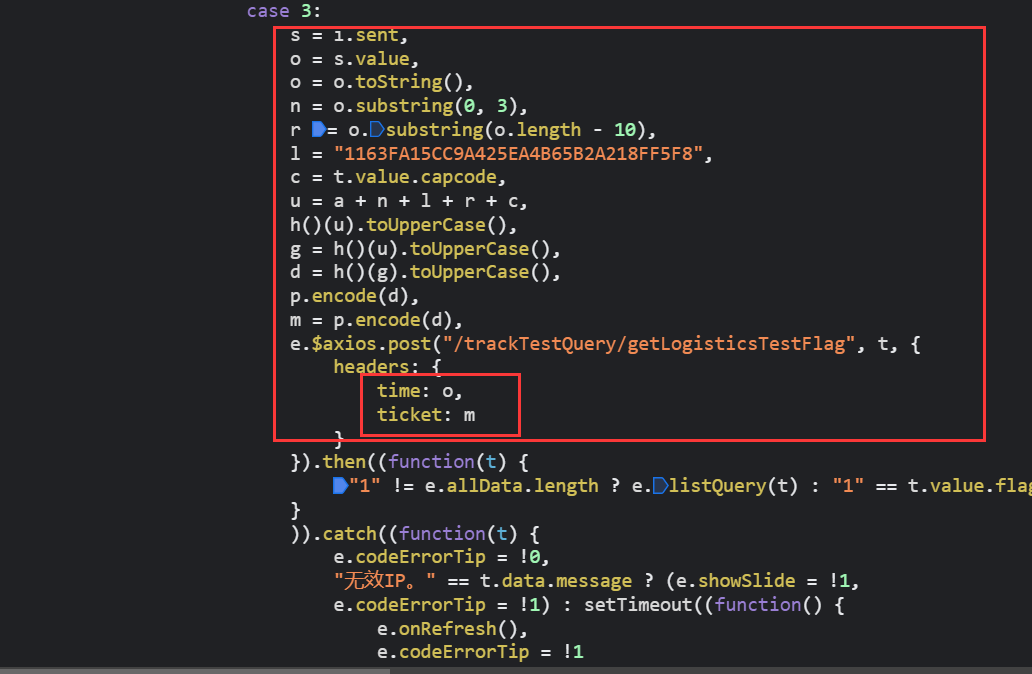
-
上图显示了这两个加密参数的加密逻辑
-
h()跟进去看是MD5 -
p.encode()是base64 -
需要注意的是
querytrack那个接口的l参数不一样,如下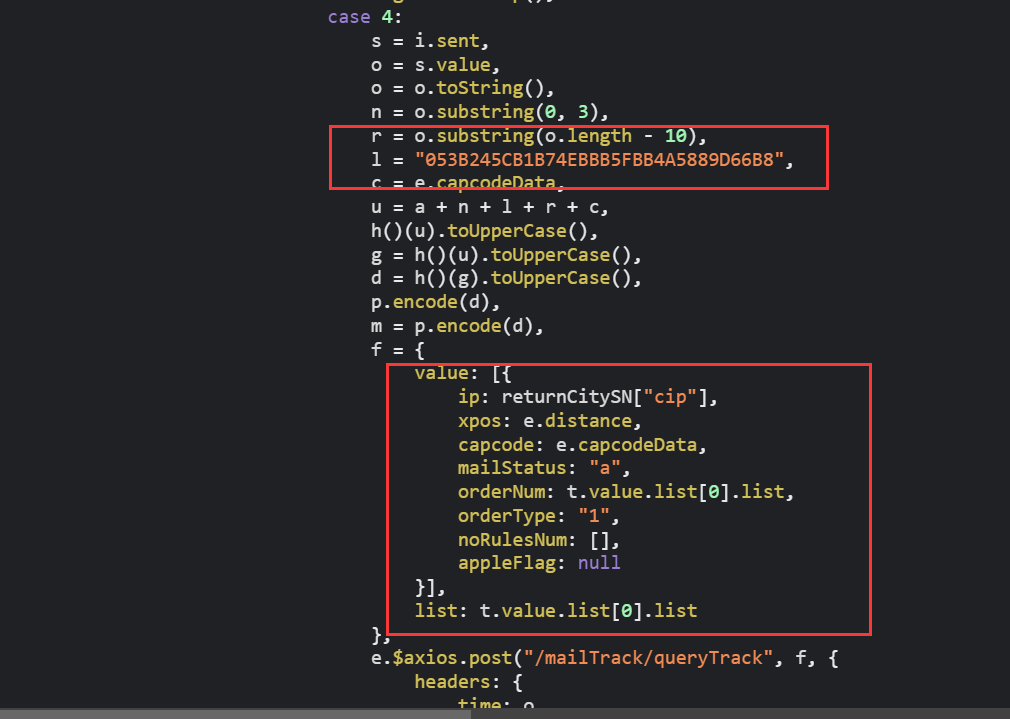
-
另外,请求前需要获取一个服务器时间,穿插在每次请求前,这个是为了让获取的信息更加实时
-
-
代码实现
import requests
import base64
import ddddocr
import hashlib
import json
from loguru import logger
logger.info("技术交流qq群:{}",529528142)
det = ddddocr.DdddOcr(det=False, ocr=False, show_ad=False)
headers = {'authority': 'www.ems.com.cn','accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',# 'content-length': '0','origin': 'https://www.ems.com.cn','referer': 'https://www.ems.com.cn/','sec-ch-ua': '"Not/A)Brand";v="99", "Google Chrome";v="115", "Chromium";v="115"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-origin','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',
}def query_time():response = requests.post('https://www.ems.com.cn/ems-web/currentTime/queryTime', headers=headers)return response.json()["value"]def getPic():response = requests.post('https://www.ems.com.cn/ems-web/cutPic/getPic', headers=headers).json()return response["value"]["capcode"], response["value"]["backImage"], response["value"]["slidingImage"], \response["value"]["yHeight"]def verify(_ticket, _time, _xpos, _capcode):__headers = {'authority': 'www.ems.com.cn','accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8','content-type': 'application/json;charset=UTF-8','origin': 'https://www.ems.com.cn','referer': 'https://www.ems.com.cn/','sec-ch-ua': '"Not/A)Brand";v="99", "Google Chrome";v="115", "Chromium";v="115"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-origin','ticket': _ticket,'time': _time,'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',}json_data = {'value': {'customerIP': '你的ip','phoneNum': '','waybillNoList': [consult_code,],'xpos': _xpos,'capcode': _capcode,},}response = requests.post('https://www.ems.com.cn/ems-web/trackTestQuery/getLogisticsTestFlag', headers=__headers,json=json_data)# print(response.json())if response.json()["success"]:logger.info("验证成功")else:logger.error("验证失败")def ddocr_get_pos(_slide, _bg):_slide_bytes = base64.b64decode(_slide)_bg_bytes = base64.b64decode(_bg)with open('./slide.png', 'wb') as f:f.write(_slide_bytes)with open('./bg.jpg', 'wb') as f:f.write(_bg_bytes)_res = det.slide_match(_slide_bytes, _bg_bytes)return _resdef get_ticket_(_time, _capcode, _type):o = _timen = o[0:3]r = o[3:]l = ""if _type == "verify":l = "1163FA15CC9A425EA4B65B2A218FF5F8"elif _type == "track":l = "053B245CB1B74EBBB5FBB4A5889D66B8"else:passc = _capcodeu = consult_code + n + l + r + cg = hashlib.md5(u.encode('utf-8')).hexdigest().upper()d = hashlib.md5(g.encode('utf-8')).hexdigest().upper()m = base64.b64encode(d.encode('utf-8')).decode('utf-8')return mdef query_track(_ticket, _time, _xpos, _capcode):headers_ = {'authority': 'www.ems.com.cn','accept': 'application/json, text/plain, */*','accept-language': 'zh-CN,zh;q=0.9,en;q=0.8','content-type': 'application/json;charset=UTF-8','origin': 'https://www.ems.com.cn','referer': 'https://www.ems.com.cn/','sec-ch-ua': '"Not/A)Brand";v="99", "Google Chrome";v="115", "Chromium";v="115"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-origin','ticket': _ticket,'time': _time,'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36',}json_data = {'value': [{'ip': '你的ip','xpos': _xpos,'capcode': _capcode,'mailStatus': 'a','orderNum': [consult_code,],'orderType': '1','noRulesNum': [],'appleFlag': None,},],'list': [consult_code,],}response = requests.post('https://www.ems.com.cn/ems-web/mailTrack/queryTrack', headers=headers_, json=json_data)return response.json()if __name__ == "__main__":consult_code = "12121212121"capCode, bg, slide, yheight = getPic()time_ = query_time()xpos_ = ddocr_get_pos(slide, bg)['target'][0] - 3logger.info("ddddocr->{}", xpos_)ticket_ = get_ticket_(_time=str(time_), _capcode=capCode, _type="verify")verify(_ticket=ticket_, _time=str(time_), _xpos=xpos_, _capcode=capCode)time_ = query_time()ticket_ = get_ticket_(_time=str(time_), _capcode=capCode, _type="track")info = query_track(_ticket=ticket_, _time=str(time_), _xpos=xpos_, _capcode=capCode)logger.info(info)- 运行截图
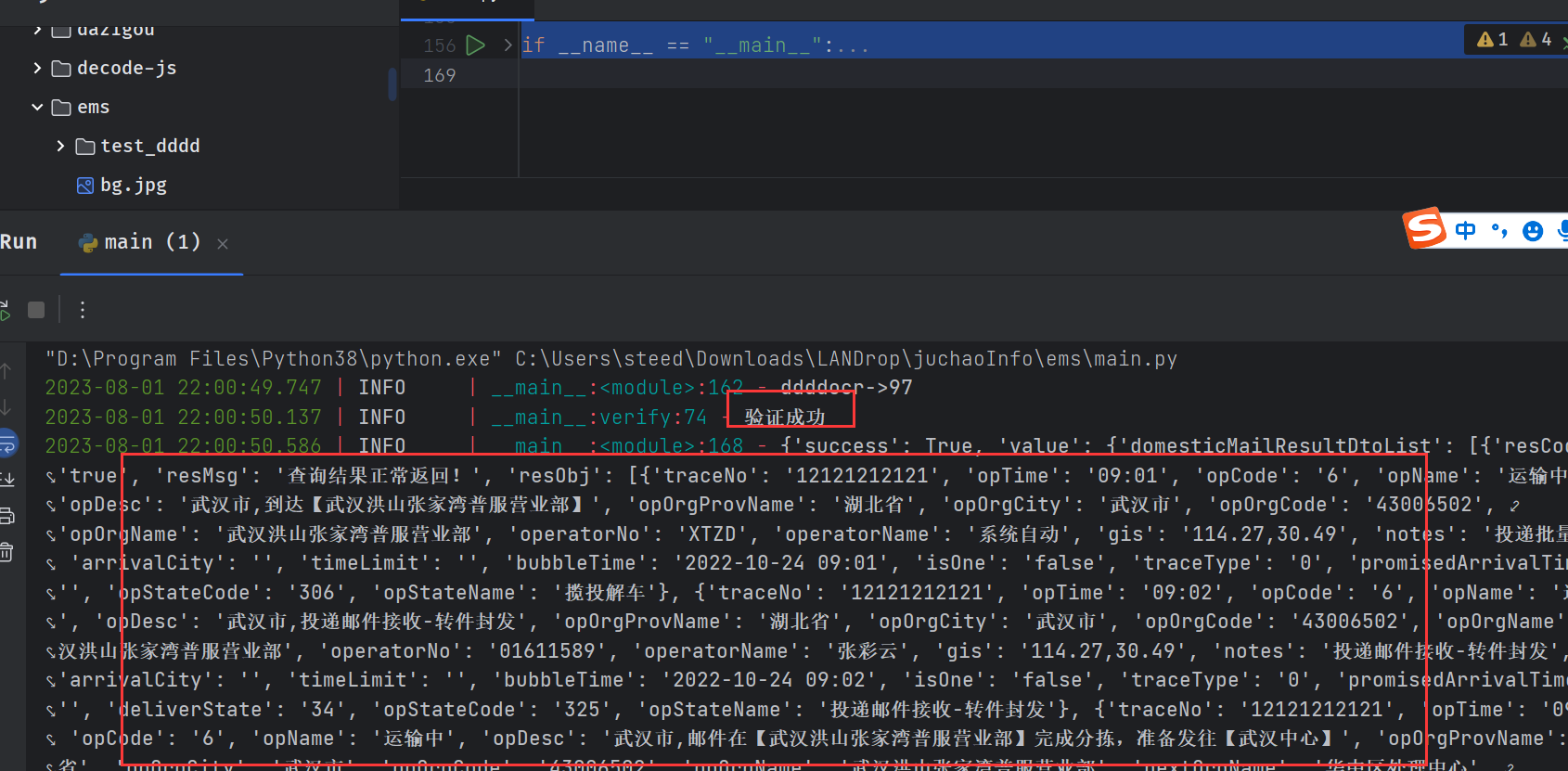
time=str(time), _capcode=capCode, _type=“track”)
info = query_track(ticket=ticket, time=str(time), xpos=xpos, _capcode=capCode)
logger.info(info)
- 运行截图[外链图片转存中...(img-ElMgBEOl-1690961672127)]技术交流群:`529528142`
这篇关于【python爬虫】邮政包裹物流查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





