本文主要是介绍MDD-UNet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这里提出了一种基于U-Net的无监督域自适应框架,该框架的理论保证基于Margin Disparity Discrepancy(MDD)的Margins。本工作通过证明在保留U-Net标准形式的同时,改进了其性能,从而为从方法论和实践角度研究具有非常大型假设空间的模型提供了新途径。
当前图像分割的最先进技术通常基于U-Net结构,这是一种U形编码器-解码器网络,具有跳接连接。尽管性能强大,但这种架构在用于具有与训练数据不同特性的数据时,通常表现不佳。
为了解决在存在域转移的情况下提高性能的问题,已经开发了许多技术,但通常与域自适应理论的联系并不紧密。在本文中,作者提出了一种基于U-Net的无监督域自适应框架,该框架的理论保证基于Margin Disparity Discrepancy(MDD)的Margins。作者在海马体分割任务上评估所提出的技术,结果发现Margins-UNet能够学习到具有域不变性的特征,而无需了解目标域中的标签。
在12个数据集组合中的11个上,Margins-UNet在标准U-Net上的性能得到提高。本工作通过证明在保留U-Net标准形式的同时,改进了其性能,从而为从方法论和实践角度研究具有非常大型假设空间的模型提供了新途径。
代码:https://github.com/asbjrmunk/mdd-unet
1 Introduction
在医学图像分析数据中,设备、患者组和扫描协议等因素导致了分布的巨大变化。由于标记医学图像通常需要专业行人的大量参与,因此可用的标记数据通常有限。这是医学图像分割中的一个关键挑战,因为模型通常无法泛化到与训练数据的具体设置不同的数据,而手动标记每个新测试域的数据是不切实际的。
解决这个问题的一个方法是自监督域自适应(UDA)。在UDA中,目标是将源域学习到的知识转移到一个类似但不同的目标域,只假设源域的标签。

实用的域自适应方法试图利用这种权衡,例如DANN[6]采用了一种受GAN[9]启发的对抗性架构,其中网络在寻求学习输入表示时,源域和目标域无法区分,同时在本领域表现良好。然而,DANN的理论基础仅限于二分类器,这意味着对于分割等问题,该方法缺乏理论保证,因为最大玩家和最小玩家的假设空间明显不同。
张等人[1]通过提出一个新的分布差异测量方法,称为Margin Disparity Discrepancy (MDD),使得可以基于评分函数和边际损失推导出与Ben David等人[8]相似的一般化界。值得注意的是,这种方法被无缝地转换为一种理论上的对抗性架构,分类器的假设空间没有限制,实现了相对于最先进域自适应方法显著的改进。
尽管MDD理论对于任意假设类模型是合理的,但在应用于具有非常大的假设空间的模型时,如用于图像分割的模型,其是否实用还不明确。
生物医学分割的域自适应目前从理论上尚不明确。由于在医学领域,理论理解尤为重要,因为它为理解所提出方法的潜力和限制提供了途径。本文旨在研究是否可以将MDD应用于分割问题,通过结合U-Net,即最先进的医学分割模型的架构基础,与MDD,并提出一种理论上证明的域自适应生物医学图像分割方法。
本文的贡献在于提出了新的方法,包括一种新的训练程序和一种创新的早期停止方案。该方法在脑部MRI的海马体分割任务上进行了评估。作者发现,所提出的这种方法在基础U-Net上取得了显著的改进。
本文被认为是一种概念验证,它为理解和分析域自适应在医学领域的应用提供了一种途径。所提出方法的理论证明,开辟了完全新的研究途径,可能为作者理解对抗域自适应的能力和限制提供基本贡献。
2 Method

Margin Disparity Discrepancy
所提出方法的理论基础是张等人提出的_Margin Disparity Discrepancy_(MDD)。
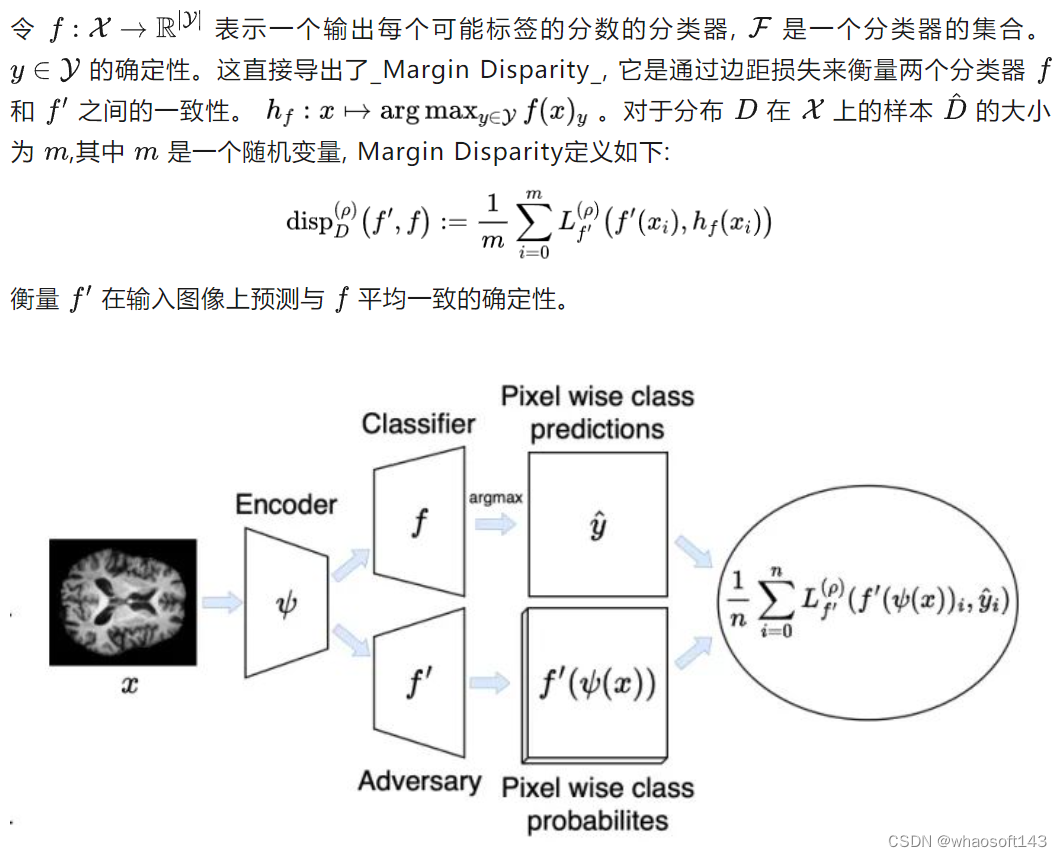

这自然是一个minimax游戏,其中目标是学习一个表示,使得最终的分类基于既具有区分性又对域的变化不变的特征。
Network Architecture
作者将MDD与U-Net相结合。U-Net自然地分为_block_,每个block由一个或多个卷积操作和ReLU激活函数组成,并使用收缩路径中的最大池化和扩展路径中的上卷积进行组合。作者只考虑应用于2D数据的模型,这些数据可以通过将每个切片独立考虑而获得3D体积。作者将MDD应用于U-Net,将其分为四个部分:
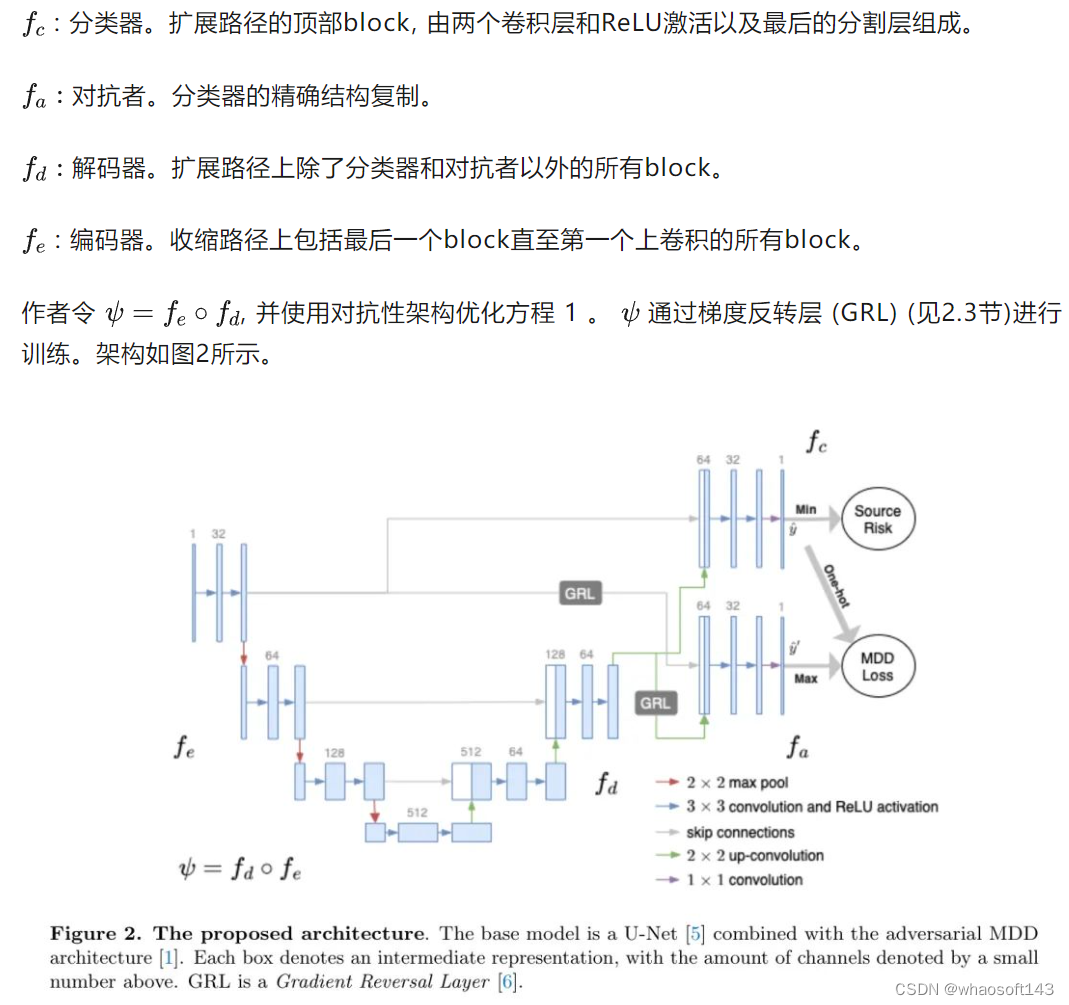
Gradient Reversal Layer

Loss
由于边距损失容易导致梯度消失,作者遵循[1]并使用交叉熵损失来优化方程1。

可以使用随机梯度下降直接优化。
Pre-training and early stopping

3 Experimental setup
作者在 hippocampus 分割任务上验证所提出方法的有效性。
Data
本研究中使用的核心数据是来自[10]的T1加权MRI卷。标签突出了海马体,分为三个类别标签:左侧海马体、右侧海马体和背景。数据包括四个数据集,分别用于表示分布转移,通过选择不同的数据集作为源域和目标域。这些数据集如下:
HarP:包括135个来自ADNI研究的正常、认知受损和痴呆症患者的T1加权MRI扫描(65名女性和70名男性,年龄在60到90岁之间)。数据使用GE、Philips和Siemens的扫描仪,强度为1.5T或3T。
Hammers:包括30个来自[12]的健康受试者(15名女性和15名男性)的T1加权MRI扫描(年龄在20到54岁之间)。数据使用1.5T的GE扫描仪获取。
Oasis:包括35个来自MICCAI 2012多原子标签挑战[13,14]的健康受试者(22名女性和13名男性)的T1加权MRI扫描(年龄在18到90岁之间)。数据使用1.5T的GE扫描仪获取。
LPBA40:包括40个来自[15]的健康受试者(22名女性和13名男性)的T1加权MRI扫描(年龄在19到40岁之间)。数据使用1.5T的GE扫描仪获取。
Preprocessing
所有体积都使用基于强学习的脑部提取系统ROBEX[16]进行去骨,偏移场校正和转换到RAS+方向。此外,每个体积的强度都限制在99百分位数,标准化以具有零均值和单位方差,然后缩放到范围在-1到1之间。由于网络只处理2D输入,因此将体积在冠状维度上切片,并填充到大小为256×256。
Model configurations
作者将MDD-UNet与U-Net进行比较。首先,作者对U-Net进行60次迭代训练。在应用MDD之前,先用MDD对U-Net进行训练。使用Adam[17]训练,学习率在不同部分的MDD-UNets中不同。

4 Results
作者的实验结果如表1所示。与基础U-Net相比,MDD-UNet的性能有显著提高,在12个组合中有11个取得了最佳性能。

5 Discussion & Limitations
冻结层。为了分析冻结层的影响,作者进行了一项实验,研究不同块的冻结对性能的影响。作者定义一个块为具有相同特征图大小的卷积层,由max池或上卷积分隔。作者从左到右计数块,即正向传播的顺序。
表2显示了在验证集上的epoch训练进度中,目标分布的 dice 得分。在添加MDD之前,U-Net在目标集上的性能为0.54 Dice。将编码器的前两个块冻结优于所有其他配置,特别是任何将解码器块冻结的配置。
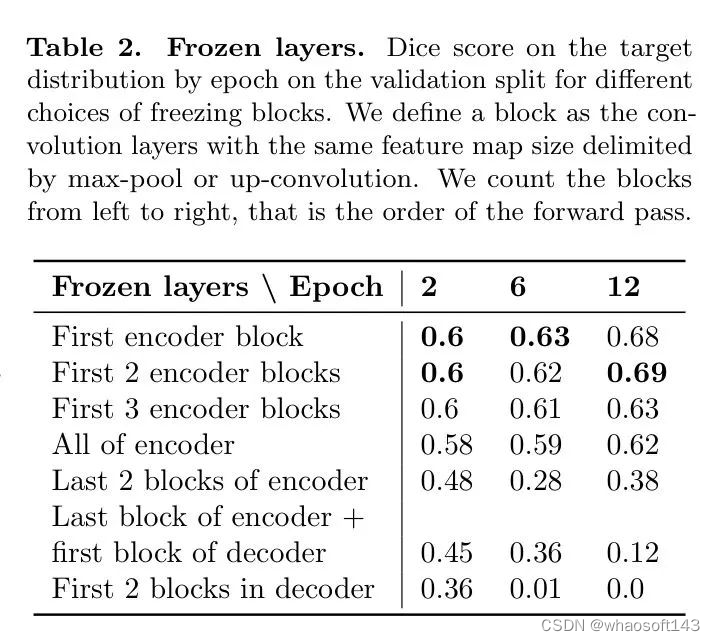
MDD-UNet的冻结层表明,模型在U-Net中的低级特征比高级特征更具域不变性。此外,由于最大玩家的假设空间非常大,找到对抗者之间的理想平衡很难。这些结果展示了,在的开始使用冻结层和预训练,可以实现稳定的训练,从而允许MDD应用并使用早期停止机制。
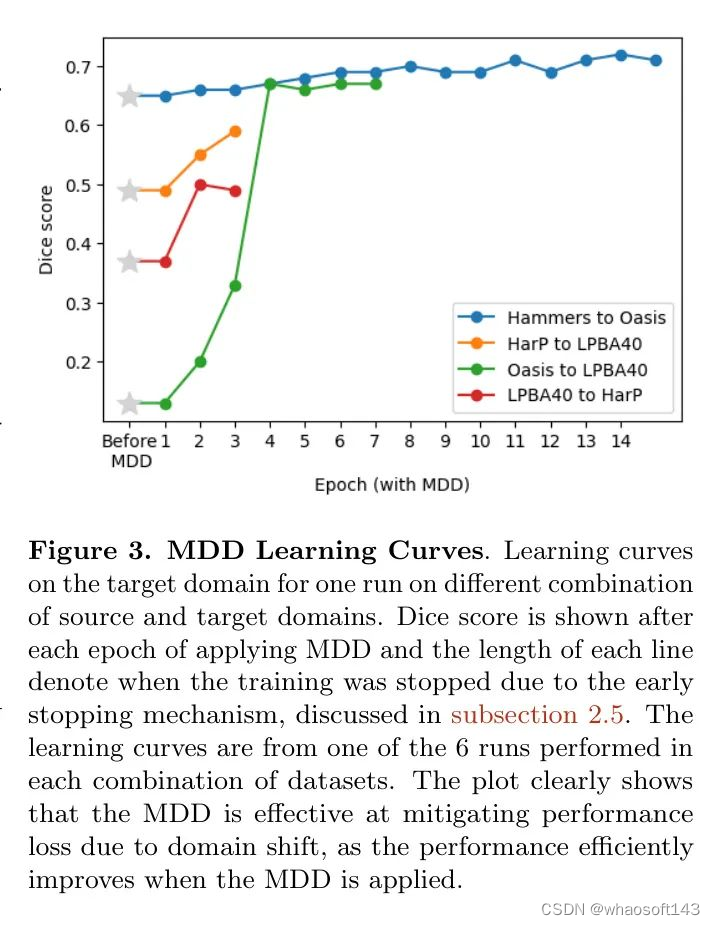
MDD的有效性。 当应用MDD时,网络在目标域上的性能可以有效提高。图3显示了应用MDD的迭代次数与目标域上Dice性能的关系。当应用MDD时,目标性能在几迭代后大幅提升。早期停止机制可靠地停止训练,当目标性能最好或接近最好时。 whaosoft aiot http://143ai.com
局限性。 本工作不声称将MDD-UNet确立为最先进的域自适应方法,并且未来的工作应该研究其与增强和其他已知可以提高域转移性能的方法论改进的交互作用。
此外,在本工作中,作者专注于证明MDD在2D数据上的模型上的有效性。将来的工作将研究该方法在3D数据上的行为,这在医学领域很常见,并且是U-Net的现代改编。
6 Conclusion
在本文中,作者提出了一种基于U-Net和MDD的域自适应方法,并给出了理论保证。作者证明,MDD-UNet在分割海马体数据方面优于常规U-Net。这项工作为更深入地研究所提出的方法的应用和重要的是MDD差异度量到生物医学领域开辟了道路。
此外,这项工作为理论分析生物医学域自适应开辟了完全新的研究途径,这是生物医学领域的一个全新的研究领域。
这篇关于MDD-UNet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








