本文主要是介绍半监督之伪标签法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
方法
(1) Positive & Negative Pseudo Label
(2)基于不确定性的伪标签选择法
实验结果
后续伪标签更新
总结
前言
半监督学习一般有两个方法一致性正则和打伪标签法即 consistency regularization 和 pseudo-label, 其中一致性正则主要是基于数据增强的一致性正则,目前比较成熟,关于数据增强笔者也总结过一篇博客即
《半监督之数据增强》: https://blog.csdn.net/weixin_42001089/article/details/113307918
今天来看看打伪标签法,这个其实原理很简单,就是先用少量的有标签数据训练一个基础模型,然后用其对大量无监督数据进行预测得到pseudo-label ,然后用其和少量的有标签数据一起训练模型,然后在对大量无监督数据进行预测得到pseudo-label ,然后再训练模型,不断循环最终达到收敛。
今天这篇论文呢,就是在打伪标签法继续改进,一起来看看吧
In Defense Of Pseudo-Labeling: An Uncertainty-Aware Pseudo-Label Selection Framework For Semi-Supervised Learning
论文:https://arxiv.org/pdf/2101.06329.pdf
这是一篇收录在ICLR 2021的论文,简称UPS
关于其解读的话可以看:
伪标签还能这样用?半监督力作UPS(ICLR 21)大揭秘! - 知乎
讲的很详细了,笔者这里简单总结一下核心idea和看法。部分话来源于上述知乎。
方法
(1) Positive & Negative Pseudo Label
伪标签有时候是不准的,基于带噪学习 Negative Learning的思想,其实我们一直是基于正样本的,反过来想想呢?我们有时候不确定其到底属于哪一类,但是我们比较确定其不属于哪一类
以前我们都是基于门限,来确定是否属于c类
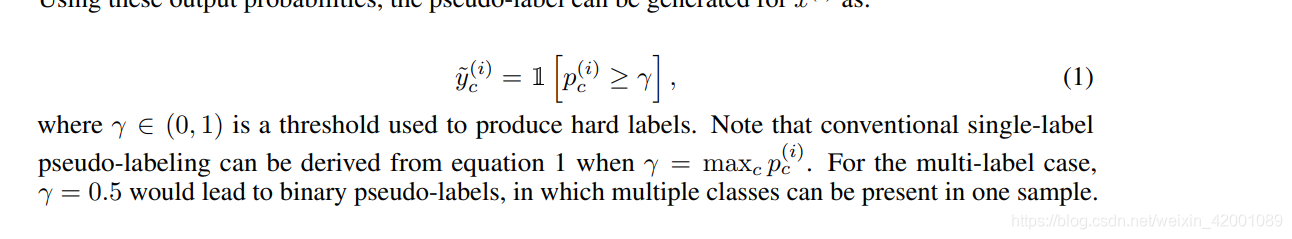
现在我们我们定义一个变量即gc

红色部分代表正样本,绿色部分代表负样本,仔细看,当预测是否属于c类的时候,如果概率高过Tp ,那么红色是1,绿色是0,gc结果是1,如果低于Tn,那么红色是0,绿色是1,gc结果还是1,基于情况即大于Tn小于Tp ,gc是0,逻辑含义就是:
gc代表的就是用不用其训练网络,当概率高过Tp即正样本置信度高,我们可以用,当低于Tn负样本置信度高,我们也可以拿来训练网络,但当处于中间时,就是不确定了,我们就不用其训练网络了,所以loss是

(2)基于不确定性的伪标签选择法
仅凭网络softmax层输出的概率值作为置信度唯一的依据显然不够——作者参考了深度网络不确定性估计的技术(MC-dropout, ICML 2016),计算输出值的不确定性作为另一种置信度(如图2所示),和softmax层输出的概率双管齐下,筛出可靠的贴伪标签的样本。
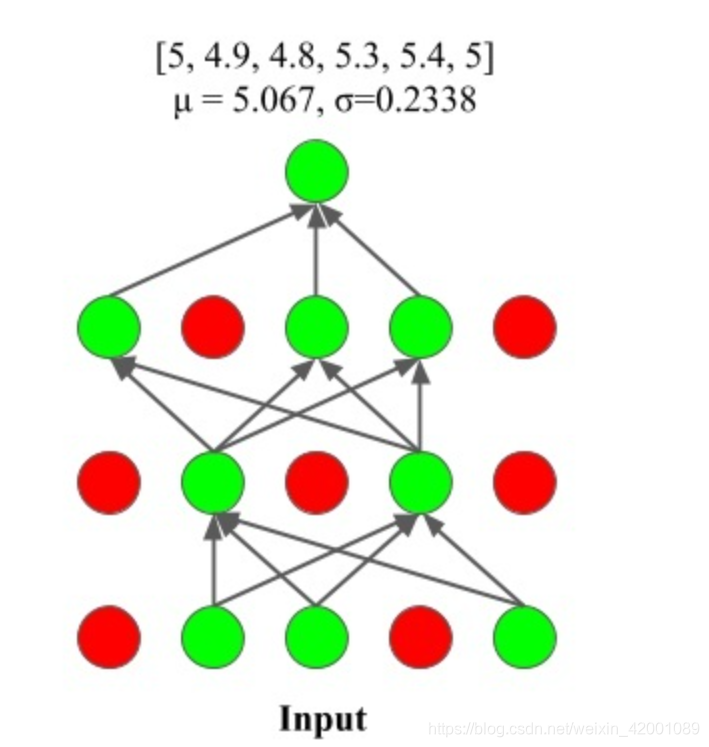
这里的逻辑是这样的:网络校正可以衡量伪标签是否可靠,而模型对单个样本的不确定性和网络校正有着一种映射关系,如下图
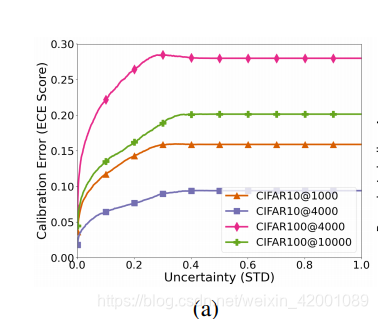
这里的纵坐标就是网络校正的量化指标即 the Expected Calibration Error (ECE) score, 看到模型对单个样本的不确定性(STD)越低,网络校正的误差就越小,所以不确定性也可以作为一种置信度,于是我们可以进一步改进loss

这里的u就是计算不确定性,kp和kn是正负样本不确定性的门限,直观理解就是当低于一定门限时(说明伪标签可靠),我们才用即红框和绿框才为1
说到这里可能有个疑问就是u函数是什么即不确定性怎么计算,可以看
https://arxiv.org/abs/1506.02142
大概思路就是对当前 batch 数据做 dropout,然后foward. 重复多次,计算均值和方差
作者还用SpatialDropout、DropBlock等方法替代Dropout计算模型输出的不确定性。
实验结果
(1)CIFAR-10和CIFAR-100上面,基于打伪标签的UPS算法可以取得和MixMatch的一样的性能。
(2)UCF-101视频分类数据集上,UPS也有好的结果
(3)多标签图片分类任务Pascal VOC2007数据集上也是SOTA,paper说这是第一篇在多标签上面做半监督的研究,注意因为我们是基于门限的,所以可以适配多标签的
(4)CIFAR-10上做了UPS各个模块的消融实验,其中UA(Uncertainty Aware)模块起着至关重要的作用,而NL(Negative Learning)模块也有辅助收益。
(5)在CIFAR-10上探究了kp参数的影响
(6)说明了不确性的通用性即用SpatialDropout、DropBlock等方法替代Dropout,结果是有普遍性
(7)打伪标签和数据增强具有正交性
(8)类别均衡对于打伪标签的重要性, 平衡很重要,作者在前几轮都是强制每类相同。
(9)就是一些可视化的展示,即选出置信度高的(置信度超过0.9,按照UPS方法的置信度超参,Tp=0.7, Tn=0.05) ,但是高不确定性的(高于0.1的,kp=0.05,kn=0.005)

可以看到这些大部分都是错的,也就是说所以基于NL(Negative Learning)策略选出了置信度比较高的,但是其有一部分还是错误的标签,即再加上不确定性可进一步筛选出更置信度高的伪标签。
后续伪标签更新
(1) 还有就是为了选出一些质量高的伪标签数据,可以进行一些简单的筛选策略比如:

(2) 使用了最近火的对比学习,具体可以看:
Self-Tuning for Data-Efficient Deep Learning
ICML2021 | Self-Tuning: 如何减少对标记数据的需求?
总结
(1)打伪标签法和一致性正则是正交的,即可叠加产生收益,比如Match系列方法就是两则结合的产物:MixMatch(NIPS 2019),ReMixMatch(ICLR 2020),FixMatch(NIPS 2020)和FeatMatch(ECCV 2020)
(2)再来看一下最终论文中的loss,和其中最重要的gc,这也是本篇paper的创新点。
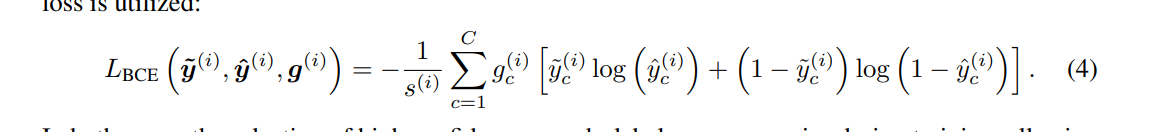
其中gc
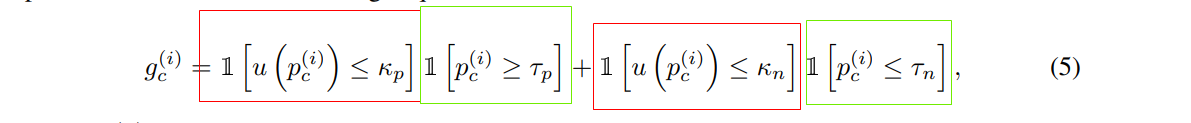
红框是应用了不确定性策略,绿色应用了Positive & Negative Pseudo Label策略,综合两个策略,只有同时满足两个策略即两个策略都有高的置信度,gc才为1(这个样本的伪标签可信),即才用这个样本去训练,否则不用。
(3)伪标签训练的时候,数据平衡很重要,我们可以前几轮强制用每类相同的数据量去训练
(4)给我们一个思路就是不要只盯着正样本,负样本同样具有参考和改进意义,以后要多关注和思考一下即Negative Learning
(5)其实paper本质上改进的出发点就是要筛选出高质量的样本训练,说到这里不得不想到,在数据增强领域同样可以从这个出发点进行改进,即数据增强产生的样本都不一定是高质量的,可以筛选出高质量的进行训练,关于这方面的想法,阿里已经发表论文
Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation
笔记也进行了解读,在开头提到的数据增强博客中
(6)不确定性这个挺有意思的,可以多多专研理解一下
看到很多小伙伴私信和关注,为了不迷路,欢迎大家关注笔者的微信公众号,会定期发一些关于NLP的干活总结和实践心得,当然别的方向也会发,一起学习:

这篇关于半监督之伪标签法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!