本文主要是介绍集算器 SPL 抓取网页数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【摘要】
集算器 SPL 支持抓取网页数据,根据抓取定义规则,可将网页数据下载到在本地进行统计分析。具体定义规则要求、使用详细情况,请前往乾学院:集算器 SPL 抓取网页数据!
网站上的数据源是我们进行统计分析的重要信息源。当我们浏览网页,看到自己感兴趣数据内容时,希望能够快速抓取网页上的数据,这对于数据分析相关工作来说极其重要,也是必备的技能之一。但是网络数据抓取大多需要复杂的编程知识,操作也比较繁琐。这里介绍如何用集算器 SPL 快速抓取网页数据。
1、基本流程图
2、抓取网页数据接口
3、定义规则
A、web_info
B、init_url
C、help_url
D、target_url
E、page_url
4、抓取股票历史数据
5、用户自定义程序
A、数据提取程序接口
B.数据保存程序接口
C、数据提取程序样例
D、数据保存程序样例
E、自定义程序的使用
1、基本流程图
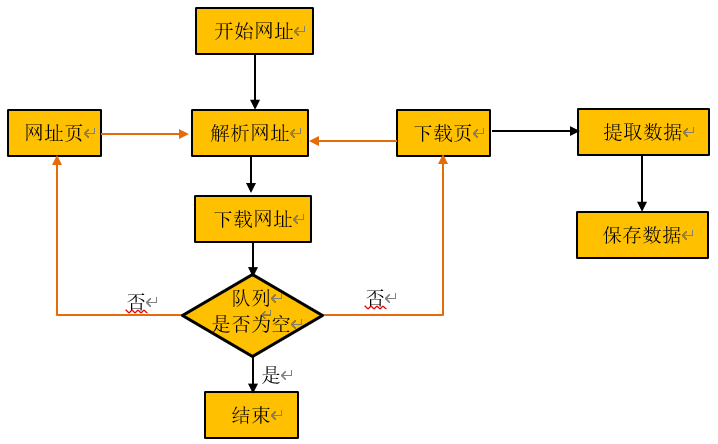
从给定的开始地址进行遍历,将解析过滤后的网址放入下载地址队列,分成网址页 help_url 与下载页 target_url, 网址页只收集网址,下载页即能收集网址,也能提取数据,把提取到的数据保存起来。抓取网页数据直到遍历地址为空,则抓取工作结束。
2、抓取网页数据接口
web_crawl(jsonstr) 是抓取网页数据接口,参数 jsonstr 是定义规则的字符串,抓取数据时,根据定义规则遍历 URL、下载、提取、保存相关内容数据。
本接口依赖集算器外部库 webcrawlCli。它缺省安装在集算器软件的 esProc\extlib\webcrawlCli 路径下,在集算器的外部库设置中勾选 webcrawlCli 项, 重启集算器后,就可以使用 web_crawl 接口。

web_crawl 简单用法,如抓取指定股票数据,SPL 脚本 demo.dfx:
| A | |
| 1 | [{web_info:{save_path:'d:/tmp/data', save_post:'false'}},{init_url:['http://www.aigaogao.com/tools/history.html?s=600000']},{page_url:{extractby: "//div[@id='ctl16_contentdiv']/",class:'default'}}] |
| 2 | =web_crawl(A1) |
| 3 | =file("D:/tmp/data/raqsoft.com/600000.txt").import@cqt() |
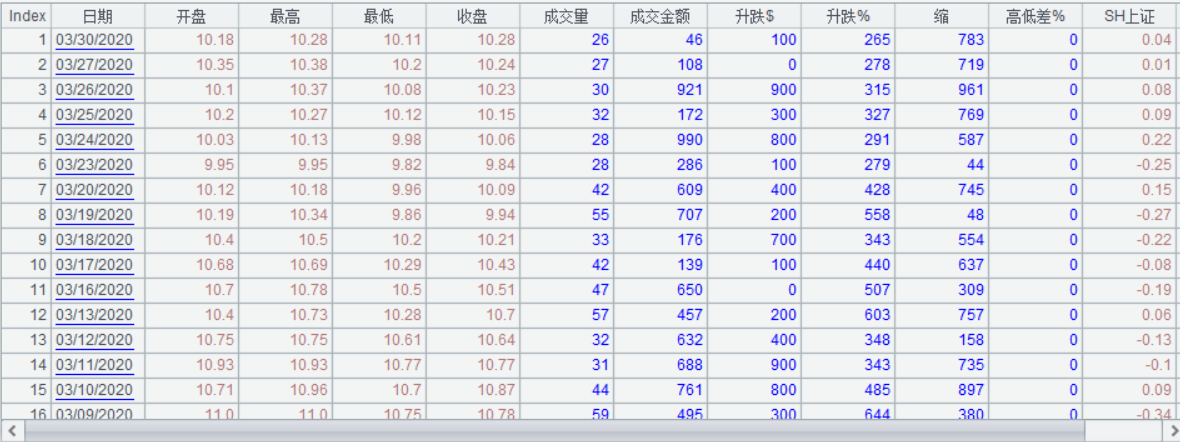
获取股票代码 600000 的数据文件:

文件内容:
3、定义规则
根据基本流程图,将定义规则分成网站信息、初始网址、网址页、下载页、提取数据五部分。具体内容如下:
[
{ web_info:{domain:'www.banban.cn', save_path:'d:/tmp/data/webmagic', thread_size:2, cookie:{name:"jacker", laster:"2011"},
user_agent:'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:39.0) Gecko/20100101 Firefox/39.0'}},
{ init_url:['https://www.banban.cn/gupiao/list_cybs.html', 'https://www.banban.cn/gupiao/list_sh.html']},
{ help_url:['gupiao/list_(sh|sz|cyb)\.html', '/shujv/zhangting/', '/agu/$']},
{ target_url:{reg_url:'/agu/365\d'}},
{ target_url:{filter:'gupiao/list_(sh|sz|cyb)\.html', reg_url:'gupiao/[sz|sh]?(60000\d)/',new_url:'http://www.aigaogao.com/tools/history.html?s=%s'}},
{ page_url:{filter:'history.html\?s=\d{6}', extractby: "//div[@id='ctl16_contentdiv']/"}},
{ page_url:{extractby: "//div[@id='content_all']/"}},
{ page_url:{filter:'/agu/365\d', extractby: "//div[@id='content']/"}}
]
规则简要说明:
web_info:网站信息,根据要下载的网站,设置域名、本地存储位置、用户代理信息、用户自定义程序等相关的信息。
init_url:初始网址,URL 遍历的入口网址。
help_url:网址页,定义网址页规则,收集网页内容中的 URL,但不提取此页面数据内容。
target_url:下载页,定义下载页规则,收集网页内容中的 URL,同时也提取此页面的内容。
page_url:提取数据,定义页面内容提取规则,在下载页 target_url 中根据此规则提取内容。
注意:json 书写结构细节,节点 {} 中的 [] 表示 list 列表,节点 {} 中的 {} 表示 map 键值结构,书定时要注意,否则书写不对易引起解析错误。
定义规则说明
A、web_info
设置要下载的信息,内容包括:
domain:设置域名。
save_path:文件存储路径。
user_agent:指用户代理信息。 作用: 使服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
sleep_time:抓取间隔。
cycle_retry_times:重试次数。
charset:设置编码。
use_gzip:是否为 gzip 压缩。
time_out:抓取超时设置。
cookie_name:cookie 信息,键值结构。
thread_size:抓取时线程数。
save_post:是否要为存储的文件名称追加编码串,以防网名文件被覆盖,缺省值为 true。如 books/a.html, music/a.html, 都是要下载的页面,保存时若此参数为 true, 则存储文件名分别为 a_xxxcgk.txt,a_xabcdw.txt,文件不会被覆盖;若为 false, 保存文件名为 a.txt, 后存储的就会将已存在的同名文件覆盖。
class_name:用户自定义的存储类。
class_argv:传递给 class_name 类的字符串参数。
B、init_url
初始的 URL。
为 List 列表结构,可设置多个 URL.
C、help_url
网址页主要是定义要收集的 URL 过滤规则, 符合规则的 URL 会被加入下载网址队列,但是不会提取其具体内容。过滤规则支持正则表达式,如:
gupiao/list_(sh|sz|cyb)\.html 表示 URL 中只有包括字符串 gupiao/list_sh.html、gupiao/list_sz.html、gupiao/list_cyb.html 链接才能通过。
为 List 列表结构,可定义多个规则。
D、target_url
下载页是要抓取内容数据的 URL,需要从这个页面里提取内容。若此 URL 符合 help_url 过滤规则,那么也会在本页面中收集 URL。
约定定义规则格式:
{target_url:{filter: pageUrl, reg_url:urlRegex, new_url:newUrl}},
表示在符合 pageUrl 条件的页面中,找出符合 urlRegex 条件的 href 链接,若 newUrl 定义了,则可与 urlRegex 过滤结果组合成新的 URL。
例如在页面中找到链接 a_100.html 符合过滤条件 reg_url=a_(\d+)\.html, 则有 newUrl=b_%s.php, 那么 urlRegex 过滤 a_100.html 的结果为 100, 将与 newUrl 合并,新的下载页为 b_100.php。
其中 filter 表示定义过滤的 URL 规则;若无此定义,表示所有的 target_url 都要用此规则。
reg_url 表示要收集的 URL 规则,必写;无 reg_url 的 target_url 规则则无意义。
new_url 表示定义新的页面,需要与 reg_url 过滤结果结合成新的 URL。
举例说明:
3.1 定义规则:{target_url:{filter:'gupiao/list_(sh|sz|cyb)\.html', reg_url:'gupiao/([sz|sh]?6000\d{2})/',new_url:'http://www.raqsft.com/history.html?s=%s'}}
在下载页gupiao/list_sh.html中包含如下内容:
<li><a href="/gupiao/600010/">包钢股份(600010)</a></li>
<li><a href="/gupiao/600039/">四川路桥(600039)</a></li>
<li><a href="/gupiao/600048/">保利地产(600048)</a></li>
A、gupiao/list_sh.html符合filter条件
B、href串符合reg_url条件,将产生[600010, 600039, 600048]
C、过滤结果与newUrl生成新的URL:
http://www.raqsft.com/history.html?s=600010
http://www.raqsft.com/history.html?s=600039
http://www.raqsft.com/history.html?s=600048
new_url中的%s为合并字符串的占位符。
3.2 定义规则:{target_url:{reg_url:'/ gupiao/60001\d'}},
在下载页gupiao/list.html中包含如下内容:
<li><a href="/gupiao/600010/">包钢股份(600010)</a></li>
<li><a href="/gupiao/600039/">四川路桥(600039)</a></li>
<li><a href="/gupiao/600048/">保利地产(600048)</a></li>
href中符合reg_url条件的,则收集到的URL为:
http://www.xxx.com/gupiao/600010/
其它两个href不符合过滤条件。
设置filter是为了在过滤后的页面中去收集URL,当help_url多时,过滤后缩小了范围,提高了效率。
target_url规则可定义多条,以适应不同的条件。
E、page_url
提取数据,主要作用于下载页面内容提取,它表示使用这个抽取规则,将提取到的结果保存。定义此规则参考 xpath 使用说明。它只提取主要内容,但对内容细节还需要 className 类来抽取。
约定定义规则格式:
{page_url:{filter: pageUrl, extractby: contentReg, class: className }},
其中filter表示符合过滤条件的url规则,若无此定义,表示所有的target_url都要用此规则。
extractby表示页面内容提取规则。若定义class,表示由className类执行内容提取;若className=
”default”, 表示用当前缺省方式提取,也就是针对table表中的内容提取数据。若缺省提取不满足需求,用户可自定义类来实现,具体实现参考后面用户自定义程序。
例如:extractby :"//div[@class=news-content]/text()",从网页中提取此节点下的数据。
page_url可针对不同的页面制定不同的规则。通过filter过滤后的页面中去提取数据,减少要处理的URL数量,当target_url多时,能提高效率。
若无 extractby 规则,则表示提取 target_url 页面中所有的内容。
若定义了多条 page_url 规则 ,则首个符合规则的内容将被提取。
假如 A 页面内容的符合规则 R1,R2,R3, 提取内容时首先是 R2,则不再根据 R1、R3 规则提取数据。
说明:若没有定义 target_url 规则,但当前页面有适合的 page_url 规则,则此页面的内容也会被提取。
4、抓取股票历史数据
下面用抓取股票历史数据来说明,web_crawl() 接口是如何应用的。基本操作:先获取股票代码,然后通过股票代码查询历史数据,从下载页面中提取数据后保存。
A、在https://www.banban.cn/gupiao/list_xxx.html 页面help_url 提取上证、深证、创业板的股票代码。
B 、将股票代码与http://www.aigaogao.com/tools/history.html?s=%s 结合,生成需要下载网址target_url.
C 、针对下载页target_url 中的内容提取。
D、显示提取后的内容。
SPL实现代码 Stock.dfx:
| A | B | |
| 1 | [{web_info:{domain:"www.banban.cn", save_path:"d:/tmp/data/webcrawl", save_post: "false",thread_size:2}},{init_url:["https://www.banban.cn/gupiao/list_cybs.html", "https://www.banban.cn/gupiao/list_sh.html"]},{help_url:["gupiao/list_(sh|sz|cyb)\.html"]},{target_url:{filter:"gupiao/list_(sh|sz|cyb)\.html", reg_url:'gupiao/[sz|sh]?(\d{6})/',new_url:"http://www.aigaogao.com/tools/history.html?s=%s"}},{page_url:{filter:"history.html\?s=\d{6}", extractby:"//div[@id='ctl16_contentdiv']/"}},{page_url:{extractby:"//div[@id='content_all']/"}}] | |
| 2 | =web_crawl(A1) | |
| 3 | =file("D:/tmp/data/ webcrawl/www.banban.cn/600010.txt").import@cqt() |
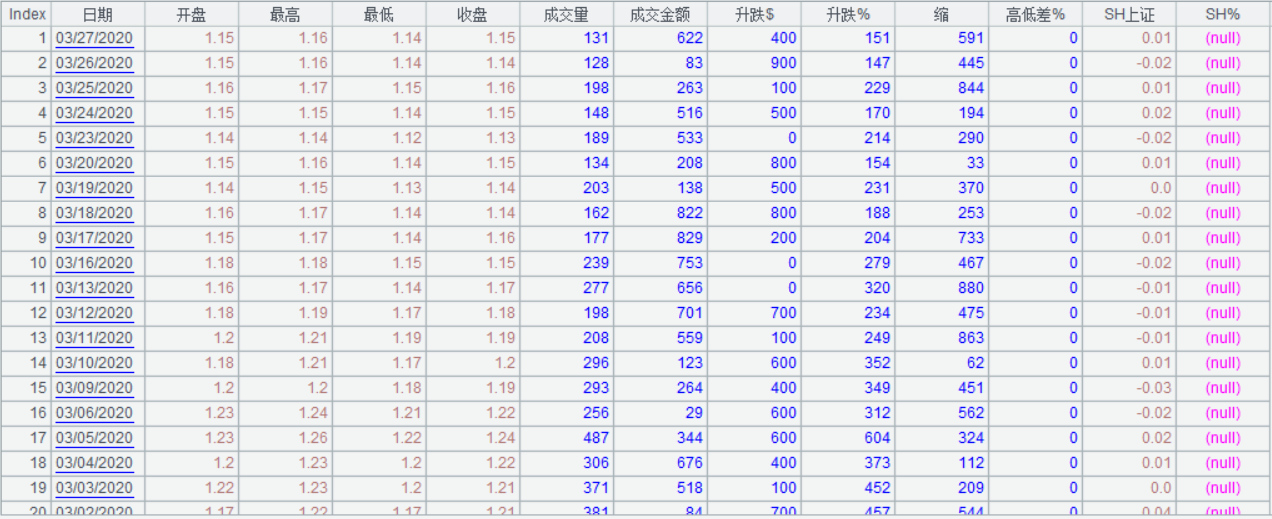
加载其中的股票 600010 数据为:
5、用户自定义程序
对于内容提取,缺省提供了对html中的table内容进行抽取。 但是世界上没有千篇一律的网页一样,也没有一劳永逸的提取算法。在使用网页数据抓取过程中,你会碰到各种类型的网页,这个时候,你就要针对这些网页,来实现对应抽取方法。存储方式类似,缺省提供的是文件保存,若想其它方式如数据库存储,还需要用户自己开发程序。参考下面接口,可将自定义程序融入网页数据抓取流程中。
A、数据提取程序接口
下载页的内容组织形式多样,各具不同,为了适应更多的内容提取需求,用户可自定义提取数据程序。
接口程序:
package com.web;
import us.codecraft.webmagic.Page;
public interface StandPageItem {
//数据提取处理。
void parse(Page p);
}
需要实现com.web.StandPageItem接口parse(Page p),数据提取在此实现。
B、数据保存程序接口
提取数据存储方式种类繁多,各具不同,为了适应更多的数据存储需求,用户可自定义数据存储程序。
接口程序:
package com.web;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
public interface StandPipeline extends Pipeline {
public void setArgv(String argv);
public void process(ResultItems paramResultItems, Task paramTask);
}
同样需要实现 com.web.StandPipeline 类中的 setArgv(), process()。
setArgv()输入参数接口,process() 处理存储数据接口。
C、数据提取程序样例
实现 com.web.StandPage 接口 parse(Page p),
参考代码:
package com.web;
import java.util.List;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.selector.Selectable;
public class StockHistoryData implements StandPageItem{
@Override
public void parse(Page page) {
StringBuilder buf = new StringBuilder();
List<Selectable> nodes = page.getHtml().xpath("table/tbody/").nodes();
for(Selectable node:nodes){
String day = node.xpath("//a/text()").get();
List<String> title = node.xpath("//a/text() | tr/td/text()").all();
if (title.size()<5) continue;
String line = title.toString().replaceFirst(", ,", ",");
buf.append(line+"\n");
}
page.putField("content", buf.toString());
}
}
将要保存的数据存放到 page 的字段"content"中,在保存处理时,将从字段"content" 中获取。
D、数据保存程序样例
实现com.web.StandPageline类中的setArgv(),process()
参考代码:
package com.web;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.PrintWriter;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import org.apache.commons.codec.digest.DigestUtils;
import us.codecraft.webmagic.utils.FilePersistentBase;
public class StockPipeline extends FilePersistentBase implements StandPipeline {
private Logger logger = LoggerFactory.getLogger(getClass());
private String m_argv;
private String m_path;
public static String PATH_SEPERATOR = "/";
static {
String property = System.getProperties().getProperty("file.separator");
if (property != null) {
PATH_SEPERATOR = property;
}
}
public StockPipeline() {
m_path = "/data/webcrawl";
}
// 获取存储路径与存储文件名前缀
public void setArgv(String argv) {
m_argv = argv;
if (m_argv.indexOf("save_path=")>=0){
String[] ss = m_argv.split(",");
m_path = ss[0].replace("save_path=", "");
m_argv = ss[1];
}
}
public void process(ResultItems resultItems, Task task) {
String saveFile = null;
Object o = null;
String path = this.m_path + PATH_SEPERATOR + task.getUUID() + PATH_SEPERATOR;
try {
do{
String url = resultItems.getRequest().getUrl();
o = resultItems.get("content");
if (o == null){
break;
}
int start = url.lastIndexOf("/");
int end = url.lastIndexOf("?");
if (end<0){
end=url.length();
}
String link = url.substring(start+1, end);
if (m_argv!=null && !m_argv.isEmpty()){
link = m_argv+"_"+link;
}
if (link.indexOf(".")>=0){
link = link.replace(".", "_");
}
// 加 md5Hex 为防止重名
String hex = DigestUtils.md5Hex(resultItems.getRequest().getUrl());
saveFile = path + link+"_"+ hex +".json";
}while(false);
if (saveFile!=null){
PrintWriter printWriter = new PrintWriter(new FileWriter(getFile(saveFile)));
printWriter.write(o.toString());
printWriter.close();
}
} catch (IOException e) {
logger.warn("write file error", e);
}
}
}
E、自定义程序的使用
将上述接口文件及 java 文件编译后打包成 webStock.jar 文件,放在esProc\extlib\webcrawlCli路径下重启集算器。数据存储程序,在 web_info 中配置;数据提取程序,在 page_url 中配置。下面是加载两个自定义类程序的 dfx 脚本。
SPL 代码脚本 mytest.dfx:
| A | B | |
| 1 | [{web_info:{domain:"www.banban.cn", save_path:"d:/tmp/data/webmagic", thread_size:2,user_agent:"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:39.0) Gecko/20100101 Firefox/39.0",class_name:'com.web.StockPipeline',class_argv:'stock'}},{init_url:["https://www.banban.cn/gupiao/list_cybs.html", "https://www.banban.cn/gupiao/list_sh.html"]},{help_url:["gupiao/list_(sh|sz|cyb)\.html", "/shujv/zhangting/"]},{target_url:{filter:"gupiao/list_(sh|sz|cyb)\.html", reg_url:'gupiao/[sz|sh]?( \d{6})/',new_url:"http://www.aigaogao.com/tools/history.html?s=%s"}},{page_url:{filter:"history.html\?s=\d{6}", extractby:"//div[@id='ctl16_contentdiv']/", class:'com.web.StockHistoryData'}}] | |
| 2 | =web_crawl(A1) | |
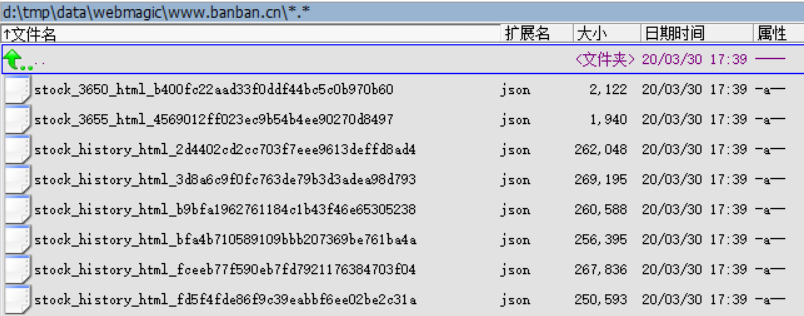
生成结果:
类似针对内容提取或数据存储,参考上面程序的实现,用户可自定义 java 程序。
这篇关于集算器 SPL 抓取网页数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






