本文主要是介绍代码阅读:AAAI 2022 Knowledge Bridging for Empathetic Dialogue Generation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码:GitHub - qtli/KEMP: [AAAI 2022] Knowledge Bridging for Empathetic Dialogue Generation
论文:https://arxiv.org/abs/2009.09708
在这篇代码阅读中,我只分析论文中关于情感上下文图以及情感上下文编码器的部分,一直到论文阅读中的4.3.2情绪信号感知。
论文阅读总结:AAAI 2022 Knowledge Bridging for Empathetic Dialogue Generation_推荐系统YYDS的博客-CSDN博客
下图是整个代码每个文件的大致作用:
| 文件路径 | 功能描述 |
| main.py | 主程序文件,包含加载参数、创建模型、训练和测试等功能 |
| KEMP.py | 实现了Transformer模型的Python代码 |
| common.py | 包含一些常用函数和类,以及辅助函数和第三方库的导入 |
| __init__.py | 初始化或包装的模块文件 |
| common_layer.py | 包含编码器、图和解码器的实现,用于Transformer模型中的注意力机制 |
| dataloader.py | 加载训练和测试数据 |
| utils.py | 包含了权重初始化和评估指标计算的辅助函数 |
| cal_metrics.py | 计算BLEU分数和距离指标的Python脚本 |
| preprocess.py | 数据预处理(ConceptNet,Nrcvad) |
首先从 prepare_data_seq中调用已经预训练好的(preprocess→dataloader)训练,测试,验证集,之后实现KEMP.py,并保存结果
f __name__ == '__main__':print_file = Noneeval_file = open(args.model+'_eval.txt', 'w')data_loader_tra, data_loader_val, data_loader_tst, vocab, program_number = prepare_data_seq(args, batch_size=args.batch_size)print('-----finish loading data--------')model = KEMP(args, vocab, decoder_number=program_number)model_save_path = os.path.join(args.save_path, 'result')if os.path.exists(model_save_path) is False: os.makedirs(model_save_path)log_save_path = os.path.join(args.save_path, 'save')if os.path.exists(log_save_path) is False: os.makedirs(log_save_path)for n, p in model.named_parameters():if p.dim() > 1 and (n != "embedding.lut.weight" and args.pretrain_emb):xavier_uniform_(p)print("MODEL USED", args.model, file=print_file)print("TRAINABLE PARAMETERS", count_parameters(model), file=print_file)1 情感上下文图 对应preprocess.py
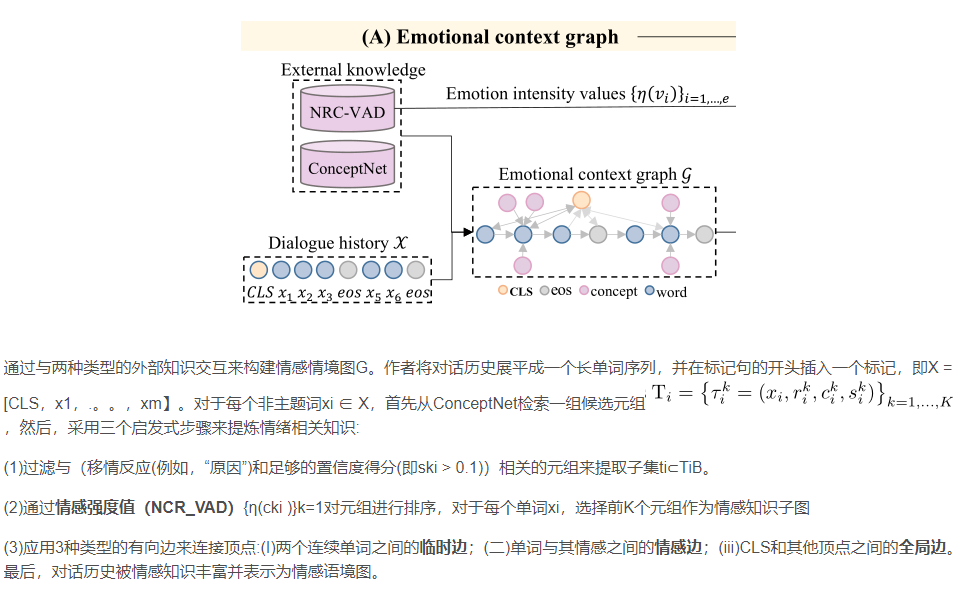
preprocess.py
def clean(sentence, word_pairs):
###1:对句子进行预处理。它将句子转换为小写,并使用 word_pairs 字典中的键值对进行替换。这些替换是为了将常见的缩写和缩写形式转换为全写形式。例如,将 "it's" 替换为 "it is"。
2:定义了特殊词的索引, UNK(未知词)、PAD(填充)、EOS(结束)、SOS(开始)、USR(用户说话状态)、SYS(系统监听状态)、KG(概念状态)、CLS(分类标记)和 SEP(分隔符)def index_word(word、sentence):
###将一个词、句子索引化,即将其添加到词汇表中def read_emp_dataset():
###读取并处理数据集。加载训练集、验证集和测试集的对话、目标、情感和情境数据,并进行预处理1 定义了一个名为 word_pairs 的字典,其中包含一些常见缩写词和它们的全写形式,用于清理句子。2 加载训练集的对话、目标、情感和情境数据,并将它们进行清理和索引化,存储在 data_train 字典中。3对开发集和测试集进行相同的处理,分别存储在 data_dev 和 data_test 字典中。4构建了一个包含词汇表信息的列表 vocab,其中包括 word2index、word2count、index2word 和词汇表的大小。def gen_embeddings():embeddings = np.random.randn(n_words, emb_dim) * 0.01print('Embeddings: %d x %d' % (n_words, emb_dim))if emb_file is not None:print('Loading embedding file: %s' % emb_file)pre_trained = 0for line in open(emb_file).readlines():sp = line.split()if(len(sp) == emb_dim + 1):if sp[0] in word2index:pre_trained += 1embeddings[word2index[sp[0]]] = [float(x) for x in sp[1:]]else:print(sp[0])print('Pre-trained: %d (%.2f%%)' % (pre_trained, pre_trained * 100.0 / n_words))return embeddings###函数用于生成初始的词嵌入矩阵。如果给定了词嵌入文件(例如GloVe),则会尝试从文件中加载预训练的词向量。如果一个词不在词嵌入文件中或者没有提供词嵌入文件,将使用随机初始化的向量作为该词的嵌入表示。
创建一个大小为 (n_words, emb_dim) 的随机初始化的词嵌入矩阵 embeddings;加载预训练的词向量(Glove)。遍历词嵌入的每一行,将其拆分为单词和向量。如果拆分后的长度等于 emb_dim + 1,表示该行包含有效的词和词向量。检查该词是否在 word2index 中,如果存在,则将其对应的索引位置的词嵌入向量更新为从文件中读取的向量。同时,增加 pre_trained 计数器的值。情感强度值计算方法: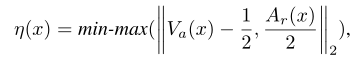
def emotion_intensity(NRC, word):'''Function to calculate emotion intensity (Eq. 1 in our paper):param NRC: NRC_VAD vectors:param word: query word:return:'''v, a, d = NRC[word]a = a/2return (np.linalg.norm(np.array([v, a]) - np.array([0.5, 0])) - 0.06467)/0.607468![]()
def get_concept_dict():with open('EmpatheticDialogue/dataset_preproc.json', "r") as f:[data_tra, data_val, data_tst, vocab] = json.load(f)word2index, word2count, index2word, n_words = vocabembeddings = gen_embeddings(n_words, word2index)VAD = json.load(open("VAD.json", "r", encoding="utf-8")) # NRC_VADCN = csv.reader(open("assertions.csv", "r", encoding="utf-8")) # ConceptNet raw fileconcept_dict = {}concept_file = open("ConceptNet.json", "w", encoding="utf-8")relation_dict = {}rd = open("relation.json", "w", encoding="utf-8")for i, row in enumerate(CN):if i%1000000 == 0:print("Processed {} rows".format(i))items = "".join(row).split("\t")c1_lang = items[2].split("/")[2]c2_lang = items[2].split("/")[2]if c1_lang == "en" and c2_lang == "en":if len(items) != 5:print("concept error!")relation = items[1].split("/")[2]c1 = items[2].split("/")[3]c2 = items[3].split("/")[3]c1 = wnl.lemmatize(c1)c2 = wnl.lemmatize(c2)weight = literal_eval("{" + row[-1].strip())["weight"]if weight < 1.0: # filter tuples where confidence score is smaller than 1.0continueif c1 in word2index and c2 in word2index and c1 != c2 and c1.isalpha() and c2.isalpha():if relation not in word2index:if relation in relation_dict:relation_dict[relation] += 1else:relation_dict[relation] = 0c1_vector = torch.Tensor(embeddings[word2index[c1]])c2_vector = torch.Tensor(embeddings[word2index[c2]])c1_c2_sim = torch.cosine_similarity(c1_vector, c2_vector, dim=0).item()v1, a1, d1 = VAD[c1] if c1 in VAD else [0.5, 0.0, 0.5]v2, a2, d2 = VAD[c2] if c2 in VAD else [0.5, 0.0, 0.5]emotion_gap = 1-(abs(v1-v2) + abs(a1-a2))/2# <c1 relation c2>if c2 not in stop_words:c2_vad = emotion_intensity(VAD, c2) if c2 in VAD else 0.0# score = c2_vad + c1_c2_sim + (weight - 1) / (10.0 - 1.0) + emotion_gapscore = c2_vad + emotion_gapif c1 in concept_dict:concept_dict[c1][c2] = [relation, c2_vad, c1_c2_sim, weight, emotion_gap, score]else:concept_dict[c1] = {}concept_dict[c1][c2] = [relation, c2_vad, c1_c2_sim, weight, emotion_gap, score]# reverse relation <c2 relation c1>if c1 not in stop_words:c1_vad = emotion_intensity(VAD, c1) if c1 in VAD else 0.0# score = c1_vad + c1_c2_sim + (weight - 1) / (10.0 - 1.0) + emotion_gapscore = c1_vad + emotion_gapif c2 in concept_dict:concept_dict[c2][c1] = [relation, c1_vad, c1_c2_sim, weight, emotion_gap, score]else:concept_dict[c2] = {}concept_dict[c2][c1] = [relation, c1_vad, c1_c2_sim, weight, emotion_gap, score]print("concept num: ", len(concept_dict))json.dump(concept_dict, concept_file)relation_dict = sorted(relation_dict.items(), key=lambda x: x[1], reverse=True)json.dump(relation_dict, rd)1 从预处理的数据文件中加载数据集和词汇表(dataset_preproc.json);
2 获取词汇表相关信息,包括词到索引的映射(word2index),词频统计(word2count),索引到词的映射(index2word),以及词的总数(n_words)
3 gen_embeddings() 函数生成词嵌入矩阵(embeddings)
4 加载Nrcvad和ConceptNet
5 遍历ConceptNet的每一行(1提取关系(relation)、conceptnet概念1(c1)和conceptnet概念2(c2)等信息,2过滤掉语言不是英语("en")的词,3获取概念1和概念2的词嵌入向量,计算它们之间的余弦相似度,4获取概念1和概念2的情感向量(VAD值),计算情感差异(emotion_gap)和得分(score,5将概念2及其相关信息添加到概念1的字典项中,同时将概念1及其相关信息添加到概念2的字典项中)
![]()
def rank_concept_dict():concept_dict = json.load(open("ConceptNet.json", "r", encoding="utf-8"))rank_concept_file = open('ConceptNet_VAD_dict.json', 'w', encoding='utf-8')rank_concept = {}for i in concept_dict:# [relation, c1_vad, c1_c2_sim, weight, emotion_gap, score] relation, weight, scorerank_concept[i] = dict(sorted(concept_dict[i].items(), key=lambda x: x[1][5], reverse=True)) # 根据vad由大到小排序rank_concept[i] = [[l, concept_dict[i][l][0], concept_dict[i][l][1], concept_dict[i][l][2], concept_dict[i][l][3], concept_dict[i][l][4], concept_dict[i][l][5]] for l in concept_dict[i]]json.dump(rank_concept, rank_concept_file, indent=4)

read_our_dataset:
###
打开数据集,并加载训练集、验证集、测试集和词汇表的数据。
将列表中的数据分别赋值给data_tra、data_val、data_tst和vocab变量,以便后续处理使用。
加载VAD.json,结果是一个包含情感强度字典的数据。
加载ConceptNet_VAD_dict.json的文件,结果是一个包含conceptnet概念字典的数据。
初始化空列表,用于存储不同类型的数据,如单词、情感强度等。
开始处理训练集(train set):遍历每个训练样本,对于每个样本的每个句子,执行以下操作:使用nltk.pos_tag函数对句子中的每个单词进行词性标注,得到单词和对应的词性。根据单词的词性,查找情感强度字典(VAD)中对应的情感强度向量。如果单词在词汇表中,并且在情感强度字典中存在对应的情感强度向量,则将该情感强度向量添加到列 表中;否则,添加一个默认的情感强度向量。计算句子中每个单词的情感强度,如果单词在情感强度字典中存在,则使用其情感强度值;否则,使用 默认值0.0。获取句子中每个单词的conceptnet概念列表,仅保留满足条件的概念(不是停用词、在词汇表中、符合词性要求 等)。对每个单词的conceptnet概念列表进行处理,限制概念的数量,并将概念、情感强度向量和情感强度添加到相应的 列表中。将处理后的概念列表、情感强度向量列表和情感强度列表添加到训练集数据中。
对验证集(valid set)和测试集(test set)执行与训练集相似的操作,将处理后的数据添加到相应的列表中。
最后就是整个preproces是步骤了:
(1)read_emp_dataset读取数据集,并将返回的数据存储在训练集,验证集,测试集和vocab
(2)get_concept_dict函数,这个函数的作用是获取conceptnet概念字典
(3)rank_concept_dict函数,根据情感强度值是对conceptnet概念字典进行排序
(4)read_our_dataset函数读取数据集,并将返回的数据存储在训练集,验证集,测试集和vocab
情感上下文编码器
super(Encoder, self).__init__()self.args = argsself.universal = universalself.num_layers = num_layersself.timing_signal = _gen_timing_signal(max_length, hidden_size)if(self.universal): ## for tself.position_signal = _gen_timing_signal(num_layers, hidden_size)params =(hidden_size, total_key_depth or hidden_size,total_value_depth or hidden_size,filter_size, num_heads, _gen_bias_mask(max_length) if use_mask else None,layer_dropout, attention_dropout, relu_dropout)self.embedding_proj = nn.Linear(embedding_size, hidden_size, bias=False)if(self.universal):self.enc = EncoderLayer(*params)else:self.enc = nn.ModuleList([EncoderLayer(*params) for _ in range(num_layers)])self.layer_norm = LayerNorm(hidden_size)self.input_dropout = nn.Dropout(input_dropout)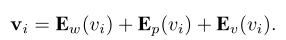
def forward(self, inputs, mask):#Add input dropoutx = self.input_dropout(inputs)# Project to hidden sizex = self.embedding_proj(x)if(self.universal):if(self.args.act): # Adaptive Computation Timex, (self.remainders, self.n_updates) = self.act_fn(x, inputs, self.enc, self.timing_signal, self.position_signal, self.num_layers)y = self.layer_norm(x)else:for l in range(self.num_layers):x += self.timing_signal[:, :inputs.shape[1], :].type_as(inputs.data)x += self.position_signal[:, l, :].unsqueeze(1).repeat(1,inputs.shape[1],1).type_as(inputs.data)x = self.enc(x, mask=mask)y = self.layer_norm(x)else:# Add timing signalx += self.timing_signal[:, :inputs.shape[1], :].type_as(inputs.data)for i in range(self.num_layers):x = self.enc[i](x, mask)y = self.layer_norm(x)return y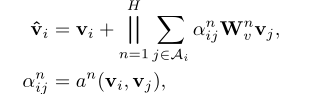
def concept_graph(self, context, concept, adjacency_mask):''':param context: (bsz, max_context_len, embed_dim):param concept: (bsz, max_concept_len, embed_dim):param adjacency_mask: (bsz, max_context_len, max_context_len + max_concpet_len):return:'''# target = self.W_sem_emo(context) # (bsz, max_context_len, emb_dim)# concept = self.W_sem_emo(concept)target = contextsrc = torch.cat((target, concept), dim=1) # (bsz, max_context_len + max_concept_len, emb_dim)# QK attentionq = self.W_q(target) # (bsz, tgt_len, emb_dim)k, v = self.W_k(src), self.W_v(src) # (bsz, src_len, emb_dim); (bsz, src_len, emb_dim)attn_weights_ori = torch.bmm(q, k.transpose(1, 2)) # batch matrix multiply (bsz, tgt_len, src_len)adjacency_mask = adjacency_mask.bool()attn_weights_ori.masked_fill_(adjacency_mask,1e-24) # mask PADattn_weights = torch.softmax(attn_weights_ori, dim=-1) 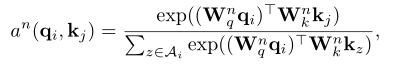
这篇关于代码阅读:AAAI 2022 Knowledge Bridging for Empathetic Dialogue Generation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





