本文主要是介绍【论文笔记】Knowledge Bridging for Empathetic Dialogue Generation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Knowledge Bridging for Empathetic Dialogue Generation
文章目录
- Knowledge Bridging for Empathetic Dialogue Generation
- 1. Motivation
- 2. Main idea
- 3. Model
- 3.1 Emotional Context Graph
- 3.2 Emotional Context Encoder
- 3.3 Emotion-dependency Decoder
- 3.4 KEMP-DialoGPT
会议:AAAI 2022
任务:共情对话生成
代码:项目地址
原文:论文地址
1. Motivation
人类通常依靠经验和外部知识来认知隐式情绪,人们需要更多的外部知识来做出共情回应。在对话过程中,说话人的请求和另一方的回复往往存在一定不对称的 Gap,回复中有时会出现一些请求中未涉及的新信息。我们需要将知识作为桥梁,从而对信息之间的关联建模。
另外,在共情对话中,情绪依赖(听者回复的情绪和说者表达的情绪一致) 和情绪惯性通常与外部知识一起出现。
2. Main idea
提出了融合常识知识和情感词汇知识的共情对话生成模型KEMP。首先通过与外部知识进行交互来丰富对话历史,构建情绪上下文图。然后从知识丰富的情绪上下文图中学习情感上下文表征,提取情感信号。最后,本文提出了一个情感交叉注意力机制来学习从情绪上下文图中得到的情感依赖。
-
常识知识使用ConceptNet,每个知识元组定义为:(head concept, relation, tail concept, confidence score)
-
情感词汇知识使用NRC_VAD,包含20K个英文单词,每个单词都包含一个三维向量( V a , A r , D o V_a,A_r,D_o Va,Ar,Do)。定义情感强度值为:

3. Model
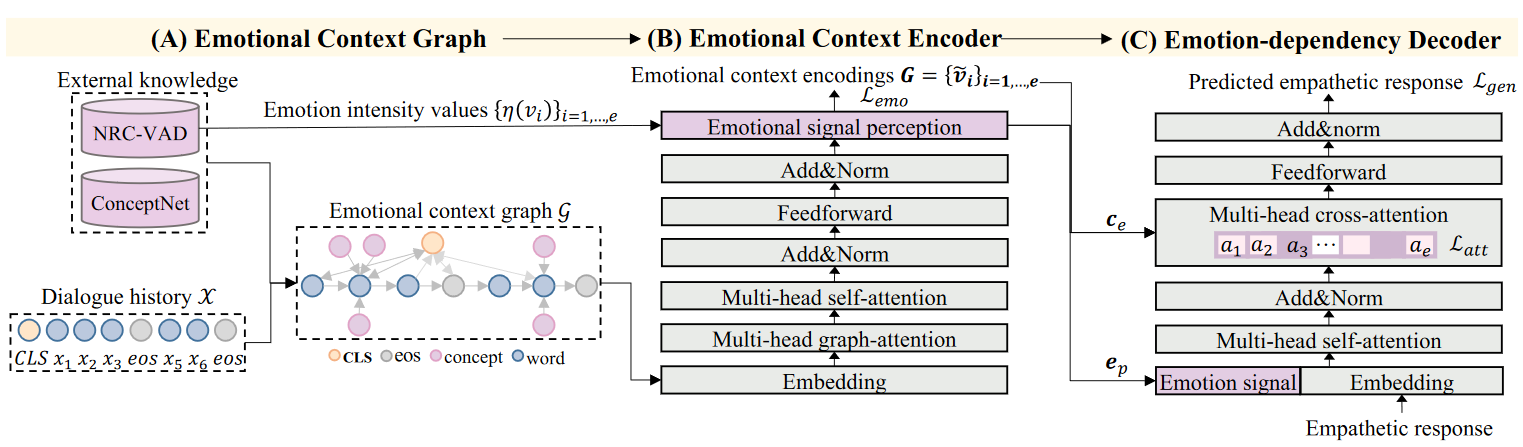
3.1 Emotional Context Graph
-
检索外部知识、构建情绪上下文图
给定对话历史,拼接成一个长文本序列,对于每个非停用词,首先到ConceptNet中检索一系列候选三元组。然后通过三个启发式策略重定义情感相关的知识:
- 抽取具有情绪相关关系(如"Causes")的边并具有足够置信度的三元组;
- 对于检索到的概念实体,使用VAD中的情感强度值对它们进行排序,选择top-K个三元组作为情感知识子图;
- 建立三种边:时序边(连接两个连续的单词)、情绪边(连接一个单词及其情绪实体)、全局边(连接开始符CLS和其他结点)
3.2 Emotional Context Encoder
-
Emotional Context Graph Encoding
-
嵌入
使用三种Embedding对情绪上下文图进行编码,分别是词嵌入、位置嵌入以及新增加的结点状态嵌入,结点状态嵌入用于表示一个单词是对话历史中的单词还是外部知识中的单词。
-
多头图注意力机制
使用多头图注意力机制更新结点表征。每个结点进行上下文化,具体而言,通过与其直接相邻的邻接结点进行局部的注意力交互。
经过嵌入和多头图注意力交互后的特征,会进入常规的Transformer模块中,进行全局交互。
最终得到每个结点的编码后的表示。
-
-
Emotional Signal Perception
- 情绪信号表征定义为顶点表征和情绪强度值得加权求和;
- 然后通过一个线性层和Softmax将情绪信号向量投影到情绪类别分布中,其中,经过线性层学习后的表征为情绪信号;
3.3 Emotion-dependency Decoder
为了从情绪上下文图中获取情绪依赖并控制共情回复表达,通过将情绪信号经过线性层映射为一个新的向量,然后在每个时间步将其与解码器的输入词嵌入进行拼接。
为了提高情绪上下文图和目标共情回复之间的情绪以来,本文设计了两个情绪策略:融合情绪特征和强制情绪注意力损失。
-
Incorporating Emotional Features
在Decoder的多头交叉注意力层,计算上一个输出词和Encoder输出的情绪上下文图的每个结点表示之间的注意力,得到了对话上下文向量;
为了对话回复中的共情表达能力,将对话上下文向量和情绪信号表征进行拼接,得到情绪上下文向量。然后输入后续的Transformer Decoder模块中。
-
Enforcing Emotional Attention Loss
- 在对话中,人们自然地会将注意力放在具有显著情绪信息的表达中。因为,本文设计了强制情绪注意力损失,使得模型更关注于具有高情绪强度的结点,具体如下:
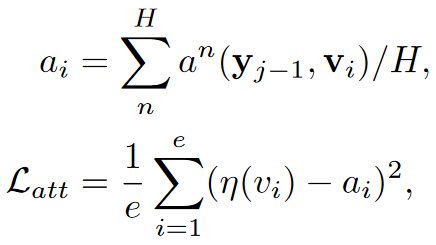
该公式首先对每个结点的注意力头取平均,然后最小化每个结点情绪强度及其注意力值之间的均 方误差(MSE),这样设计使得情绪强度值高的结点注意力权重更大。
-
此外,为了计算从输入的图中复制一个实体概念结点的概率,这里借鉴了文本摘要中指针生成网络PGN的方法:
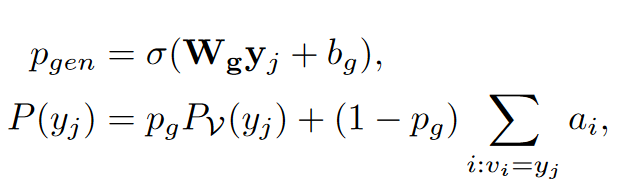
最终的损失是多任务学习形式,同时优化情绪标签预测、文本生成、情绪注意力三个损失的加权和。
3.4 KEMP-DialoGPT
通过把情绪上下文编码器的图注意力层和情绪依赖解码器的交叉注意力层融合到DialoGPT中,把KEMP整合到了预训练语言模型中。
这篇关于【论文笔记】Knowledge Bridging for Empathetic Dialogue Generation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








