本文主要是介绍高光谱分类论文解读分享之Grid Network: 基于各向异性视角下特征提取的高光谱影像分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
IEEE GRSL 2023:Grid Network: 基于各向异性视角下特征提取的高光谱影像分类
题目
Grid Network: Feature Extraction in Anisotropic Perspective for Hyperspectral Image Classification
作者
Zhonghao Chen , Student Member, IEEE, Danfeng Hong , Senior Member, IEEE, and Hongmin Gao , Member, IEEE
关键词
Anisotropic, feature fusion, hyperspectral (HS) images, semantic gap, spectral–spatial feature.
研究动机
考虑高光谱影像内部空间和光谱特征各向异性的特性,探索一种区别于现有其他空-谱特征提取方法的新思路
模型
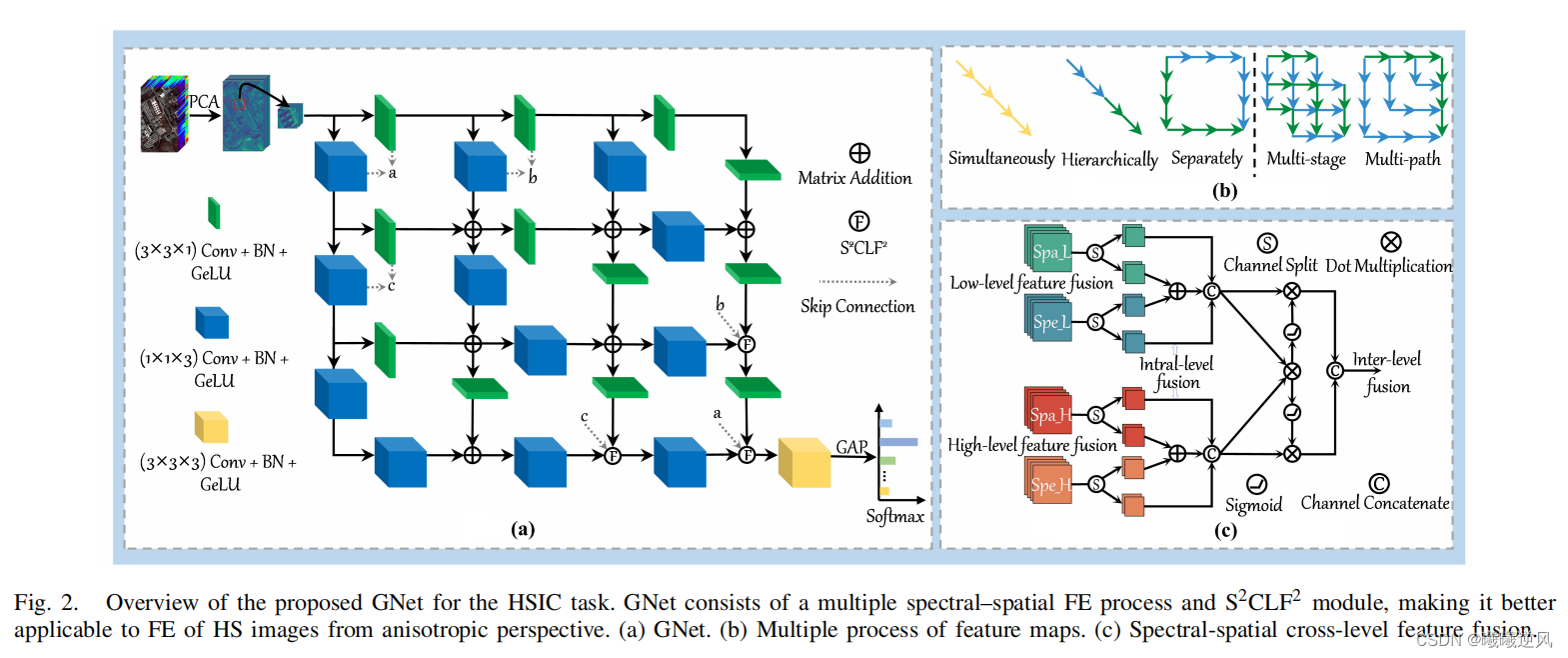
高光谱(HS)图像中嵌入了丰富的光谱特征和空间特征,能够精细地识别土地覆盖,吸引了对特征提取(FE)和特征利用的大量研究。然而,HS立方体中具有高代表性的光谱和空间特征分布不均匀,这是目前许多方法都没有考虑到的。为了克服这一缺点,我们从各向异性的角度重新考虑了HS图像的有限元问题,提出了一种新的网格网络(GNet)的HS图像分类模型(HSIC)模型。除了用三种经典范式(同时、层次和分别)表示光谱空间特征外,GNet还能够在两个新的过程中学习它们:多阶段和多路径。这样,就可以充分和平衡地探索光谱和空间特征。更重要的是,为了充分利用低、高两级特征,避免现有的语义差距,我们设计了一个光谱-空间交叉级特征融合(S2CLF2)模块来建模它们之间的关系。在三个HS数据集上进行的大量实验表明,所提出的GNet非常有效。
亮点
- 首次从各向异性的角度研究了HS图像特征提取,使得光谱和空间特征可以在多个过程中进行探索,从而使模型能够更自由地提取平衡表示进行分类。
- 在相关信息的指导下融合低级和高级特征,减轻了语义差距的影响。
论文以及代码
论文链接: link
代码链接: link
这篇关于高光谱分类论文解读分享之Grid Network: 基于各向异性视角下特征提取的高光谱影像分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




