本文主要是介绍k8s pod数据存储Volumes,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、说在前面的话
在 Kubernetes 的 Deployment 中,您可以使用多种类型的 Volumes 来管理 Pod 中的数据。
作用是用来共享目录及配置,不用在每个pod里进行配置。
本文主要概述怎么使用HostPath、PersistentVolumeClaim、ConfigMap。
二、k8s有哪些Volumes
来自chatgpt
以下是一些常见的 Volume 类型:1. **EmptyDir**: 这是一个临时目录,在 Pod 被调度到 Node 上时创建,Pod 终止时被删除。可以用于容器之间共享临时数据。2. **HostPath**: 将宿主机的文件或目录挂载到 Pod 中。在一些特定场景中可能会用到,但要注意宿主机文件的权限和共享问题。3. **PersistentVolumeClaim (PVC)**: PVC 是与持久卷 (Persistent Volume, PV) 绑定的声明,它表示 Pod 对持久卷的需求。通过 PVC,Pod 可以请求特定的持久存储。4. **ConfigMap**: ConfigMap 可以用于将配置文件或配置数据注入到 Pod 中。可以用于配置容器的环境变量、配置文件等。5. **Secret**: Secret 类型的 Volume 用于将敏感信息(如密码、凭据等)安全地注入到 Pod 中。6. **NFS**: 允许将 NFS (Network File System) 挂载到 Pod 中,用于实现持久化存储。7. **Azure Disk/Azure File**: Azure Cloud 提供的磁盘和文件存储,在 Azure Kubernetes Service (AKS) 中常用。8. **GCE Persistent Disk**: Google Cloud 提供的持久磁盘,在 Google Kubernetes Engine (GKE) 中常用。9. **AWS Elastic Block Store (EBS)**: Amazon Web Services (AWS) 提供的块存储,在 Amazon Elastic Kubernetes Service (EKS) 中常用。10. **Ceph RBD**: Ceph 是一个分布式存储系统,RBD (Rados Block Device) 可以用于在 Pod 中挂载 Ceph 存储。这些是 Kubernetes 中常见的 Volume 类型,您可以根据应用的需求选择合适的 Volume 类型来管理 Pod 的数据。
下面,我将选几种volumes进行详细说明。
三、PersistentVolumeClaim (PVC)
1、deployment.yaml
- {{.Values.appName}} 为项目名称,这里都以xx-job为例。
- 注意,这里有一个subPath,值是xx-job
containers: volumeMounts:- mountPath: /opt/xxx/{{ .Values.appName }}/resourcesname: volume-resourcessubPath: {{ .Values.appName }}volumes:- name: volume-resourcespersistentVolumeClaim:claimName: application-resources
2、创建pvc

kind: PersistentVolumeClaim
apiVersion: v1
metadata:
# pvc的名称,对应上文的claimNamename: application-resources
# 命名空间,必须填写,和Pod的namespace在一起namespace: java-service
spec:accessModes:- ReadWriteManyresources:requests:storage: 10Gi# 需要先创建存储类:Storage Class,或者指定已创建好的volumeNamestorageClassName: managed-nfs-storagevolumeMode: Filesystem# 如果没有像下面这样指定volumeName,则需要指定存储类storageClassName# volumeName: nfs-mvn-repo

创建成功,见下图:

如此,它会自动创建pv:pvc-25c8493c-d820-49c4-b523-111c86ceaa6d

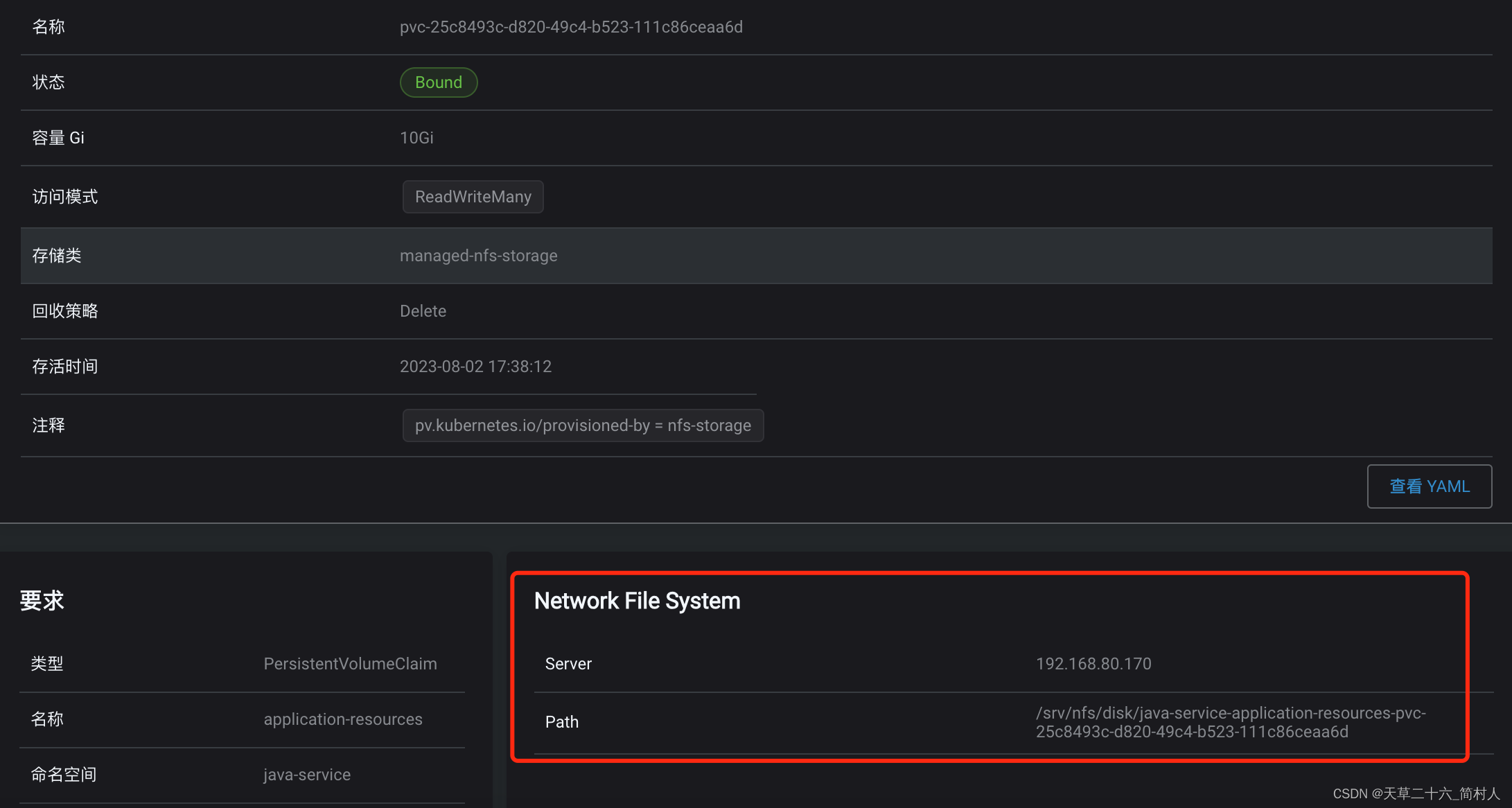
验证是否已创建了持久化卷。

- 可以看到,目录下已创建了子目录xx-job。
# 挂载nfs
mount -t nfs 192.168.80.170:/srv/nfs/disk /mnt/nfs/# 各个pod之间共享目录xx-job下的内容
root@dev-vm-k8s-master:/mnt/nfs/java-service-application-resources-pvc-25c8493c-d820-49c4-b523-111c86ceaa6d# ll
total 8
drwxrwxrwx 3 root root 28 Aug 2 09:30 ./
drwxr-xr-x 33 root root 4096 Aug 3 00:35 ../
drwxrwxrwx 2 root root 10 Aug 2 09:30 xx-job/
四、HostPath
使用示例:
containers:volumeMounts:- mountPath: /etc/localtimename: volume-localtimevolumes:- hostPath:path: /etc/localtimetype: ''name: volume-localtime
五、ConfigMap
可以用于将配置文件或配置数据注入到 Pod 中。可以用于配置容器的环境变量、配置文件等
deployment.yaml引用ConfigMap有好几种方式:
- 使用ConfigMap中的配置
containers:envFrom:- configMapRef:name: {{ .Values.appName }}
- 使用特定的配置项
containers:env:- name: ENV_VAR_NAMEvalueFrom:configMapKeyRef:name: {{ .Values.appName }}key: key-in-configmap
- 挂载的方式
containers:volumeMounts:- mountPath: /opt/xxx/{{ .Values.appName }}/configname: config-volumereadOnly: truevolumes:- configMap:name: {{ .Values.appName }}name: config-volume
创建ConfigMap
kind: ConfigMap
apiVersion: v1
metadata:name: xx-jobnamespace: java-servicelabels:app: xx-job
data:spring.profiles.active: devapplication.yml: |-spring:datasource:url: jdbc:log4jdbc:mysql://192.168.8.19:3306/xxl_job_k8s?zeroDateTimeBehavior=CONVERT_TO_NULL&useUnicode=true&characterEncoding=utf8&autoReconnect=true&failOverReadOnly=false&serverTimezone=Asia/Shanghaiusername: rootpassword: 123456driver-class-name: net.sf.log4jdbc.DriverSpy
Pod节点可以读取到环境变量spring.profiles.active,其值为dev。
另外,你在目录/opt/xxx/xx-job/config已挂载了application.yml和spring.profiles.active。
- 进入pod容器里验证,可以看到已经把ConfigMap(xx-job)内的key、file挂载上来。
/opt/xxx/xx-job/config # ls
spring.profiles.active application.yml
六、总结
不同的Volumes,适用于不同的数据或文件的共享。
在我们的开发过程中,会遇到各种各样的情景:
- 环境变量
- 第三方jar包所依赖的文件,比如Hanlp的data数据
- 支付所需的证书文件
- 字节码技术的java agent jar包,用于数据透传、灰度发布、apm等场景,比如pinpoint/skywalking、transmittable-thread-local等等
这篇关于k8s pod数据存储Volumes的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







