本文主要是介绍2023年全国省市区县行政区划矢量数据(含10段线),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2023年,中国地图面貌发生了重大变化,领土面积由960万平方公里扩大到1045万平方公里,九段线改为了十段线。
因此在使用地图的时候,特别是做全国的地图的时候,一定需要最新的行政界限,今天就将最新的省市县行政界线分享给大家。
登录查看下载地址:https://www.dilitanxianjia.com/13798/
数据范围:中国行政区划及主要城市;
数据属性:行政区划编码、名称等
数据格式:shp数据(arcgis矢量数据格式)、geojson
数据坐标:EPSG:4326
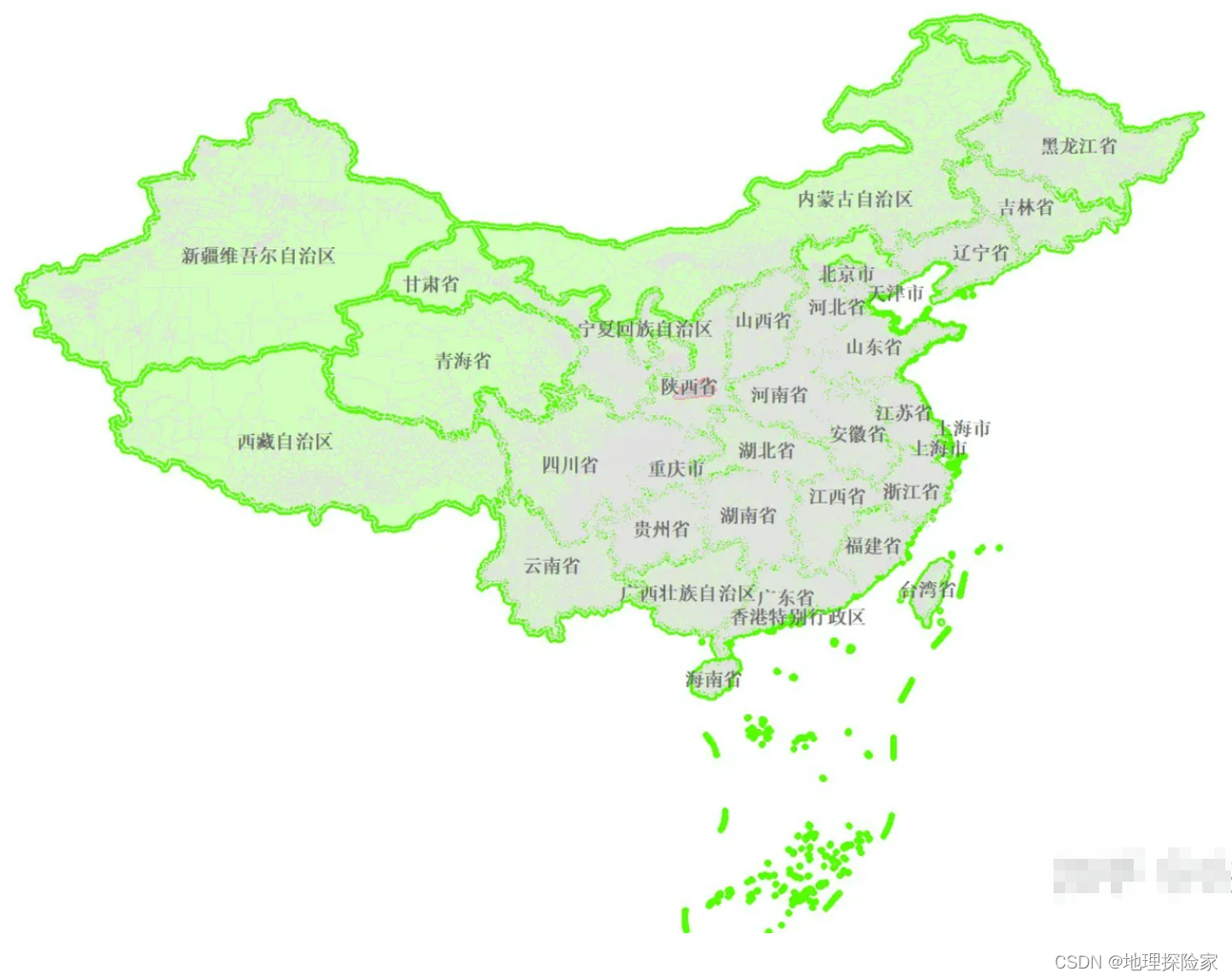
2023年最新版中国地图详细说明:
2023年最新版中国地图,中国国土面积从960万平方公里到1045万平方公里,增加了85万平方公里,东西跨度5200公里,南北跨度5500公里。

实际上领土不仅仅是土地面积这么简单,同时还包括了内海、领海、领空等等。而根据2001年中国国家地理给出的数字,中国实际领土面积达到了1045万平方公里,相比于960万平方公里多出了整整85万平方公里。按照国家地理给出的数据,陆地面积为944万平方公里,岛礁面积7.54万平方公里,滩涂面积达到了1.27万公里,除此之外还有内海和领海。
内海就是指深入大陆内部,与外海之间有狭窄水道相通,主要呈包围结构或者是半包围结构。内海的面积相当广阔,达到了69.3万平方公里。而领海则和其他土地一样,都是国土面积的一部分。
和一般人想象的不同,领海并不是沿着海岸线计算,而是有一个领海基线,领海基线内侧的水域被称为内海,这也是为什么内海水域面积达到69.3万平方公里的主要原因。1982年通过的《联合国海洋法公约》明确表示了各个国家领海的宽度,即从基线算起向外拓展12海里,这个区域内的海洋就是国土不可分割的一部分,包括海洋上的领空、范围内的海床以及物资矿料等等,而当前我们的领海面积为22.8万平方公里。
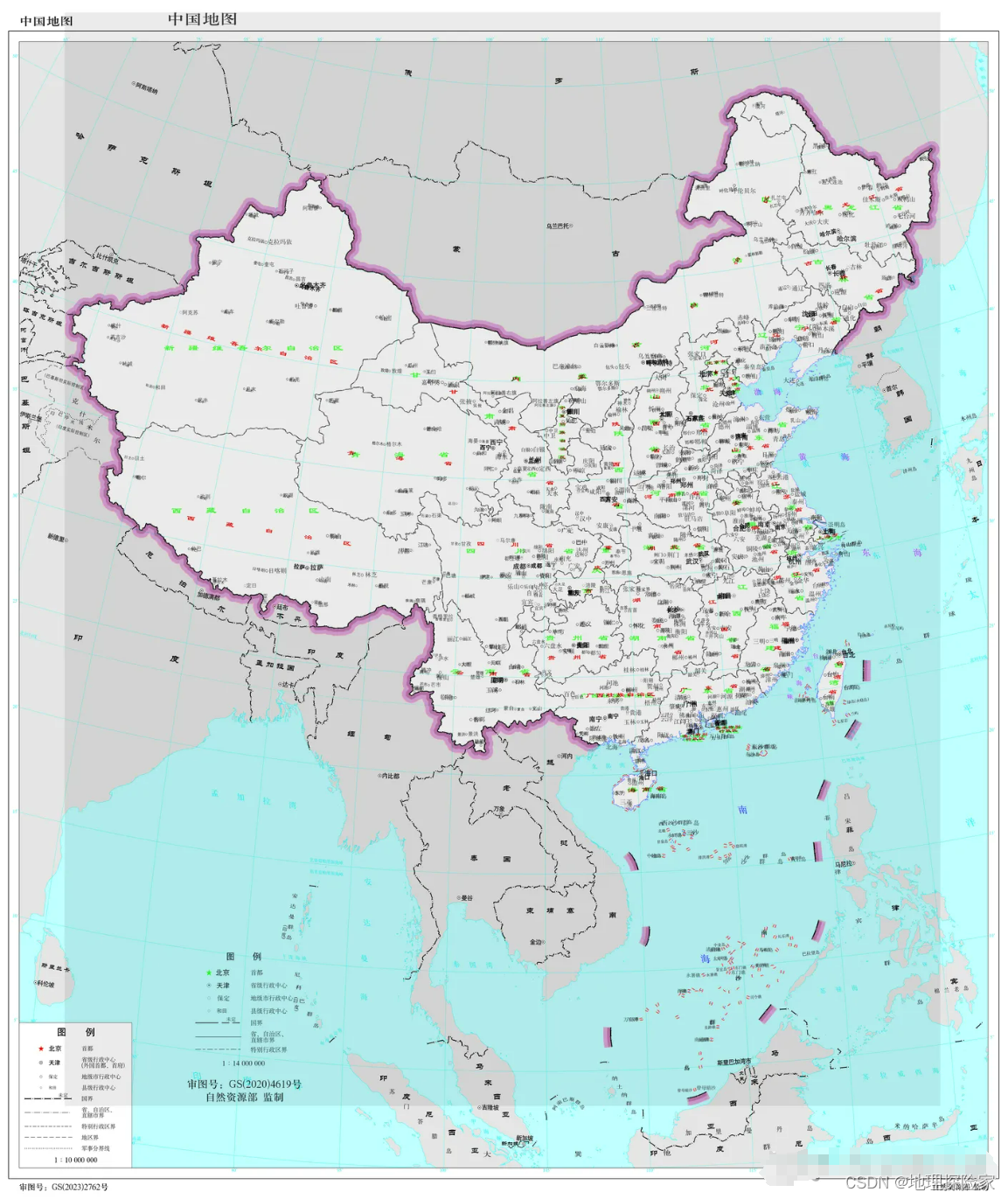
值得注意的地方:
1、首先,国家多年来每年都会发布新的标准版地图。所以本次发布2023年标准版地图并没有什么新奇。
2、自1989版地图以来,至今标准版地图并无大的变化。一般的变化无非是修改一下前一年的行政区划调整,修改新的标注,或者以前没有标注的小的地方名或者山水名称标注上去,甚至将有些礁岛增加上去。
3、新发布的2023版地图相较2022版地图也没有大的变化。细微差异无非是修正之前地图的标注误差问题、更新去年到今年上半年的行政区划调整后的新版本、新的地名(比如撤县设市、撤县设区等)、标注一些之前未标注的小的地名。规范标注一些礁岛名称等;规范标注一些江河胡泊、山脉山峰等;规范标注海岸线等。
4、新发布的2023版地图中关于黑瞎子岛、藏南及中印边界、中塔未定边界线等大家比较关注的问题也均延续以前版本地图的画法,同2022版(之前几十年也均如此),并没有变化。没有变化已经引发大范围讨论,一旦变化了岂不是影响更大?沿用之前的版本也挺好。
5、2023版地图并没有说重新测会的国土面积变大,网传1045万平方公里没有正式的出处,对于网传说法此处不予讨论。之前已经说过对于国土面积每个国家所采取的标准不一,测量技术有差异,测量结果也就不同。在边界线不变的情况下,因为不同测量结算方式所测结果变多变少意义不大。就比如你买房子说的是建筑面积,有些人买到房后又跟别人讲使用面积、套内面积一样,不同的计算方式导致对外的面积有不同版本。再比如工资的计算方式:有人说税前、有人说税后、又有人还要加上公积金等,以至于同样的工资对外就有不同的说法。
这篇关于2023年全国省市区县行政区划矢量数据(含10段线)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






