本文主要是介绍书生·浦语大模型--第三节课笔记--基于 InternLM 和 LangChain 搭建你的知识库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 大模型开发范式
- RAG
- LangChain框架:
- 构建向量数据库
- 构建检索问答链
- 优化建议
- web 部署
- 实践部分
- 环境配置
大模型开发范式
LLM的局限性:时效性(最新知识)、专业能力有限(垂直领域)、定制化成本高(个人专属)
两种开发范式:
- RAG(检索增强生成):外挂知识库,首先匹配知识库文档,交给大模型。优势:成本低,实时更新,不需要训练。但受限于基座模型,知识有限,总结性回答不佳。
- Finetune(微调):轻量级训练微调,可个性化微调,是一个新的个性化大模型。但是需要在新的数据集上训练,更新成本仍然很高,无法解决实时更新的问题。
RAG
- 基本思想
LangChain框架:
通过组件组合进行开发,自由构建大模型应用。将私人数据嵌入到组件中。
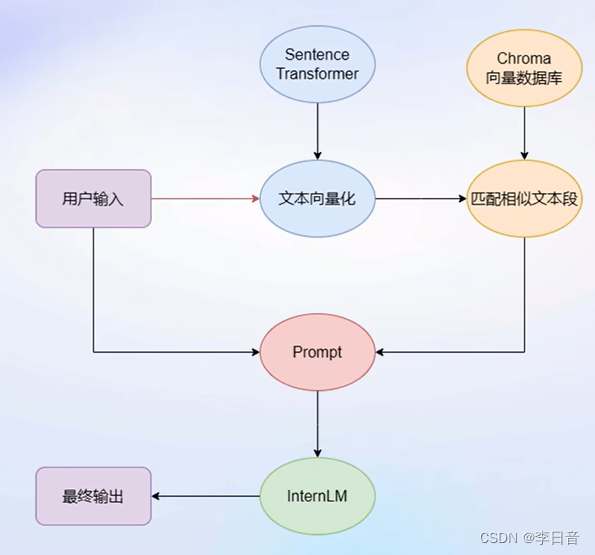
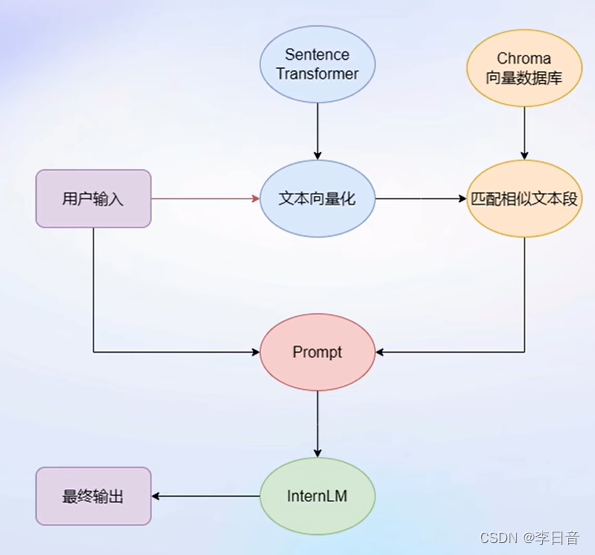
步骤:首先,Unstructed Loader 组件加载本地文档,将不同格式的文档提取为纯文本格式。通过Text Splitter组件对提取的纯文本进行分割成Chunk。再通过开源词向量模型Sentence Transformer来将文本段转化为向量格式,存储到基于Chroma的向量数据库中,接下来对用户的每个输入会通过Sentence Transformer转为为同样维度的向量,通过在向量数据库中进行相似度匹配找到和用户输入的文本段,将相关的文本段嵌入到已经写好的Prompt Template中,最后交给LLM回答即可。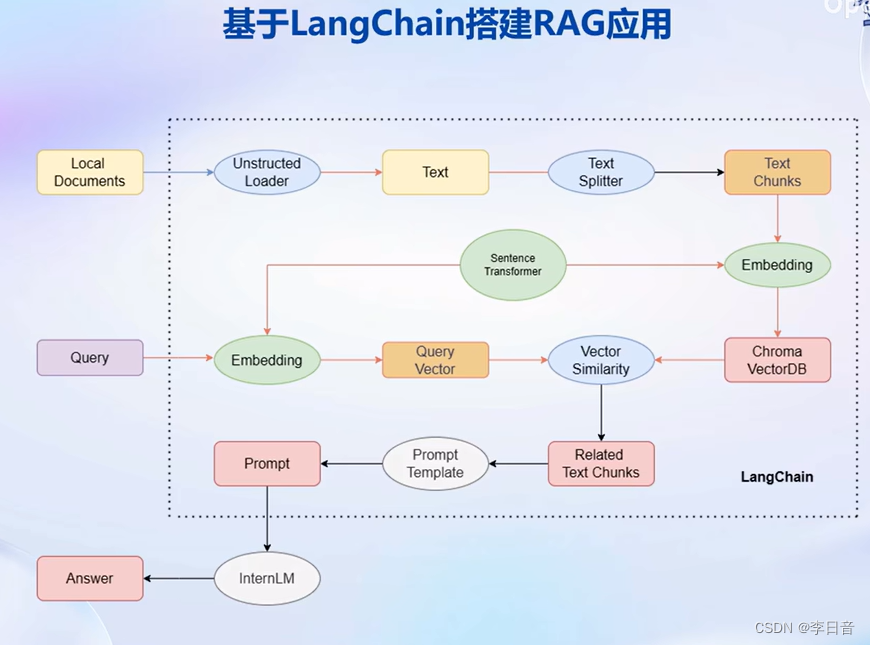
构建向量数据库
基于个人数据构建向量数据库。LangChain支持自定义LLM,可以直接接入到框架中。
- 多种数据类型,针对不同类型选取不同加载器,转化为无格式字符串。
- 由于单个文档超过模型上下文上限,还需要对文档进行切分。
- 使用向量数据库支持语义检索,需要将文本向量化存入向量数据库
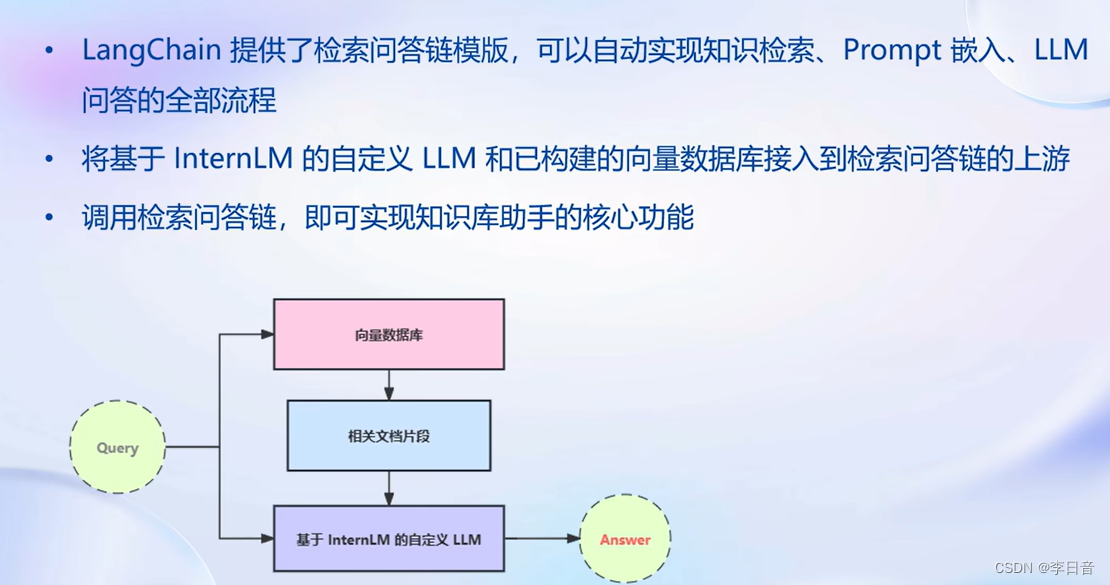
构建检索问答链
自动实现知识检索、Prompt嵌入、LLM问答。
问答性能还有所局限
优化建议
基于语义切分而不是字符串长度。
给每个chunk生成概括性索引。

web 部署
简易框架:Gradio、Streamlit等
实践部分
环境配置
bash
/root/share/install_conda_env_internlm_base.sh InternLMconda activate InternLM# 升级pip
python -m pip install --upgrade pippip install modelscope==1.9.5
pip install transformers==4.35.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.1
模型下载:
直接复制
mkdir -p /root/data/model/Shanghai_AI_Laboratory
cp -r /root/share/temp/model_repos/internlm-chat-7b /root/data/model/Shanghai_AI_Laboratory/internlm-chat-7b
这篇关于书生·浦语大模型--第三节课笔记--基于 InternLM 和 LangChain 搭建你的知识库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








