本文主要是介绍SeaTunnel 海量数据同步工具的使用(连载中……),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

一、概述
SeaTunnel 是一个非常易用,高性能、支持实时流式和离线批处理的海量数据处理产品,前身是 WaterDrop (中文名:水滴),自 2021年10月12日更名为 SeaTunnel 。2021年12月9日,SeaTunnel 正式通过Apache 软件基金会的投票决议,以全票通过的优秀表现正式成为 Apache 孵化器项目。 2022年 3月18日社区正式发布了收个 Apache 版本 V2.1.0。
官网地址:Apache SeaTunnel | Apache SeaTunnel
二、SeaTunnel 的使用场景及其特点
1、使用场景
- 海量数据ETL
- 海量数据聚合
- 多源数据处理
2、特点
- 简单易用,灵活配置,无需开发
- 实时流式处理
- 高性能
- 海量数据处理能力
- 模块化和插件化,易于扩展
- 支持利用SQL做数据处理和聚合
- Spark Structured Streaming
- 支持Spark 2.x
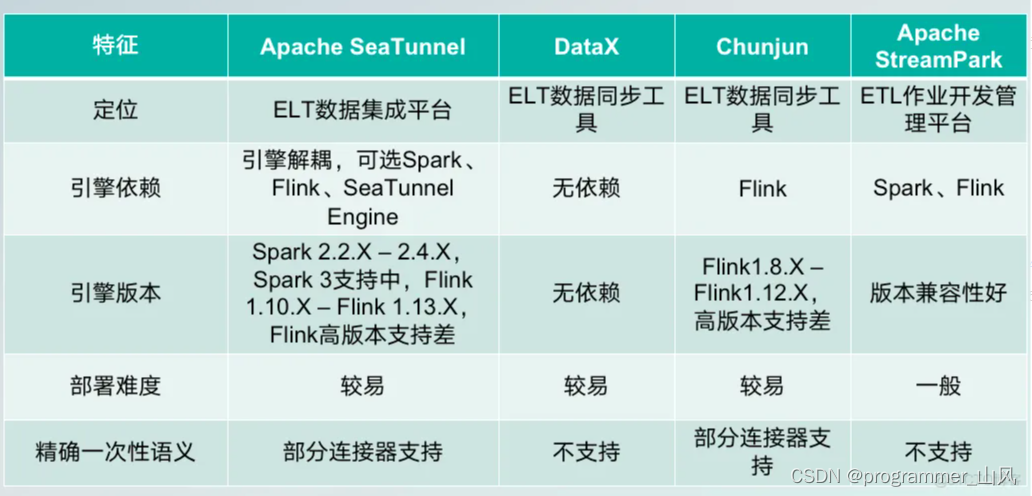
三、SeaTunnel 的工作流程
SeaTunnel 是在 Spark 和 Flink 的基础上做了一层包装,其工作流程图:

其中 SeaTunnel 的引擎:

- Source:数据源输入
- Transform:数据处理
- Sink:结果输出
SeaTunnel 的基本思想是控制反转的设计模式,在我们日常使用中,主要就是编辑配置文件,再指定配置文件启动 SeaTunnel,将其转换为具体的Spark或Flink任务。
四、Linux 下安装 SeaTunel 步骤
1、下载安装包
官网下载地址:Apache SeaTunnel

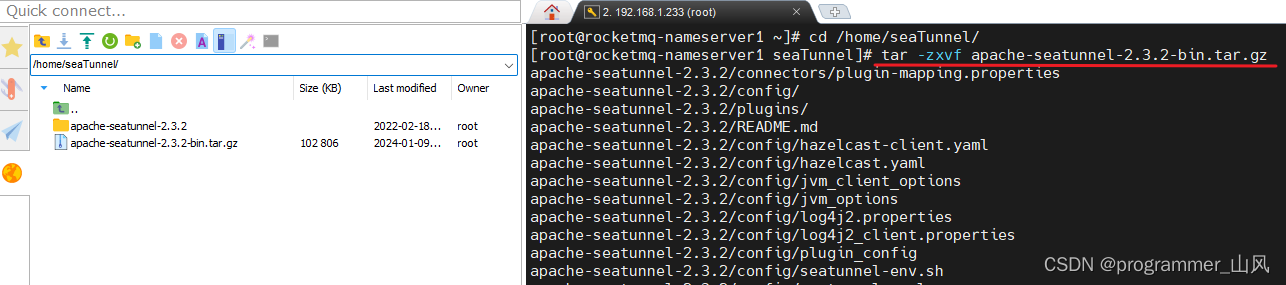
2、上传 Linux 服务器后,解压缩
命令: tar -zxvf apache-seatunnel-2.3.2-bin.tar.gz
3、下载连接器插件
从 seatunnel v2.2.0开始,二进制包默认不提供连接器依赖,所以第一次使用时,我们需要下载连接器。
具体说明位置在:/home/seaTunnel/apache-seatunnel-2.3.2/config/plugin_config
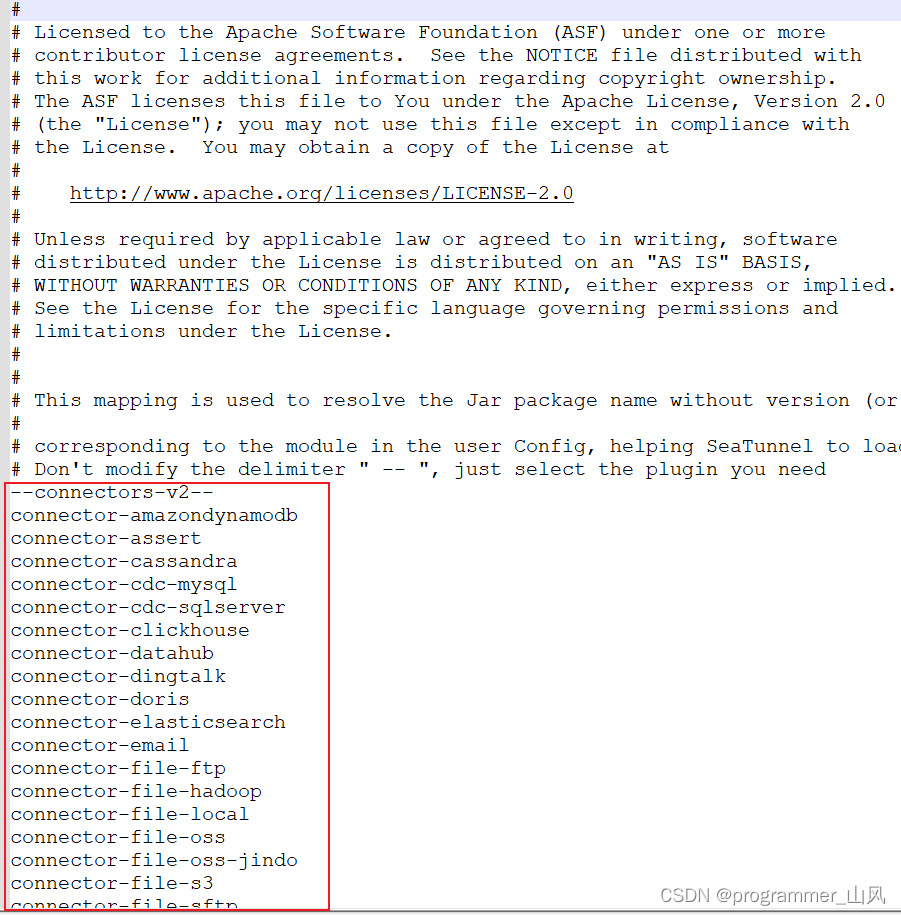
大家一定要挑选自己需要的包下载!!!不用的注释掉!!!
开始下载:./bin/install-plugin.sh

下载的好慢,随便截两张图……

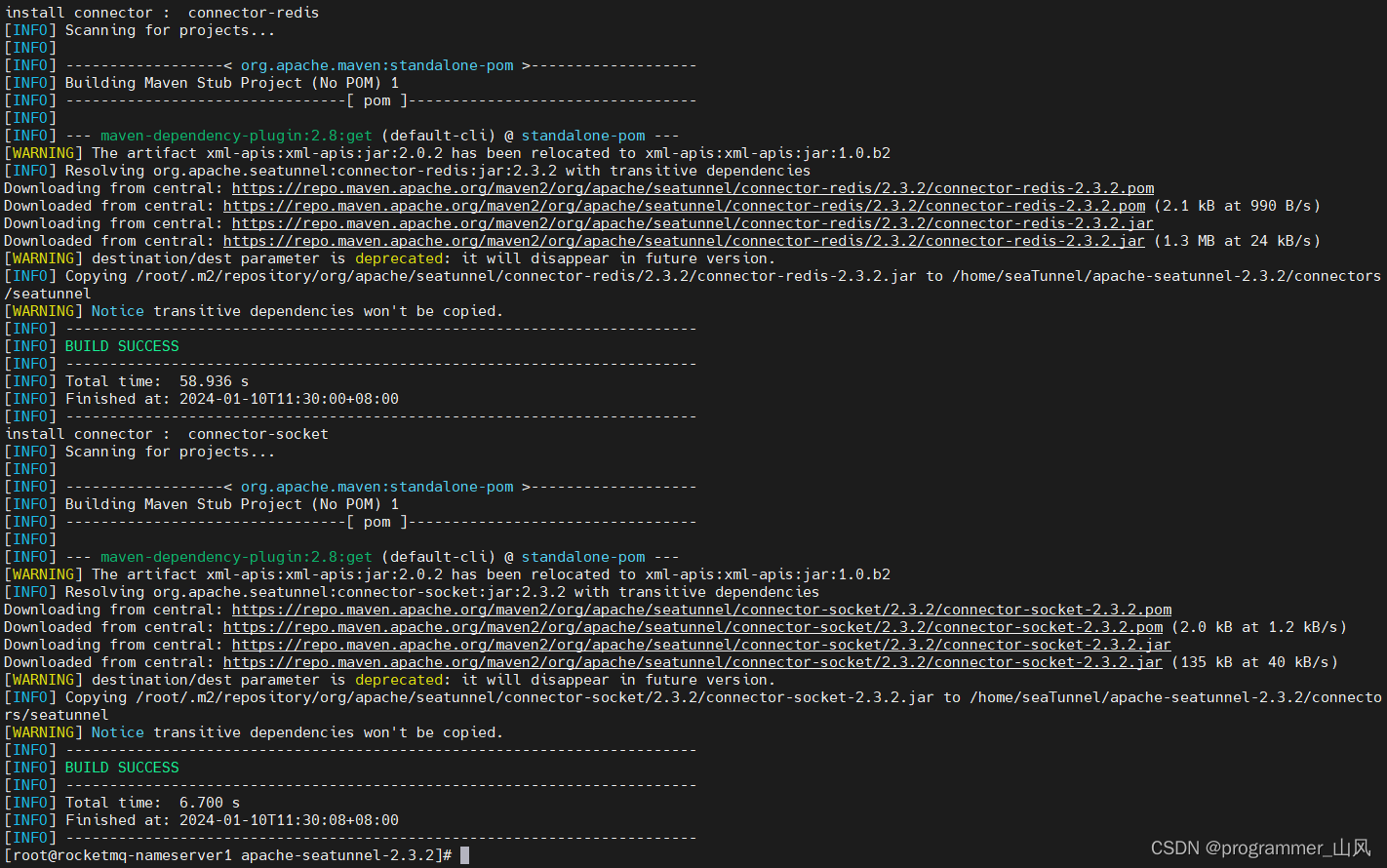
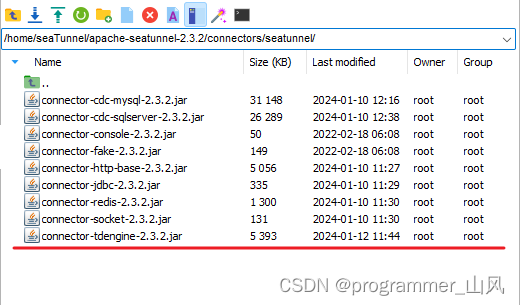
下载的jar包会存放到:/home/seaTunnel/apache-seatunnel-2.3.2/connectors/seatunnel/
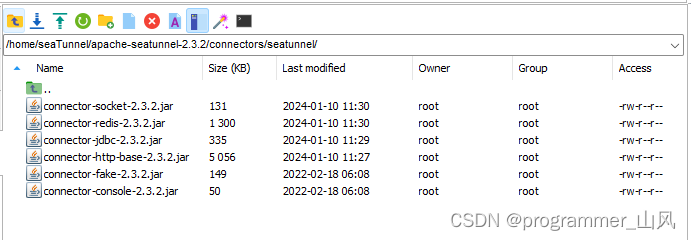
手动下载地址:Central Repository: org/apache/seatunnel
五、Linux 下安装 Flink
1、下载安装包
官网下载地址:Downloads | Apache Flink
2、上传 Linux 服务器,解压缩
命令:tar -zxvf flink-1.18.0-bin-scala_2.12.tgz

3、启动时报错:

【解决方法】更换启动方式:
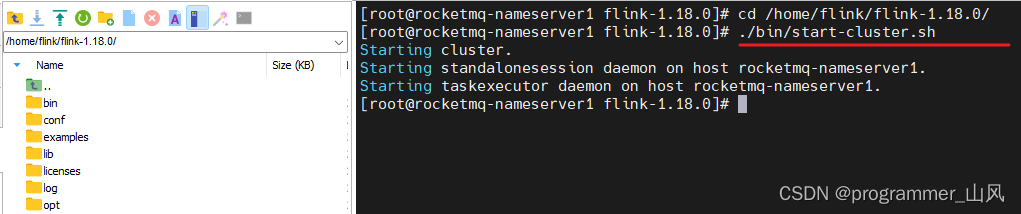
❤️参考:Flink系列:解决/bin/config.sh: line 32: syntax error near unexpected token
六、SeaTunnel 实现 MySQL 跨数据库的表数据同步
1、配置 SeaTunnel 的 Flink 引擎
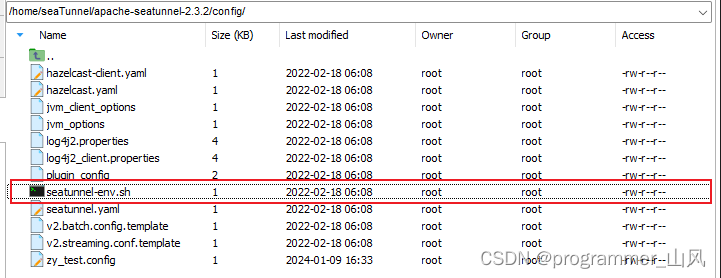
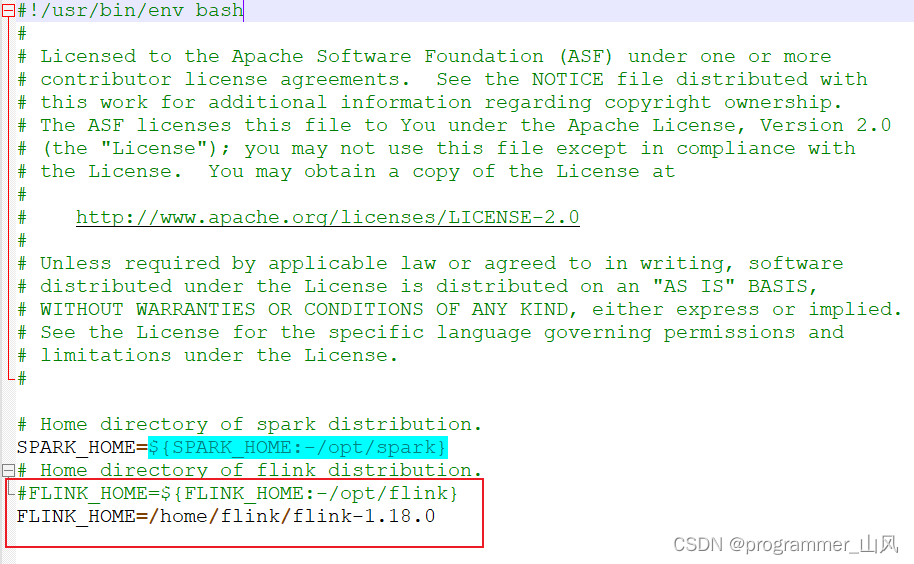
2、下载 MySQL 驱动jar包
(1)地址:https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.30/mysql-connector-java-8.0.30.jar
(2)将 jar 包放到 ${SEATUNNEL_HOME}/lib 下
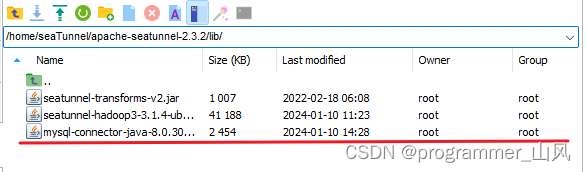
否则后面运行 Seatunnel 报错:

3、已知 MySQL A 库中有表 A1,在 B 库中创建表 B1,结构与 A1 相同

4、在 ${SEATUNNEL_HOME}/conf 下创建配置文件
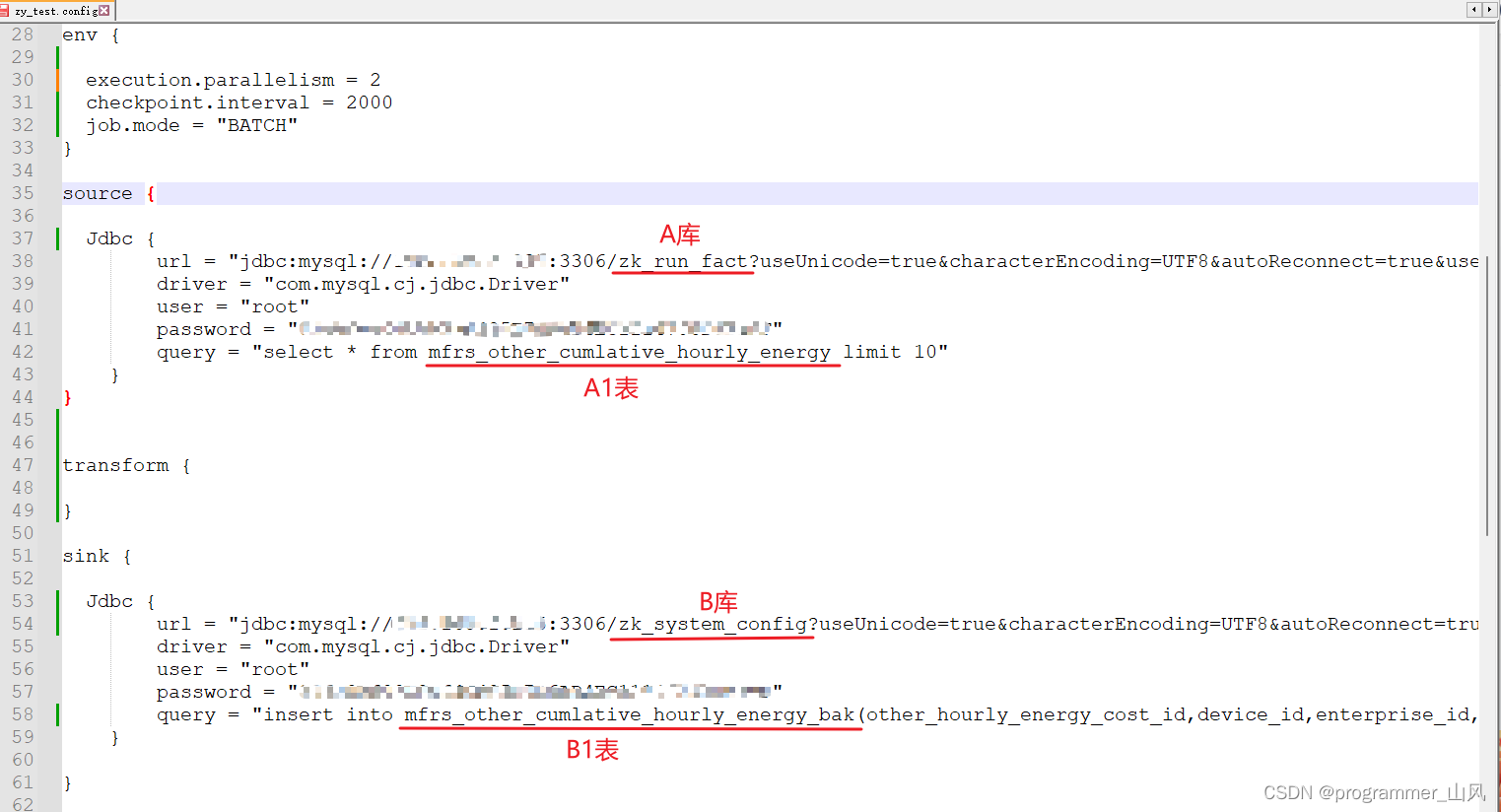
env {execution.parallelism = 2checkpoint.interval = 2000job.mode = "BATCH"
}source {Jdbc {url = "jdbc:mysql://密:3306/zk_run_fact?useUnicode=true&characterEncoding=UTF8&autoReconnect=true&useSSL=false&allowMultiQueries=true&serverTimezone=Asia/Shanghai"driver = "com.mysql.cj.jdbc.Driver"user = "root"password = "密"query = "select * from mfrs_other_cumlative_hourly_energy limit 10"}
}transform {}sink {Jdbc {url = "jdbc:mysql://密:3306/zk_system_config?useUnicode=true&characterEncoding=UTF8&autoReconnect=true&useSSL=false&serverTimezone=Asia/Shanghai&allowMultiQueries=true"driver = "com.mysql.cj.jdbc.Driver"user = "root"password = "密"query = "insert into mfrs_other_cumlative_hourly_energy_bak(other_hourly_energy_cost_id,device_id,enterprise_id,site_id,signal_id,signal_name,device_signal_type_id,energy,time_interval,create_time) values (?,?,?,?,?,?,?,?,?,?)"}
}5、指定配置文件,执行 SeaTunnel
命令: ./bin/seatunnel.sh --config /home/seaTunnel/apache-seatunnel-2.3.2/config/zy_test.config -e local
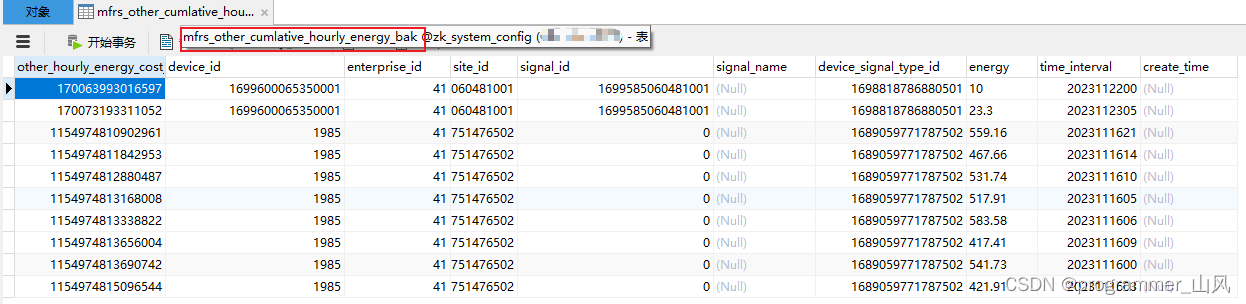
6、查看测试结果
执行前:

执行后:
七、SeaTunnel 实现 MySQL 数据同步到 TDengine
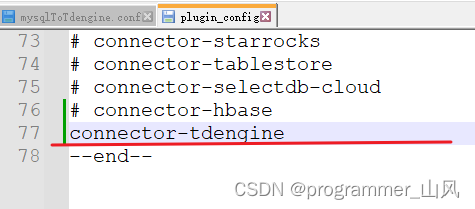
1、编辑 ${SEATUNNEL_HOME}/config/plugin_config文件,添加 TDengine 连接
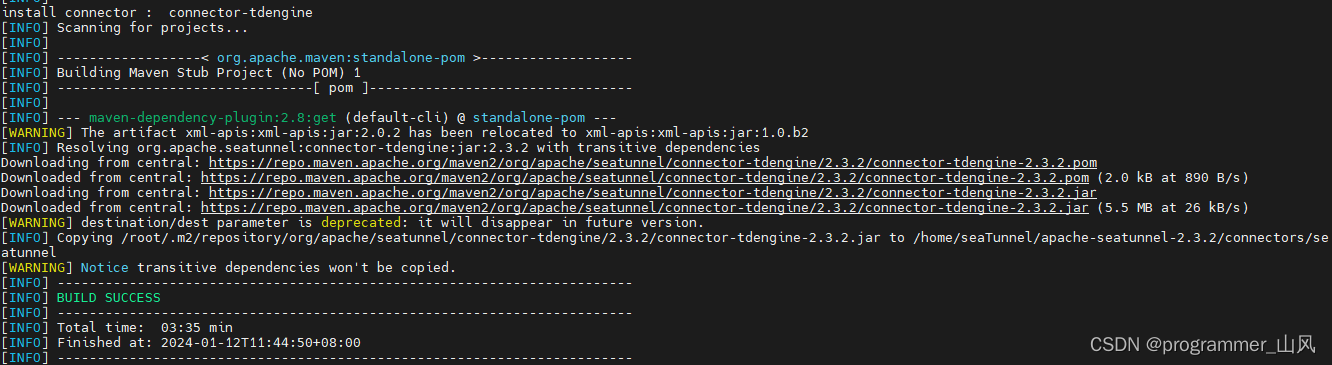
2、再次执行下载插件命令 ./bin/install-plugin.sh
否则运行时报错:
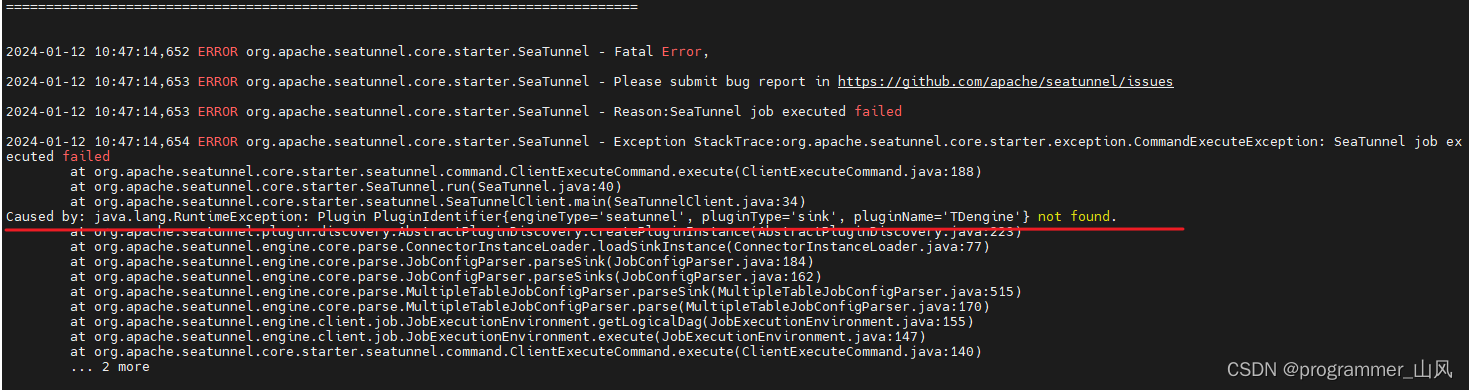
3、下载 TDengine 的连接驱动包
地址:TDengine的连接驱动Jar包
4、将 jar 包放到 ${SEATUNNEL_HOME}/lib 下
5、指定配置文件执行 SeaTunnel
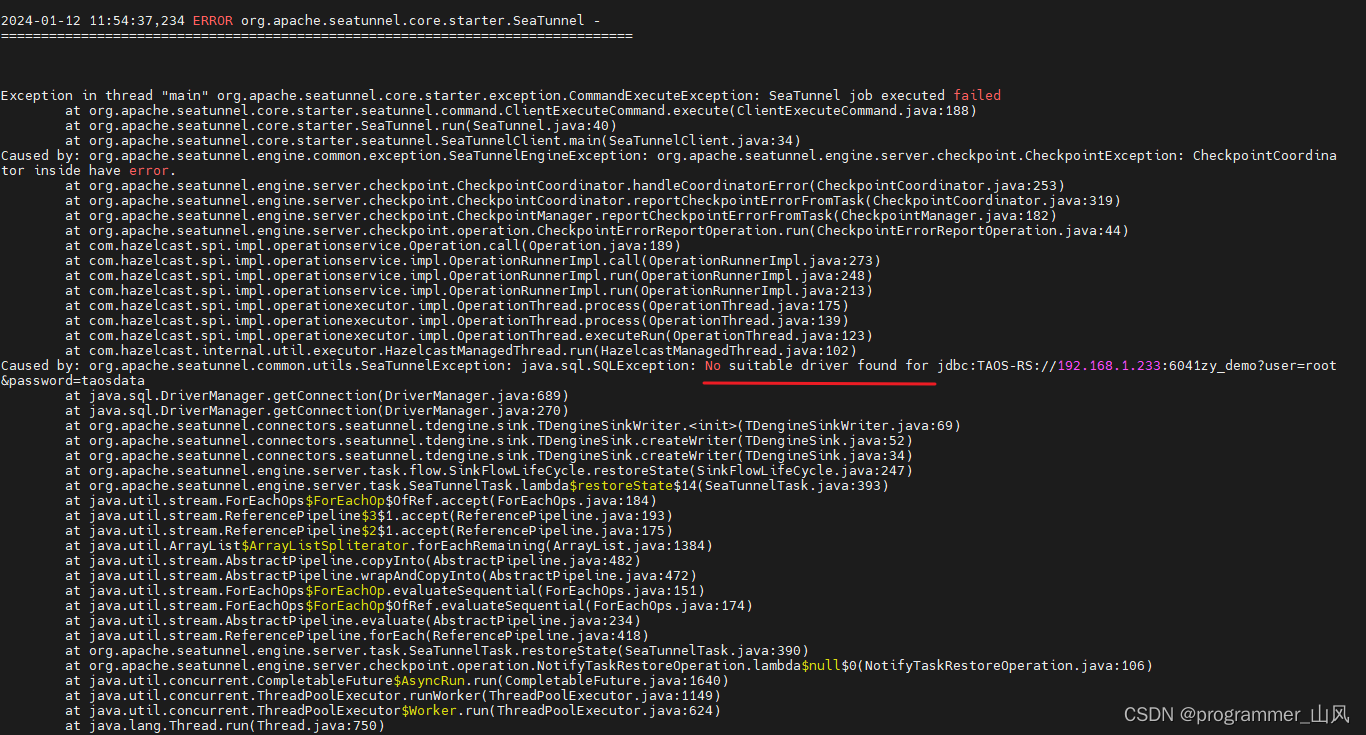
./bin/seatunnel.sh --config /home/seaTunnel/apache-seatunnel-2.3.2/config/ mysqlToTdengine.conf -e local
🚨🚨🚨🚨🚨🚨🚨🚨目前执行时报错,卡在这里,待解决……🚨🚨🚨🚨🚨🚨🚨🚨

这篇关于SeaTunnel 海量数据同步工具的使用(连载中……)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





