本文主要是介绍transbigdata 笔记:官方文档案例1(出租车GPS数据处理),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 读取数据
官方文档中给定的出租车数据在transbigdata/docs/source/gallery/data/TaxiData-Sample.csv at main · ni1o1/transbigdata (github.com)
1.1 出租车数据
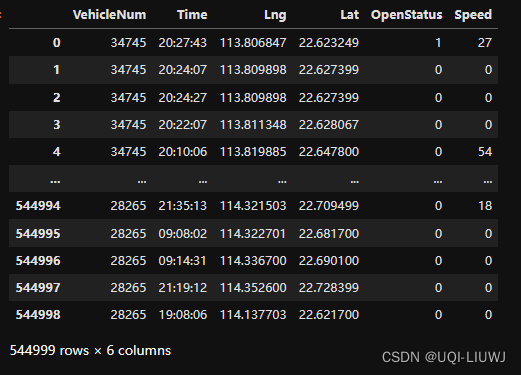
data=pd.read_csv('TaxiData-Sample.csv',names= ['VehicleNum', 'Time', 'Lng', 'Lat', 'OpenStatus', 'Speed'])
data1.2 深圳数据
sz=gpd.read_file('sz.json')
sz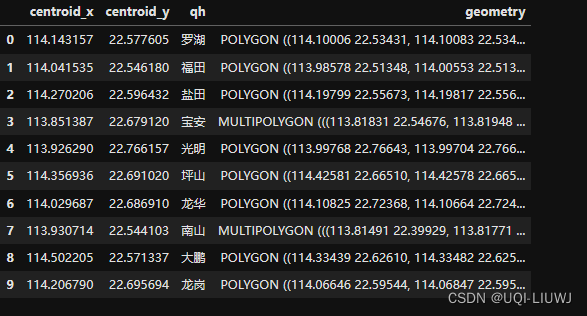
sz.plot(figsize=(15,8)) 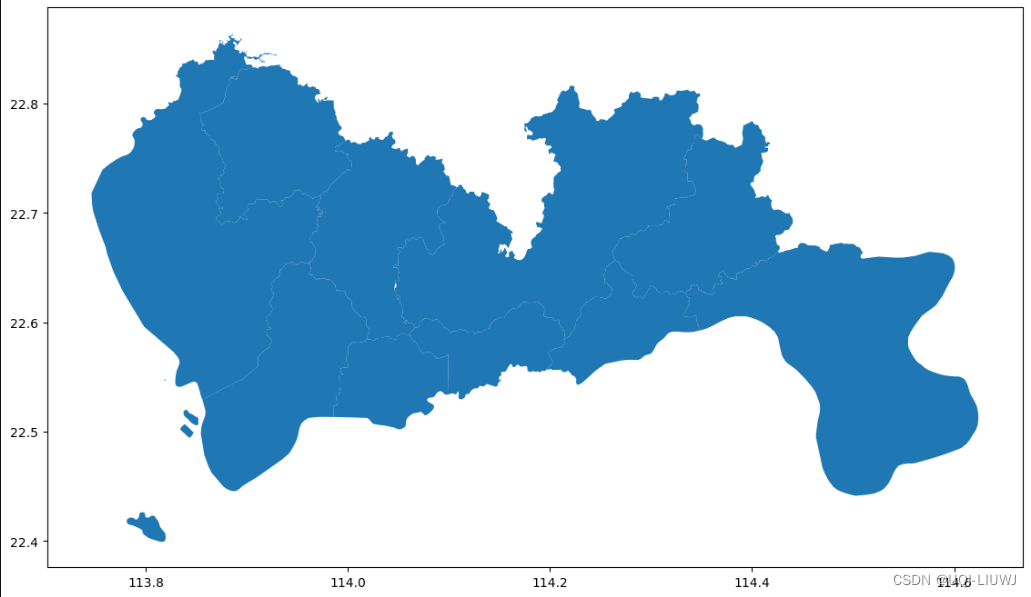
2 清理数据
2.1 清理深圳之外的数据
transbigdata笔记:数据预处理-CSDN博客
data = tbd.clean_outofshape(data, sz, col=['Lng', 'Lat'], accuracy=500)
data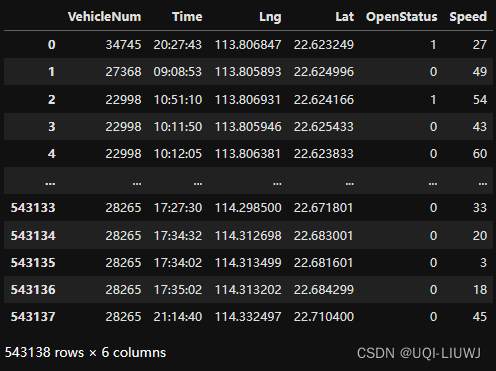
2.2 清理异常记录点
transbigdata笔记:数据预处理-CSDN博客
异常记录点,指的是记录点前后的出租车状态(有乘客/无乘客)和自己的出租车状态不一样
data = tbd.clean_taxi_status(data, col=['VehicleNum', 'Time', 'OpenStatus'])
data
3 数据网格化
3.1 定义网格坐标系
transbigdata笔记:数据栅格化-CSDN博客
官方样例是取了经纬度的四个极值,其实直接把sz作为参数输进去也可以
params=tbd.area_to_params(sz,accuracy=500)
params
'''
{'slon': 113.74627986426263,'slat': 22.39928709355355,'deltalon': 0.0048717524501333395,'deltalat': 0.004496605206422906,'theta': 0,'method': 'rect','gridsize': 500}
'''3.2 将GPS 映射到对应的网格
这里LONCOL和LATCOL列就可以指定一个网格
transbigdata笔记:数据栅格化-CSDN博客
data['LONCOL'], data['LATCOL'] = tbd.GPS_to_grid(data['Lng'], data['Lat'], params)
data
3,2,1 统计每个网格中出现的车辆的数量
dataset=data.groupby(['LONCOL', 'LATCOL'])['VehicleNum'].count().reset_index()
dataset
3.2.2 将网格对应的几何信息写入DataFrame
transbigdata笔记:数据栅格化-CSDN博客
dataset['geometry'] = tbd.grid_to_polygon([dataset['LONCOL'], dataset['LATCOL']], params)
dataset
3.3 绘制网格
datatest=gpd.GeoDataFrame(dataset)
plt.figure(1,(16, 6), dpi=300)
#图的大小和size
ax1 = plt.subplot(111)
#在图形中创建了一个子图。111 表示图形布局是1行1列,且这是第1个子图。
datatest.plot(ax=ax1,column='VehicleNum',legend=True)
'''
在子图ax1上绘制数据。
column='VehicleNum' 指定了要绘制的数据列。
legend=True 表示在图表中包含图例。
'''
plt.xticks([], fontsize=10)
plt.yticks([], fontsize=10)
#设置x轴和y轴的刻度(为空)
plt.title('Counting of Taxi GPS Trajectory Points', fontsize=12);
#设置标题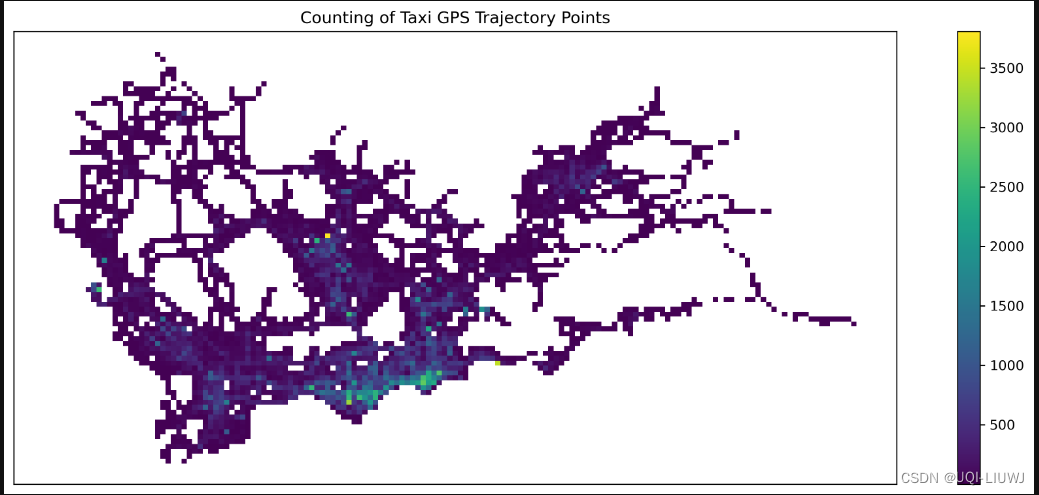
3.3.1 scheme 指定数据分类方案
geopandas 笔记:plot 的scheme-CSDN博客
plt.figure(1,(16, 6), dpi=300)
#图的大小和size
ax1 = plt.subplot(111)
#在图形中创建了一个子图。111 表示图形布局是1行1列,且这是第1个子图。
datatest.plot(ax=ax1,column='VehicleNum',legend=True, scheme='quantiles')
'''
在子图ax1上绘制数据。
column='VehicleNum' 指定了要绘制的数据列。
legend=True 表示在图表中包含图例。
scheme指定数据分类方案
'''
plt.xticks([], fontsize=10)
plt.yticks([], fontsize=10)
#设置x轴和y轴的刻度(为空)
plt.title('Counting of Taxi GPS Trajectory Points', fontsize=12);
#设置标题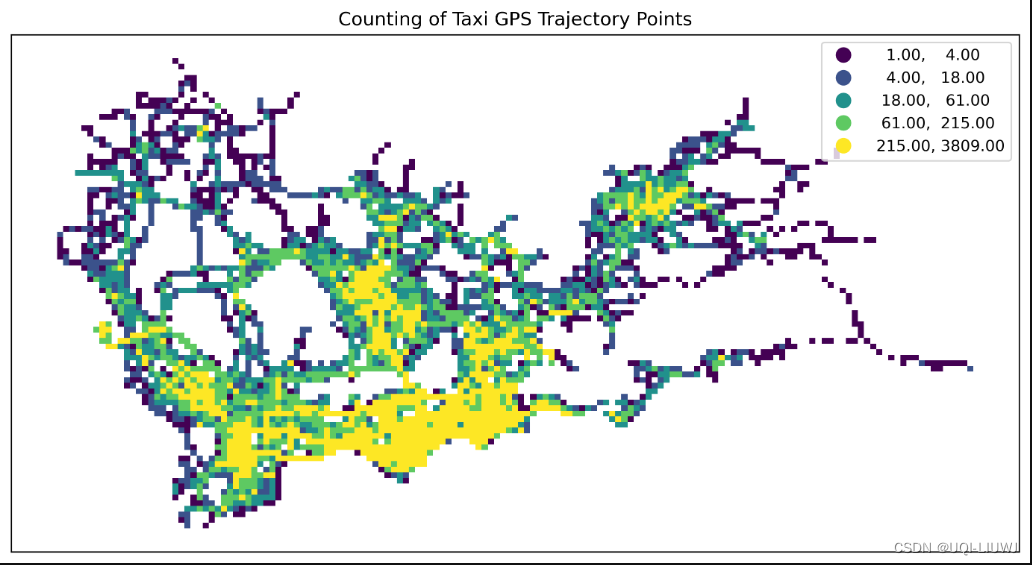
4 提取&聚合出租车行程
4.1 提取OD
oddata = tbd.taxigps_to_od(data,col = ['VehicleNum', 'Time', 'Lng', 'Lat', 'OpenStatus'])
oddata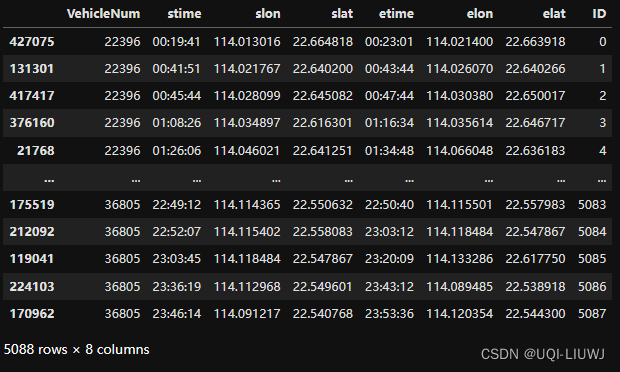
4.2 聚合OD ,获得轨迹的geometry
od_gdf = tbd.odagg_grid(oddata, params)
od_gdf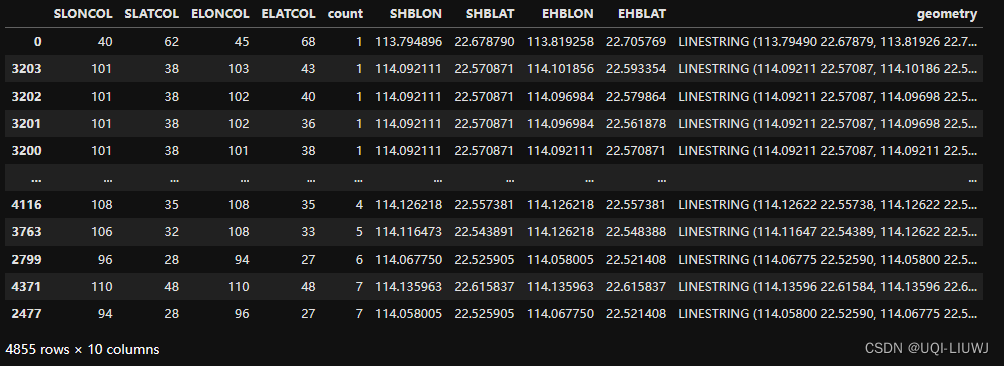
4.3 绘制OD trip
fig = plt.figure(1, (16, 6), dpi=150)
# 确定图形高为6,宽为8;图形清晰度
ax1 = plt.subplot(111)od_gdf.plot(ax=ax1, column='count', legend=True)
plt.xticks([], fontsize=10)
plt.yticks([], fontsize=10)
plt.title('OD Trips', fontsize=12);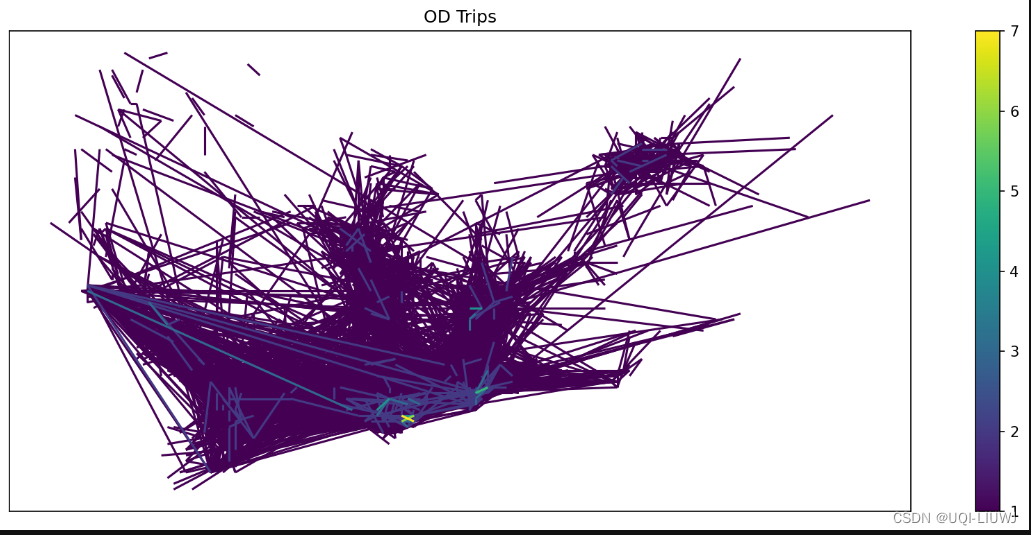
5 提取出租车轨迹
5.0 提取载客行程和空闲行程
data_deliver, data_idle = tbd.taxigps_traj_point(data,oddata,col=['VehicleNum','Time','Lng','Lat','OpenStatus'])返回载客行程和空闲行程的轨迹点
data_idle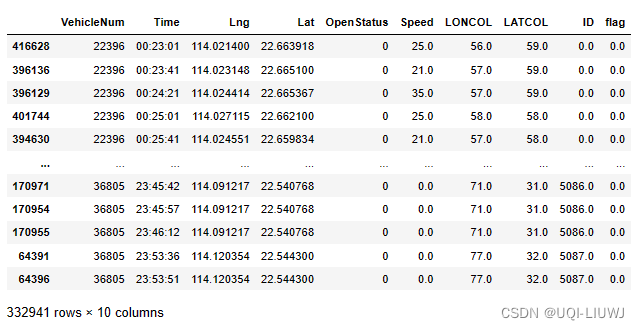
data_deliver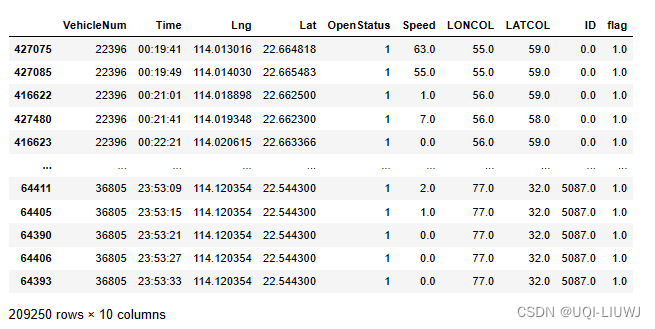
5.1 一个一个记录汇总成一条一条线
注:官方文档里写的points_to_traj已经无了,现在是traj_to_linestring
traj_deliver = tbd.traj_to_linestring(data_deliver)
traj_deliver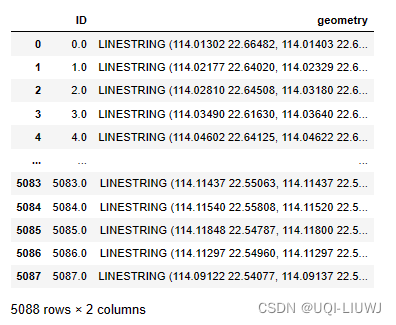
5.2 用kepler.gl可视化轨迹
tbd.visualization_trip(data_deliver)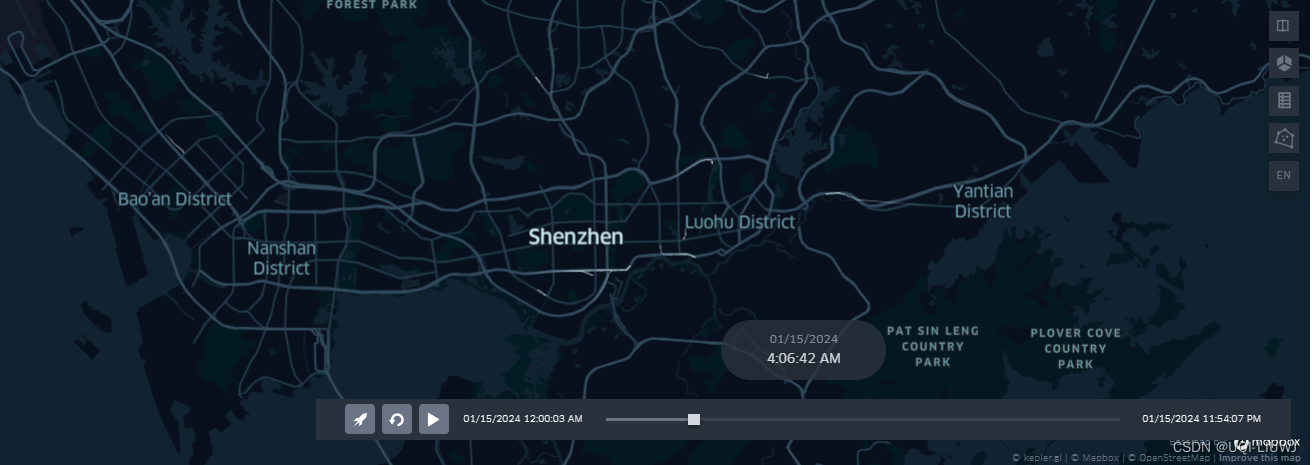
这篇关于transbigdata 笔记:官方文档案例1(出租车GPS数据处理)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







