本文主要是介绍[学习笔记]刘知远团队大模型技术与交叉应用L1-NLPBig Model Basics,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本节主要介绍NLP和大模型的基础知识。提及了词表示如何从one-hot发展到Word Embedding。语言模型如何从N-gram发展成预训练语言模型PLMs。然后介绍了大模型在NLP任务上的表现,以及它遵循的基本范式。最后介绍了本课程需要用到的编程环境和GPU服务器。
一篇NLP方向的综述推荐
Advances in Natural Language Processing - Julia Hirschberg,Columbia University(见绑定资源)
基本任务和应用
包括词性标注(Part of speech tagging),命名实体识别,共指消解,依赖关系。对于中文,由于词与词没有空格,所以还有一个中文的自动分词的任务。

- 搜索引擎和广告:如何衡量用户的query与所有document的语义相似度-NLP要解决的问题;利用互联网之间的链接信息判断网站或网页的质量-数据挖掘和信息检索关心的问题
- Knowledge Graph:知识图谱里有非常多NLP问题,如给定一个用户的查询,如何去匹配或寻找最相关的实体,以及相关知识。如何从大规模文本中挖掘,构建大的知识图谱,如何获取三元组结构化知识,本身也需要NLP技术。
- Knowledge Graph Application:Question Answering
- Machine Reading:从文本中抽取结构知识,扩展和更新知识图谱
- Personal Assistant
- Machine Translation
- Sentiment Analysis and Opinion Mining
- Computational Social Science
词表示
词表示的目标:
1.计算词相似性:相似
2.推断词之间的关系

常用的词表示方式:one-hot表示

这种表示方法的缺点是:任意两个词都是相互正交的。不利于考虑相似性。
基于共现词次数的表示
NLP提出了一种contextual的distribution。

这种表示方法的缺点是:词表越大,存储要求越高;低频词很稀疏,导致不够鲁棒。
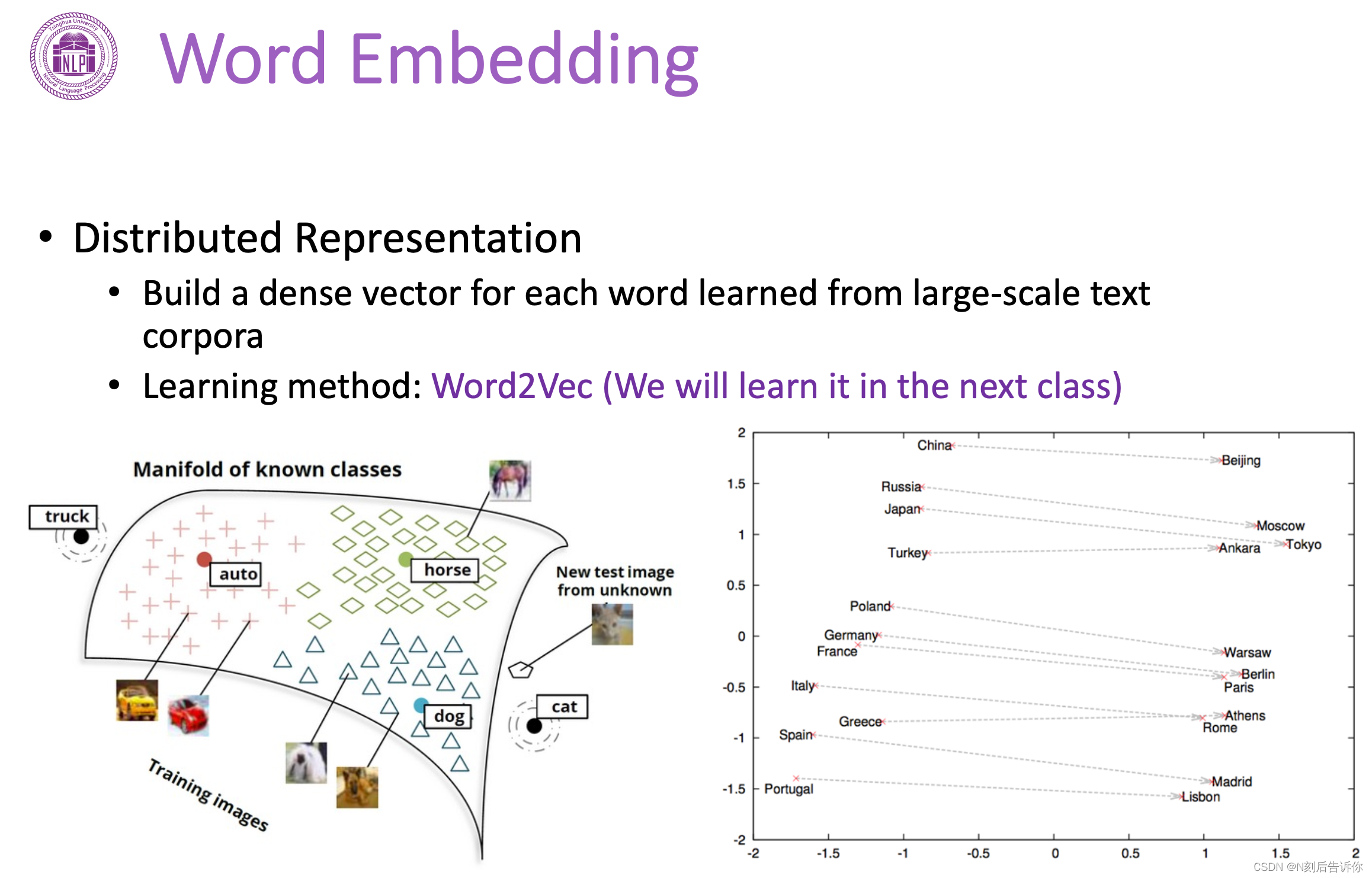
Word Embedding
构建一个低维稠密向量空间,学习每个词的低维稠密向量表示。
语言模型(Language Modeling)
语言模型的任务是预测下一个词。
它的工作包括两个:1.一个序列的词成为一句话的概率;2.根据已有的词序列,预测下一个词出现的概率。

基本假设
未来的词只会收到之前词的影响。这样联合概率就可以拆解成如下的条件概率。

N-gram Model
先介绍一种,在深度学习出现前,经典且重要的语言模型构建方式:N-gram。
以4-gram为例,讨论never to late to后面出现wj的概率,可以用语料库中,too late to wj出现的次数除以too late to出现的次数。
需要统计所有出现的n-gram序列的频度。

N-gram的问题是:
1.N一般只会取2或者3:因为取过大的N,序列在语料库中出现的次数会变少,会导致统计结果稀疏。同时过大的N会导致存储的量增大。
2.不能反映词之间的相似性:N-gram是基于符号去做统计,所以对它而言,所有词都是独立的。

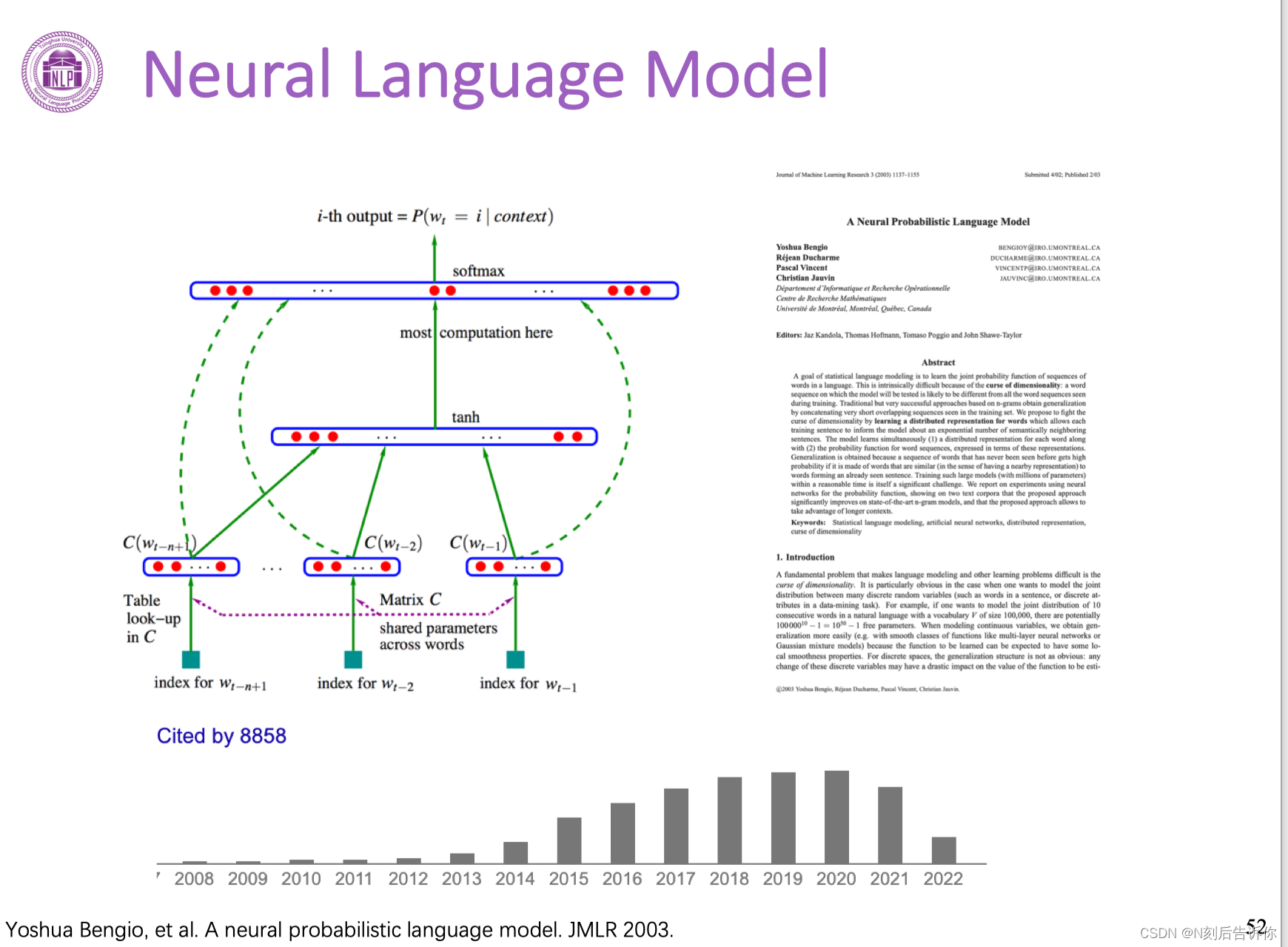
神经语言模型
神经语言模型是基于神经网络来学习词的分布式表示的语言模型。

假设当前要预测第t个词为词i的概率,考虑前面n个词:
1.将前面n个词表示成低维向量(从Word Embedding学到的低维稠密向量空间中找到)。
2.拼接上面的低维向量,形成更高的上下文向量。
3.经过非线性转换。
4.利用这个向量来预测下一个词是什么。
所有词的向量,以及整个预测的过程,都是基于神经网络的可调节可学习参数来完成。因此可以利用大规模数据来学习这些向量。
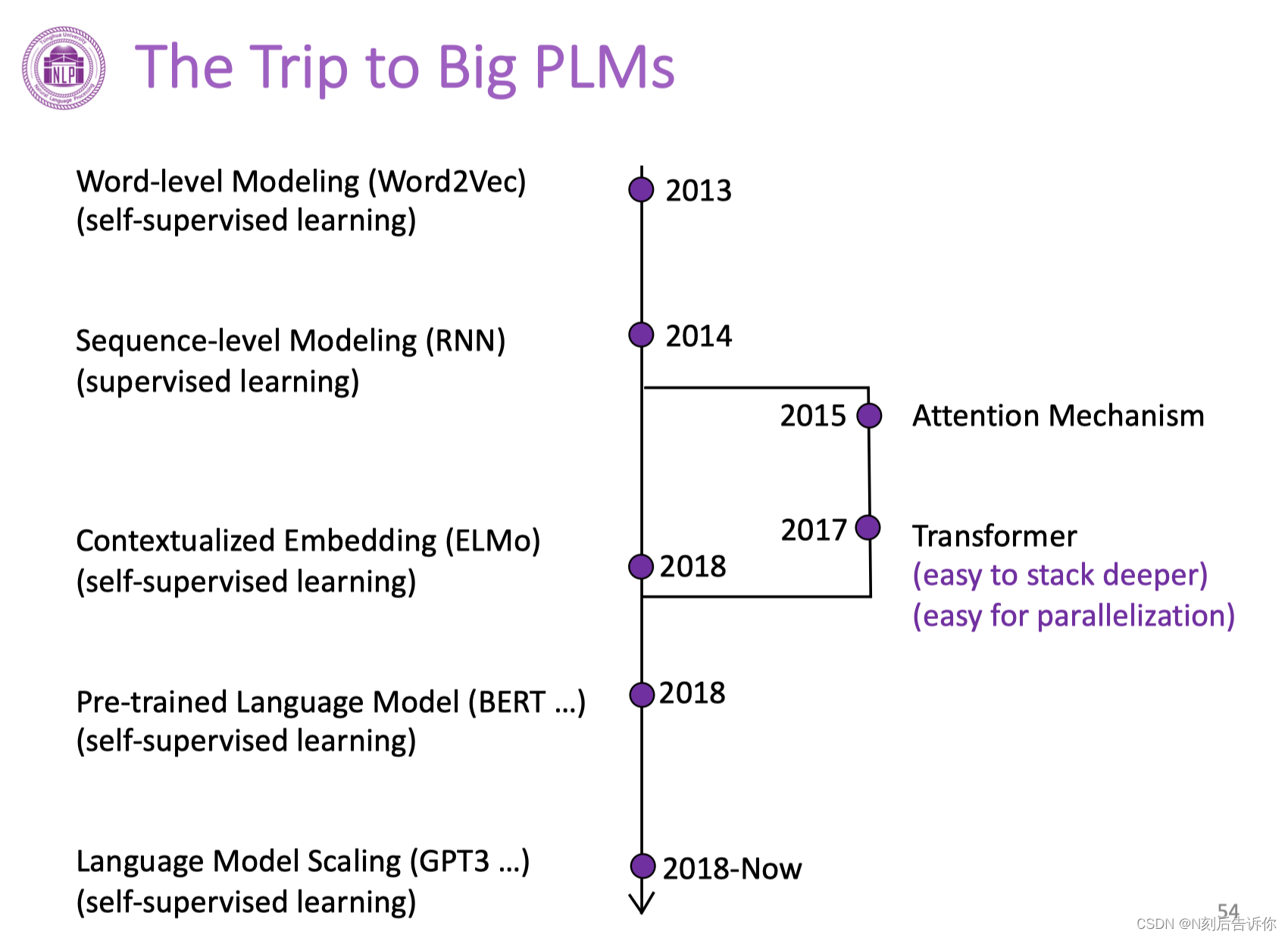
大模型的发展历程
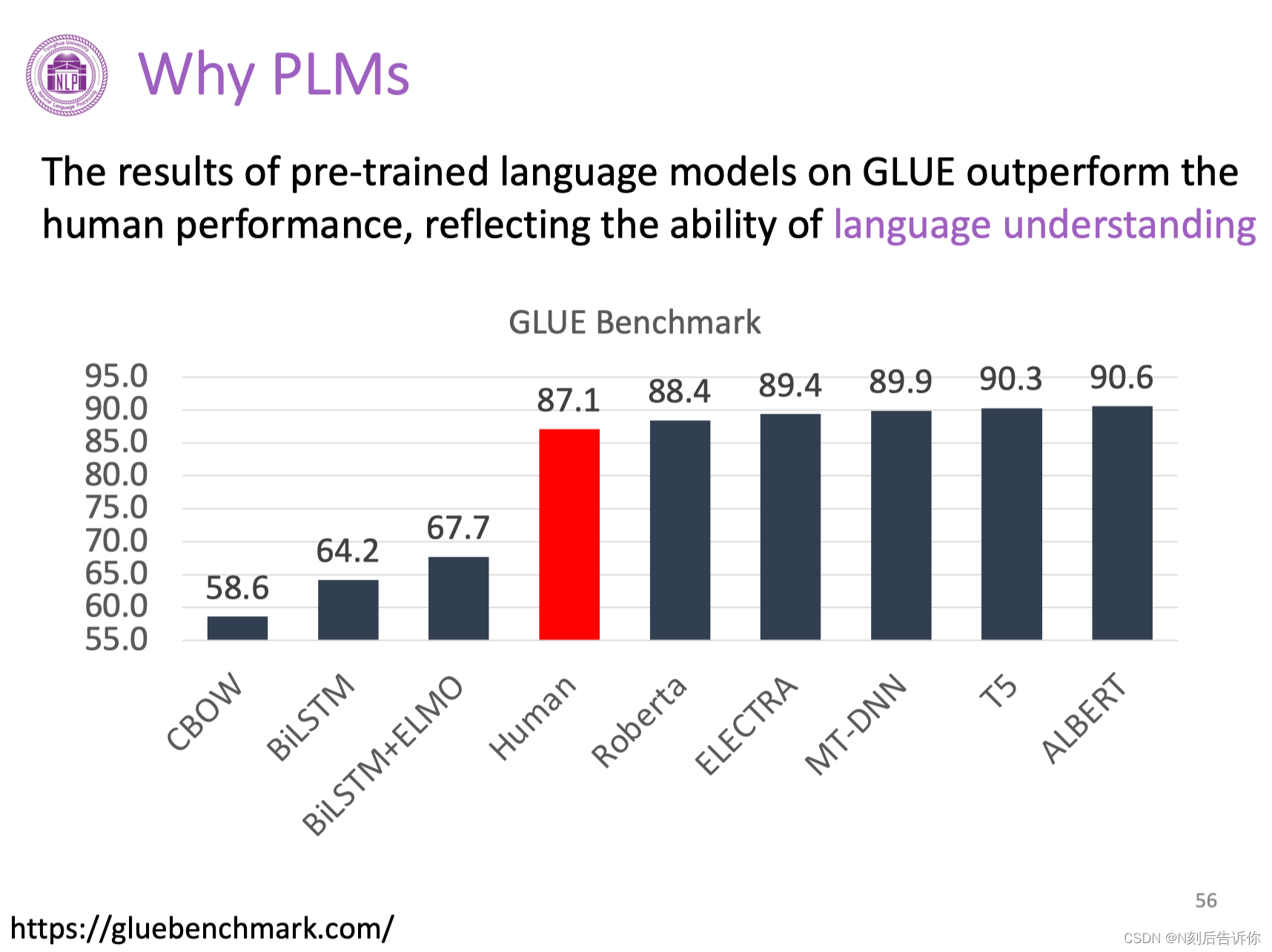
为什么大模型非常重要
在语言理解,语言生成(如对话系统任务)上,预训练语言模型(PLMs)已经比人类表现要好了。
18年开始,PLMs的三个趋势是:更多的参数;更大规模的语料数据;更大规模的分布式计算。这些方式能显著提升模型性能。
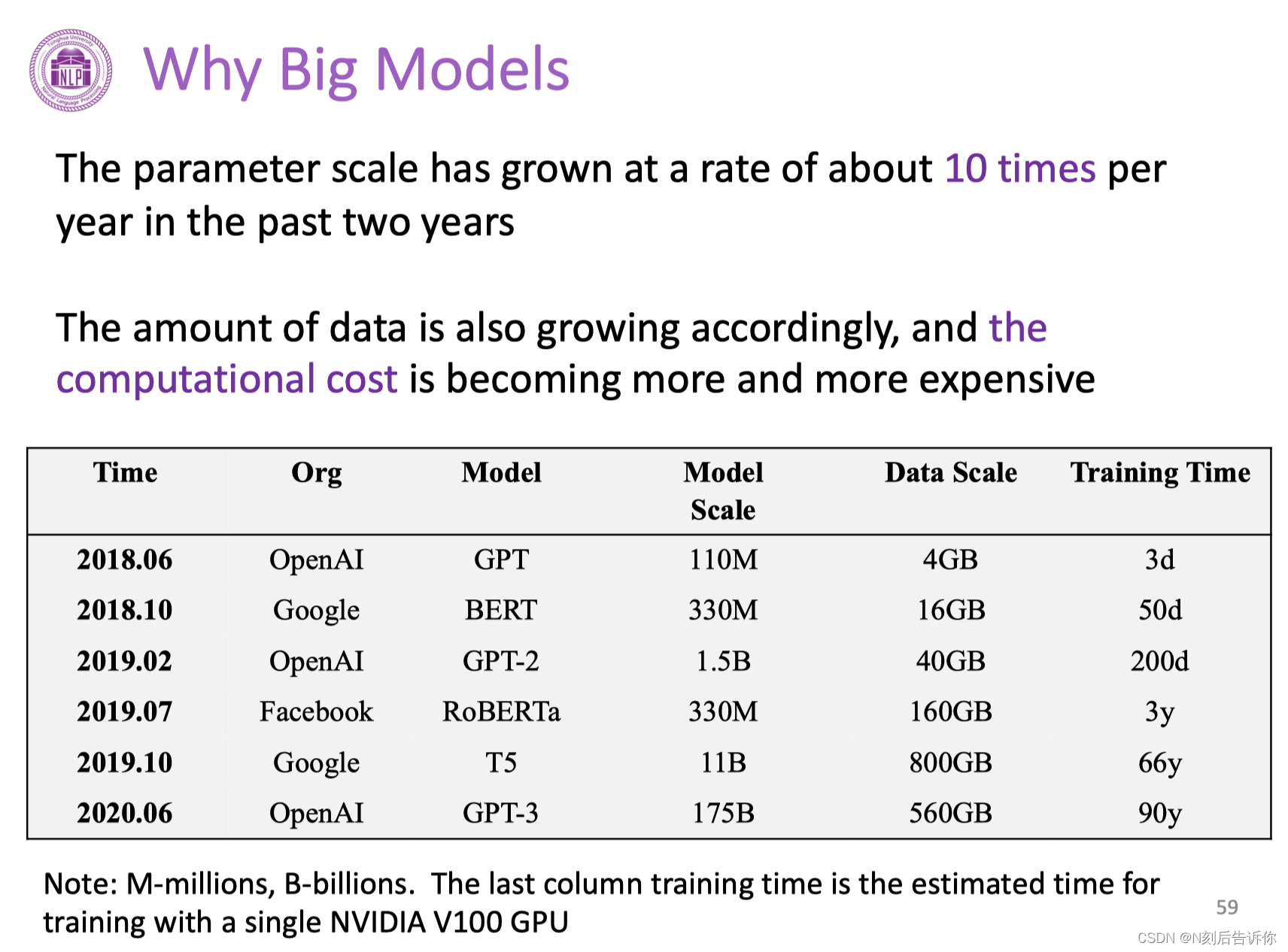
GPT-3中,我们可以看到PLMs所涌现出来的人类知识。这说明文本知识会被捕捉到PLMs中,并且在大量参数中存储下来。所以渐渐地,大家会将PLMs作为解决NLP问题的基础工具。

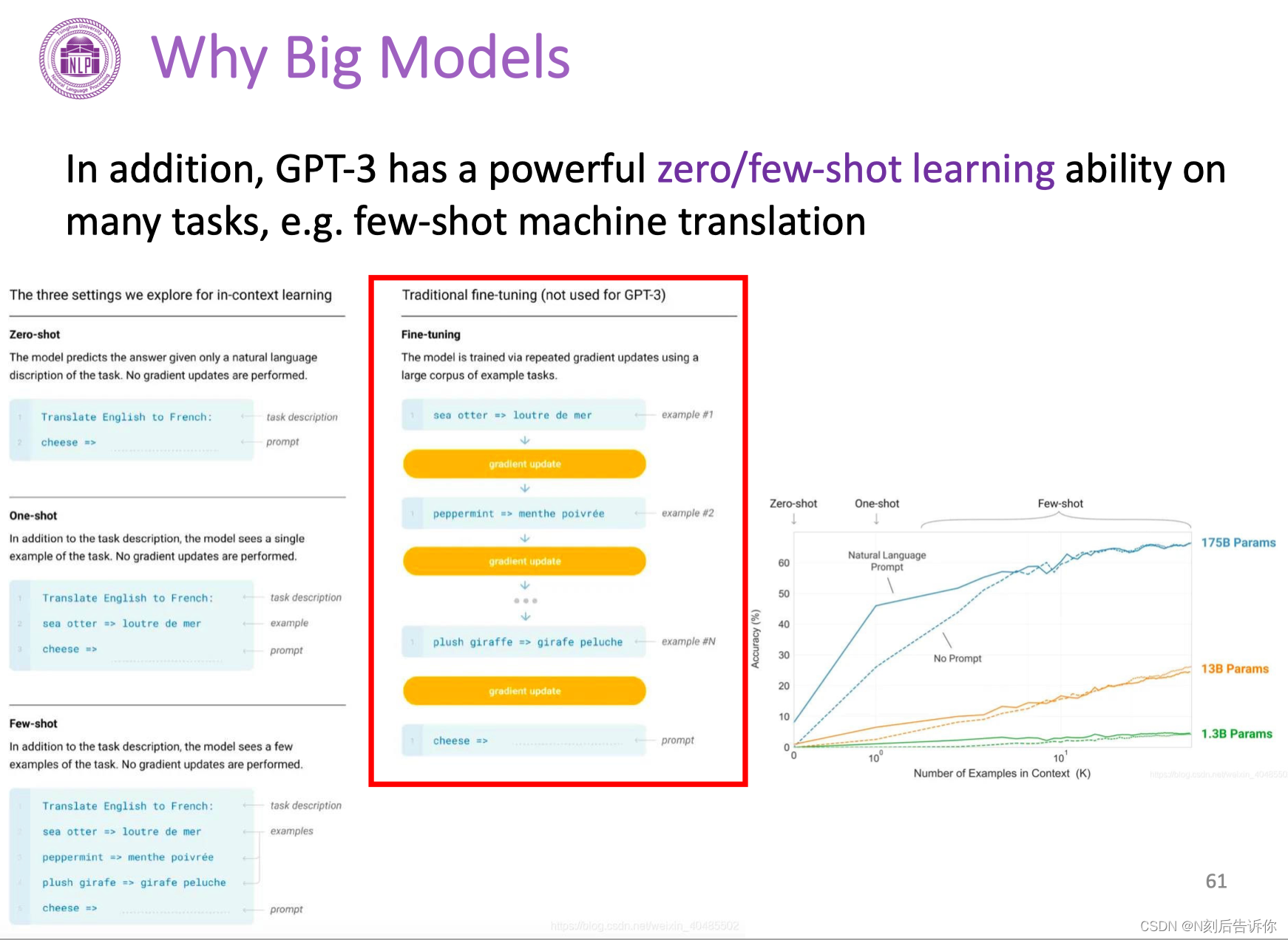
另一方面,GPT-3有很强的零/小样本学习的能力。
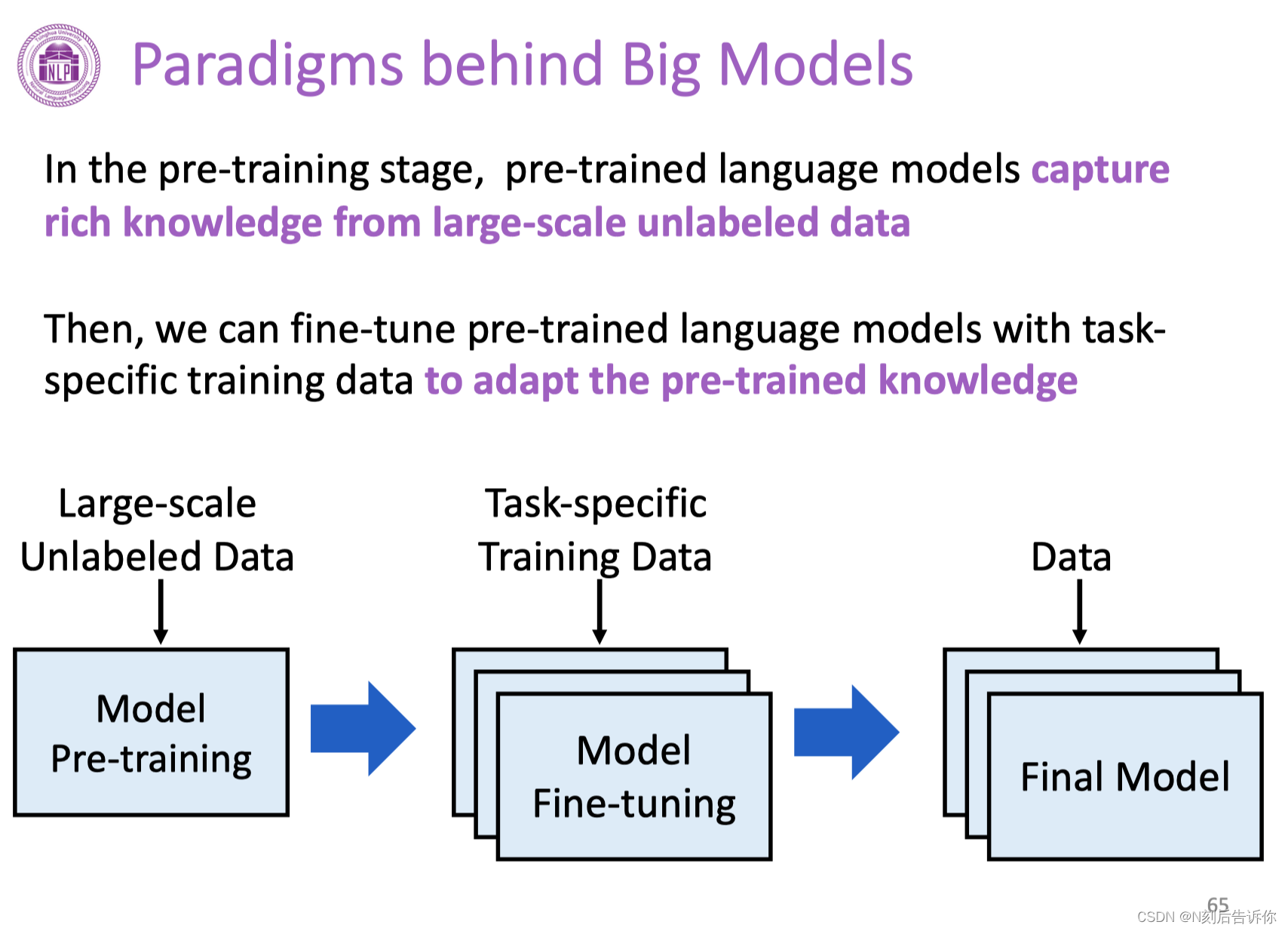
大模型背后的范式
预训练阶段,PLMs会从大量无标注数据中进行学习,通过一些自监督任务,去做预训练,从中得到丰富的知识。
在具体应用时候,会引入一些任务相关数据,然后对模型进行微调。
最终保留任务相关的知识。最终得到一个解决具体任务的模型。
编程环境和GPU服务器介绍
相关知识,如Linux命令,Git命令等,需要自己了解。
这篇关于[学习笔记]刘知远团队大模型技术与交叉应用L1-NLPBig Model Basics的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





