本文主要是介绍分享从零开始学习网络设备配置--任务4.4 使用动态路由OSPFv3实现网络连通,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
任务描述
由于RIPng不适用于复杂的网络,考虑到公司的未来发展,需要不断扩大网络规模。某公司在企业网络升级时,选择 OSPFv3路由协议实现网络连通,降低网络拓扑变化引发的人工维护工作量并加快网络收敛的速度。 公司内部的所有设备均运行IPv6的动态OSPFv3路由协议,实现技术部、销售部和财务部的网络互联互通。
任务要求
(1)要求所有路由器均运行OSPFv3动态路由协议,网络拓扑图如图
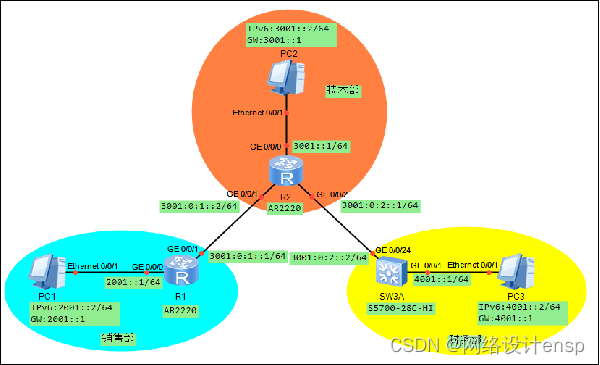
(2)路由器和交换机的端口IPv6地址设置如表

(3)计算机的IPv6地址设置如表
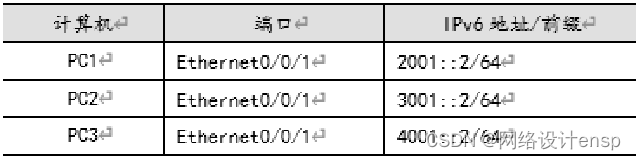
(4)在路由器和交换机上均运行动态路由OSPFv3路由协议,实现全网的互连互通。
知识准备
1.OSPFv3概述
OSPFv3是OSPF(Open Shortest Path First,开放式最短路径优先)版本3的简称,主要提供对IPv6的支持,遵循的标准为RFC 2740(OSPF for IPv6)。 OSPFv3和OSPFv2在很多方面是相同的:
(1)Router ID,Area ID仍然是32位的。
(2)相同类型的报文:Hello报文,DD(Database Description,数据库描述)报文,LSR(Link State Request,链路状态请求)报文,LSU(Link State Update,链路状态更新)报文和LSAck(Link State Acknowledgment,链路状态确认)报文。
(3)相同的邻居发现机制和邻接形成机制。
(4)相同的LSA扩散机制和老化机制。
OSPFv3和OSPFv2的不同点主要有:
(1)OSPFv3是基于链路(Link)运行,OSPFv2是基于网段(Network)运行。
(2)OSPFv3在同一条链路上可以运行多个实例。
(3)OSPFv3是通过Router ID来标识邻接的邻居。OSPFv2则是通过IP地址来标识邻接的邻居。
2.OSPFv3的协议报文
和OSPFv2一样,OSPFv3也有五种报文类型,分别是Hello报文、DD报文、LSR报文、LSU报文和LSAck报文。 这五种报文有相同的报文头部,但是它和OSPFv2的报文头部有一些区别,其长度只有16字节,且没有认证字段。另外就是多了一个Instance ID字段,用来支持在同一条链路上运行多个实例。 OSPFv3的报文头部结构如图
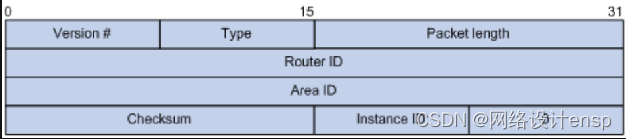
主要字段的解释如下:
(1)Version #:OSPF的版本号。对于OSPFv3来说,其值为3。
(2)Type:OSPF报文的类型。数值从1到5,分别对应Hello报文、DD报文、LSR报文、LSU报文和LSAck报文。
(3)Packet Length:OSPF报文的总长度,包括报文头部在内,单位为字节。
(4)Instance ID:同一条链路上的实例标识。
(5)0:保留位,必须为0。
3.OSPFv3的LSA类型
LSA(Link State Advertisement,链路状态通告)是OSPFv3协议计算和维护路由信息的主要来源。在RFC2740中定义了七类LSA,具体描述如表

4.OSPFv3的定时器
OSPFv3的定时器包括:OSPFv3的报文定时器、LSA的延迟时间和SPF定时器。
(1)OSPFv3的报文定时器。 Hello报文周期性地被发送至邻居路由器,用于发现与维持邻居关系、选举DR与BDR。注意,网络邻居间的Hello时间间隔必须一致,并且Hello时钟的值与路由收敛速度、网络负荷大小成反比。
(2)LSA的延迟时间。 由于LSA在本路由器的LSDB(Link State Database,链路状态数据库)中会随时间老化(每秒加1),但在网络的传输过程中却不会随时间老化,所以有必要在发送之前就将LSA的老化时间增加上传送延迟时间。对于低速网络,该项配置尤为重要。
(3)SPF定时器。 当OSPFv3的LSDB发生改变时,需要重新计算最短路径,如果每次改变都立即计算最短路径,将占用大量资源,并会影响路由器的效率,通过调节SPF(Shortest Path First,最短路径优先)的计算延迟时间和间隔时间,可以避免在网络频繁变化时过多的占用资源。
5.关键技术命令解析
(1)在系统视图使能OSPFv3进程,并进入OSPFv3视图。
![]()
process-id表示OSPFv3进程号,取值范围为1~65 535的整数,默认值为1。例如:
![]()
(2)在指定OSPFv3进程视图配置路由器的router id
![]()
route id长度为32位,用于OSPFv3路由协议选举DR和BDR。例如:
![]()
(3)在端口视图配置OSPFv3区域。
![]()
area-id表示区域号,取值范围为0~4294967295,0表示骨干区域。例如:
![]()
任务实施
1.参照图搭建网络拓扑,连线全部使用直通线,开启所有设备电源。
2.启用路由器和端口的IPv6功能,并配置路由器端口的IPv6地址。具体的配置方法请参照本项目中任务4.3的R1和R2的基本配置。
3.启用交换机和VLANIF端口的IPv6功能,并配置VLANIF端口的IPv6地址。具体的配置方法请参照本项目中任务4.3的SW3A的基本配置。
4.配置OSPFv3路由。
(1)在路由器R1和R1端口上开启OSPFv3功能。
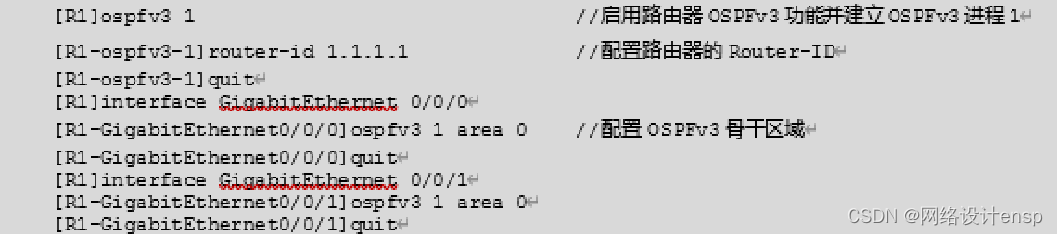
(2)在路由器R2和R2端口上开启OSPFv3功能。
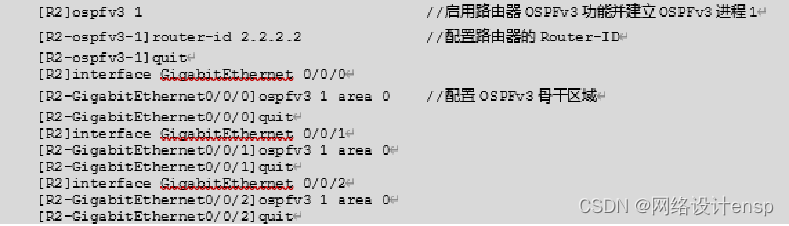
(3)在交换机SW3A和SW3A的VLANIF端口上OSPFv3功能。

任务验收
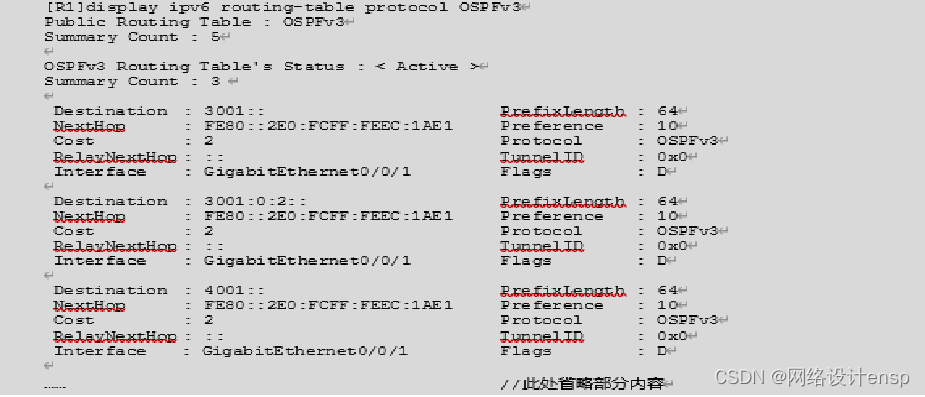
1.查看IPv6的路由表。 在路由器R1上,使用display ipv6 routing-table protocol OSPFv3命令查看R1的路由表。
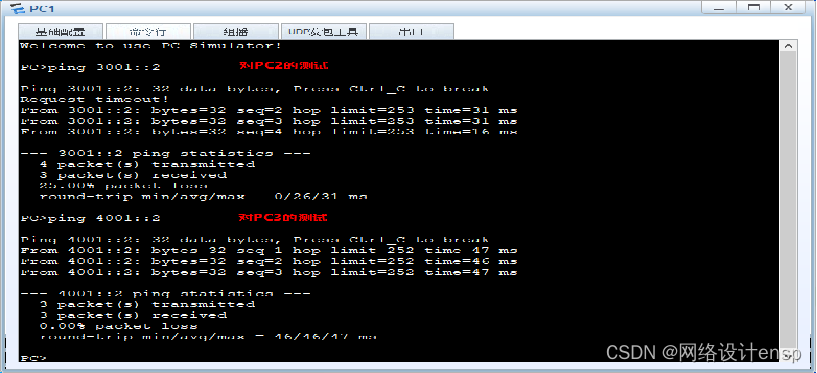
2.测试全网连通性。 在PC1、PC2和PC3上配置IPv6地址、前缀长度和IPv6网关,请参照任务4.3中的设置。 单击PC1的“命令行”选项卡,在“PC>”处输入要测试的内容,这里去ping PC2和PC3的IPv6地址,按“Enter”进行测试,测试结果显示全网通,RIPng路由配置成功,如图
任务小结
(1)OSPFv3延续了大部分OSPF的工作原理。
(2)OSPFv3配置比OSPF还简单,只需要进入每个使用到的端口(包括逻辑端口) 使能OSPFv3功能即可,无需宣告网络。
这篇关于分享从零开始学习网络设备配置--任务4.4 使用动态路由OSPFv3实现网络连通的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






