本文主要是介绍Redis学习笔记(下):持久化RDB、AOF+主从复制(薪火相传,反客为主,一主多从,哨兵模式)+Redis集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
十一、持久化RDB和AOF
持久化:将数据存入硬盘
11.1 RDB(Redis Database)
RDB:在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
备份是如何执行的:

Fork:

在/usr/local/bin目录下输入:vim /etc/redis.conf。找到SNAPSHOTTING。
dbfilename dump.rdp的意思是进行rdb后文件的名字为dump.rdg。
stop-writes-on-bgsave-error如果为yes代表:当Redis无法写入磁盘的话,直接关掉Redis的写操作,推荐yes。
rdbcompression压缩文件。
rdbchecksum如果为yes代表:检查完整性,推荐yes。
sava 秒钟 写操作次数。默认60分钟内有1个key发生变化,即进行持久化操作。5分钟内有10个key发生变化进行持久化操作。1分钟如果1000key发生变化就进行持久化操作。

操作步骤:在redis.conf配置文件中位置的下方写入save 20 3,wq!,然后ps -ef | grep redis杀掉进程,然后重新启动redis-server /etc/redis.conf,输入ll,查看dump.rdb文件的大小,客户端工具连上redis。如果有快照失败的问题可以试试:sysctl vm.overcommit_memory=1。
bgsave:Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求
优势:

劣势:

RDB的备份
操作步骤:先连接上redis,然后flushdb,然后exit退出,在bin目录下输入ll,查看此时dump.rdb文件的大小148。sudo vim /etc/redis.conf进入到redis.conf的配置文件中,添加save 20 3。然后添加5条数据比如set a a到set f f。
![]()
然后cp dump.rdb d.rdb将dump.rdb复制一份成d.rdb。然后用命令sudo rm -f dump.rdb删除掉该文件,模拟此时数据丢失的场景。输入sudo mv d.rdb dump.rdb将d.rdb改名为dump.rdb。

11.2 AOF(Append Only File)

打开AOF:vim /etc/redis.conf,输入:/appendonly可以搜索到关键字,appendfilename写的是文件最终生成的名字:
![]()
用ps -ef | grep redis查找进程,用kill -9 进程号杀死进程,然后重新redis-server /etc/redis.conf启动,再在xshell中开启一个新的会话,cd /usr/local/bin,ll查看,会看到appendonlydir文件夹,此时redis-cli进入redis中查看发现并没有数据,说明RDB和AOF同时开启时默认读取AOF。
恢复操作:cp appendonly.aof appendonly.aof.bak先备份一份。在redis中shutdown,然后exit。然后rm -rf appendonly.aof。然后mv appendonly.aof.bak appendonly.aof。然后重启redis,再连接。
异常恢复:首先cd appendonlydir,然后vi appendonly.aof.1.incr.aof,在最后加上Hello,然后进入redis,shutdown,在bin目录下启动redis,然后进入redis,此时文件已经启动不了。在bin目录下有一个redis-check-aop文件,redis-check-aop --fix 修复文件的名称,会提示出错的地方,即可进行修复。此时再启动就没有任何问题。


AOF同步频率设置:

Rewrite压缩:

将各种命令用一条表现,只关注最后的操作,原理如下:

触发条件:

重写流程:

优势:

劣势:

综合:

如果不怕数据丢失,可以用RDB。AOF不建议单独使用,会出现BUG。
十二、主从复制
主从复制:主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主。
特点:1.读写分离(Master以写为主,Slave以读为主,一主多从)。2.容灾快速恢复(如果一台从服务器挂了,能够快速切换到其它从服务器进行读取)。
如果只有一台主服务器,但这台服务器挂掉了怎么办呢?配置集群:就是每一个部分都有1台主机,多个从服务器器,多个部分整体构成集群。
2.1 搭建一主多从
先cd /myredis,然后拷贝配置文件sudo cp /etc/redis.conf /myredis/redis.conf,
sudo vim redis.conf,/appendonly,然后将yes改为no。输入sudo vi redis6379.conf
include /myredis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
sudo cp redis6379.conf redis6380.conf,sudo vi redis6380.conf,将6379的字样全部改为6380。sudo cp redis6379.conf redis6381.conf,sudo vi redis6380.conf,将6379的字样全部改为6381。
启动3个redis会话,然后启动redis服务器【注意一定要确保启动时是root角色】:redis-server redis6379.conf,redis-server redis6380.conf,redis-server redis6381.conf。输入ps -ef | grep redis查看是否均启动:

首先在Xshell中打开3个会话,均输入:cd /myredis进入文件夹,,分别输入:redis-cli -p 6379,redis-cli -p 6380,redis-cli -p 6381,进入redis。
在6379输入info replication查看有0台从服务器,在6380和6381中输入slaveof 127.0.0.1 6379。在6379中输入keys *返回的结果是空,再输入set a1 v1。此时在6380和6381中输入keys *会显示a1【前提所有redis服务器都是在root角色的控制下】。
2.2 复制原理和一主二仆
复制原理:当从服务器连接上主服务器后,从服务器向主服务器发送进行数据同步的消息。主服务器接收到从服务器发送过来的同步消息,把主服务器数据进行持久化
首先输入在6380输入shutdown模拟挂掉,在6379发送数据set a2 k2,如果把6380启动redis-cli -p 6380,再输入saveof 127.0.0.1 6379变成从服务器,然后keys *仍旧能接收到新增的keys。
假如把主服务器挂掉,在6379中输入shutdown,从服务器仍旧是从服务器,主服务器重启仍旧是主服务器,从服务器仍旧认识主服务器。
2.3 薪火相传和反客为主
薪火相传:在从服务器下设置从服务器。在6380里输入slaveof 127.0.0.1 6381。

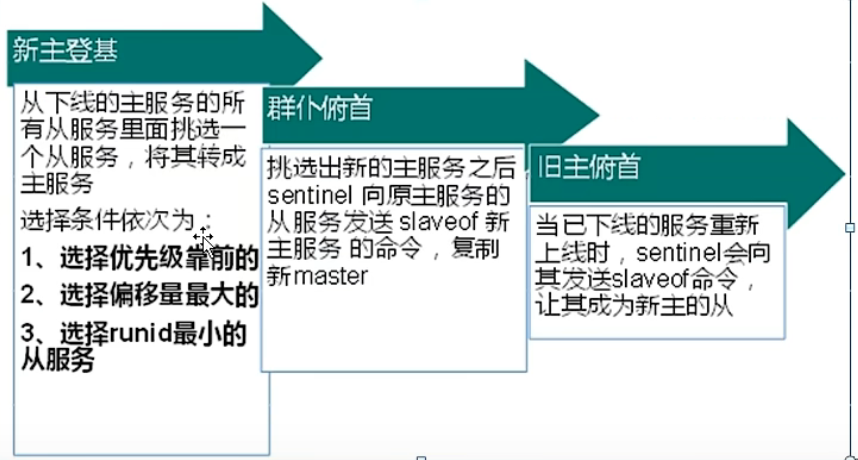
反客为主:当上游服务器挂掉,下游服务器自动顶替。输入slaveof no one在预定顶替的服务器里,等上游机挂掉后会自然成为主服务器。
2.4 哨兵模式
反客为主的自动版,能够后台监控主机是否故障,如果故障了就根据投票数自动将从库转为主库。
1.首先先关闭所有redis服务器。然后逐个启动redis服务器,进入。让6380和6381成为6379的从服务器。
2.再打开一个客户端连接。cd /myredis/,然后vi sentinel.conf,写入sentinel monitor mymaster 127.0.0.1 6379 1(mymaster是一个代号,最后参数1是指有多少个哨兵同意迁移的数量)。
3.在6381输入redis-sentinel sentinel.conf(默认端口26379),在6379里输入shutdown模拟挂掉情况,此时6381的哨兵会察觉,然后让6380成为新的主服务器。
4.此时重新启动6379,info replication,发现6379变成从服务器。
复制延时问题:

replica-priority是优先级,优先级最低是100,最高是0,值越低优先级越高。
偏移量:和主机同步的数量,越多偏移量越高。
runid是随机生成的。
十三、Redis6集群
容量不够,redis进行扩容。并发写操作,redis分摊。
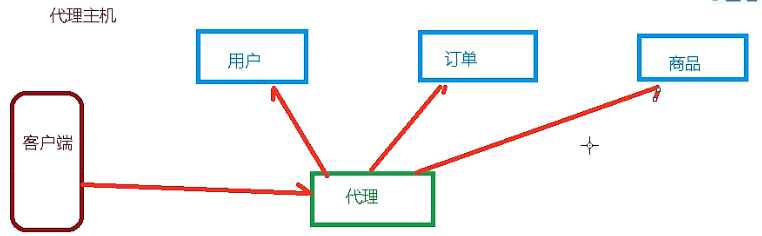
代理主机:
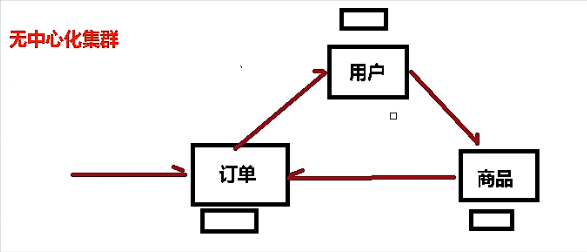
redis3.0无中心化集群:任何一台服务器都可以成为集群的入口,互相之间相互连通,会根据需求转发。
什么是集群:

搭建redis集群
1. cd /myredis。ll。删除文件rm -rf dump63*。rm -rf redis6380.conf。rm-rf redis6381.conf。vi redis6379.conf。删掉多余内容,值保留前4行。加上下面的3个配置:
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000第1行,打开集群模式。第2行,设置结点配置文件名。第3行,设置节点失联时间,超过该时间,集群自动进行主从切换。
2.再复制6379出来5份。cp redis6379.conf redis6380.conf。cp redis6379.conf redis6381.conf。cp redis6379.conf redis6389.conf。cp redis6379.conf redis6390.conf。cp redis6379.conf redis6391.conf。
3.vi redis6380.conf, :%s/6379/6380。vi redis6381.conf, :%s/6379/6381。vi redis6389.conf, :%s/6379/6389。vi redis6390.conf, :%s/6379/6390。vi redis6391.conf, :%s/6379/6391。
4.【注意要在root角色下】启动redis:redis-server redis6379.conf。redis-server redis6380.conf。redis-server redis6381.conf。redis-server redis6389.conf。redis-server redis6390.conf。redis-server redis6391.conf。
5.输入ll,要看到5个nodes-xxxx,5个redis63xxxxx的文件。
6.先cd /opt/redis-6.2.1/src,然后将下面的代码复制,输入到:
redis-cli --cluster create --cluster-replicas 1 192.168.182.151:6379 192.168.182.151:6380 192.168.182.151:6381 192.168.182.151:6389 192.168.182.151:6390 192.168.182.151:63917.redis-cli -c -p 6379(-c是采用集群策略连接,设置数据会自动切换到响应的写主机)。cluster nodes命令查看集群信息。
集群操作和故障恢复
参数为1时是最简单的,一个主节点+一个从节点搭配


slots是插槽,一个Redis集群包含16384个插槽(hash slots),假如添加一个key,会通过一个算法来计算,这个key属于哪个槽,集群中的每个节点负责处理一部分插槽,目的就是为了让key都尽可能均匀地分散在每个节点中。
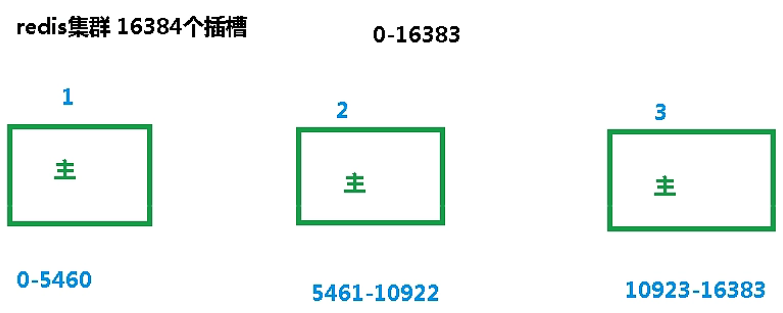
1. 因为是无中心化的,所以可以任选一台redis服务器作为入口服务器进行操作。输入set k1 v1,会返回插槽值12706,然后主机切换到6381。输入mset name lucy age 20会报错,不能插入多个key和value。user是组的名字,输入mset name{user} lucy age{user} 20,然后就是根据组的名字进行插槽的计算,插槽是5474。
2. 输入cluster keyslot 键,可以返回键对应的插槽值。输入cluster countkeysinslot 插槽值,可以得到某个键是否在插槽中,注意要在对应插槽范围的主机下访问。
挂掉之后15秒的等待时间,主机挂掉后从机成为主机,主机复活后成为从机。
集群的Jedis开发
创建RedisClusterDemo:
public class RedisClusterDemo {public static void main(String[] args) {//创建对象HostAndPort hostAndPort = new HostAndPort("192.168.182.151", 6379);JedisCluster jedisCluster = new JedisCluster(hostAndPort);//进行操作jedisCluster.set("b1","value1");String value = jedisCluster.get("b1");System.out.println("value:"+value);jedisCluster.close();}
}十四、Redis6应用问题解决
缓存穿透
现象:1. 应用服务器压力突然变大。2.redis命中率降低。3.一直查询数据库。
1. redis查询不到数据。2.出现很多非正常url访问(访问不到界面,恶意攻击))

解决方案:
1. 对空值缓存。就算数据在数据库中查不到,仍旧进行缓存。设置空结果的过期时间很短,最长不超过5分钟。

2. 设置可访问的名单(白名单)。使用bitmaps类型定义一个可以访问的名单,每次访问和bitmap里的id进行比较,如果没有就进行拦截,不允许访问。效率比较低。

3.采用布隆过滤器(Bloom Filter)。实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。

4. 进行实时监控:
![]()
缓存击穿
现象:1.数据库访问压力瞬时增加。2.redis里面没有出现大量key过期。3.redis正常运行,但数据库崩溃。
问题原因:redis某个key过期了,而当时又有大量的访问使用这个key(是一些热门的访问)。

解决方案:
1. 预先设置热门数据。把热门数据提前存入redis,加长热门数据key的时长。
2.实时调整。
3.使用锁。


缓存雪崩
现象:1.数据库压力变大,服务器崩溃。
原因:在极小时间段,大量key集中过期,查询不到缓存数据进而访问数据库崩溃的情况。
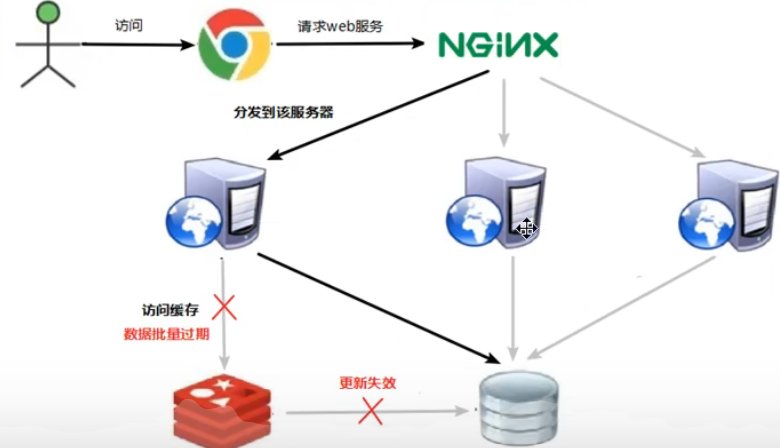
解决方案:
1. 构建多级缓存架构:nginx缓存+redis缓存+其它缓存。
2. 使用锁或队列:保证不会有大量的线程对数据库一次性进行读写。

3.设置过期标志更新缓存:如果key过期会触发通知另外的线程在后台去更新实际key的缓存。
4.将缓存失效时间分散开。在原有的失效时间基础上增加一个随机值,降低缓存过期时间的重复率。

分布式锁

随着业务发展,单体单级部署的系统会演化成分布式集群系统。原单级部署情况下的并发控制锁策略失效。需要一种跨JVM的互斥机制来控制共享资源的访问。

分布式锁的主流方案:1.基于数据库。2.基于缓存Redis(性能最高)。3.基于Zookeeper(最可靠)。


设置锁和过期时间
EX second : 设置键的过期时间为second秒。SET key value EX second效果等同于SETEX key second value。
1. 在6379中输入setnx users 数值,设置锁。del users,删除锁。
2.在6379中输入setnx users 10,expire users 10设置10秒的过期时间,然后ttl users即可查看过期时间。
3.在set users 10 nx ex 12(nx是上锁,ex是设置过期时间,10是指,12是时间)
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock","111",3,TimeUnit.SECONDS);
if(lock){Object value = redisTemplate.opsForValue().get("num");if(StringUtils.isEmpty(value)){ //判断Num为空returnreturn;}int num = Integer.parseInt(value+""); //有值就转为intredisTemplate.opsForValue().set("num",++num);//把redis的num加1redisTemplate.delete("lock");//释放锁,del
}else{try{Thread.sleep(100);testLock();}catch(InterruptedException e){e.printStackTrace();}
}ab -n 1000 -c 100 http://192.168.182.151:8080/redisTest/testLock
上锁+1,释放锁,重复该操作。最终num的值会变成1000。
UUID防止误删
释放的不是自己锁,释放的是别人的锁:a先操作,先上锁,然后具体操作,假设在具体操作时服务器卡顿了,超过了10秒,锁自动释放。假设b抢到了锁,也是先上锁,然后进行具体操作,假设还没操作完,a服务器突然反应过来了,a会进行操作,手动释放锁。此时释放的就是b的锁。
使用UUID防止误删:
第1步:uuid表示不同的操作 set lock uuid nx ex 10。
第2步:释放锁的时候,首先判断当前uuid和要释放锁uuid是否一样。
更改代码如下:
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock","111",3,TimeUnit.SECONDS);
if(lock){Object value = redisTemplate.opsForValue().get("num");if(StringUtils.isEmpty(value)){ //判断Num为空returnreturn;}int num = Integer.parseInt(value+""); //有值就转为intredisTemplate.opsForValue().set("num",++num);//把redis的num加1String lockUuid = (String)redisTemplate.opsForValue().get("lock");if(lockUuid.equals(uuid)){redisTemplate.delete("lock");//释放锁}LUA保证删除原子性
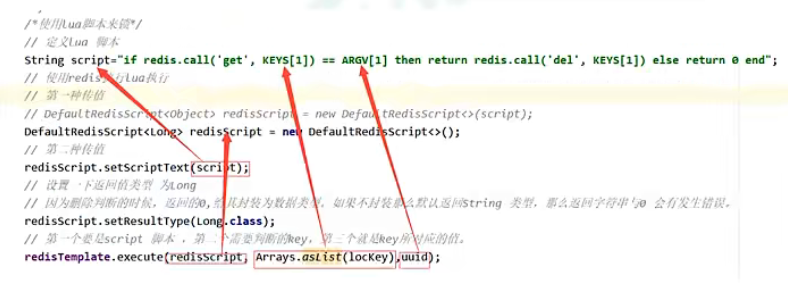
删除操作缺乏原子性。
先上锁,然后具体操作,最后释放锁。释放锁要uuid比较,如果一样才删除。假设正要删除,还没有删除,此时锁到了过期时间,自动释放。此时b可以获取到锁,然后进行具体操作。因为a还能继续进行删除操作,此时a能释放b的锁。
十五、Redis6新功能
— — — — — — — — — — — — — — — —
先输入: cd /usr/local/bin,再输入:redis-server /etc/redis.conf 启动服务器,/usr/bin/redis-cli 进入redis。
快照失败原因:首先要sudo su进入到root用户,然后ps -ef | grep redis杀掉进程,redis-server /etc/redis.conf启动服务,一定要让redis是在root用户下启动的,这样子对dump.rdb的权限才是足够的。
这篇关于Redis学习笔记(下):持久化RDB、AOF+主从复制(薪火相传,反客为主,一主多从,哨兵模式)+Redis集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




