本文主要是介绍Python识别PDF扫描版PDF纯图PDF,OCR提取汉字的10大方法,力推RapidOCRPDF 可识别纯图PDF 加密签名的PDF 重点是开源免费,某些方面准确度比百度OCR高,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
下面实例都以下面的测试样例PDF为实验对象
非纯图可复制pdf
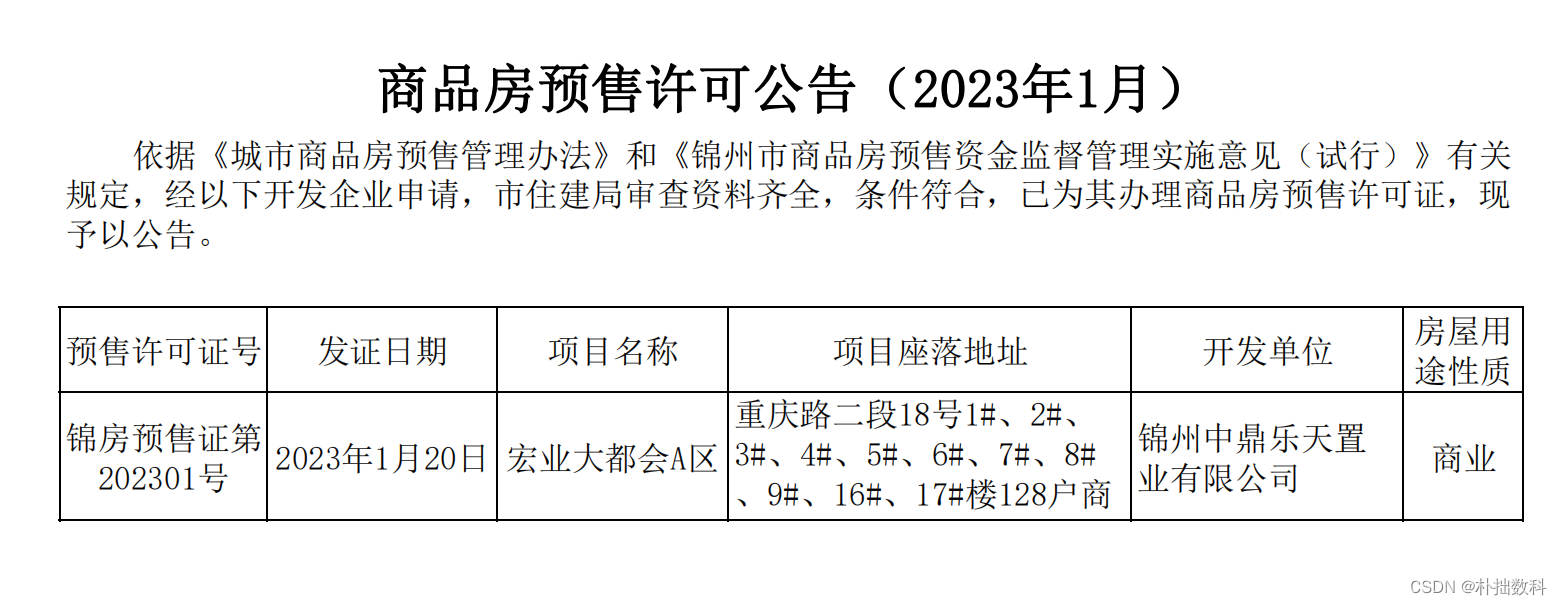
纯图PDF

TOP1:RapidOCRPDF 可识别纯图PDF也能识别加密签名的PDF 重点是开源免费
https://github.com/RapidAI/RapidOCRPDF
# 基于rapidocr_onnxruntime
pip install rapidocr_pdf[onnxruntime]# 基于rapidocr_openvino
pip install rapidocr_pdf[openvino]
依托于RapidOCR仓库,快速提取PDF中文字,包括扫描版PDF、加密版PDF。
如果是可以直接复制的PDF,可以直接使用pdf2docx,不再重复造轮子
如果是扫描版PDF,暂时不支持版式还原,后续有空会考虑加上,日期不定。
from rapidocr_pdf import PDFExtracterpdf_extracter = PDFExtracter()pdf_path = 'example4.pdf'
texts = pdf_extracter(pdf_path)print(texts)
优化版,修改源码,得到位置版式
[['0', '甬金铁路涉及220千伏岩礼4R92线岩泉4R93线#21-#23塔迁改工程中标结果公\n(招标编号:ZJGZDL-2023-04-N02)\n一、中标人信息:\n标段(包)[001]甬金铁路涉及220千伏岩礼4R92线岩泉4R93线#21-#23塔迁改工程:\n中标人:绍兴建元电力集团有限公司\n中标费率:下浮3.50%\n二、其他:\n绍兴建元电力集团有限公司为中标人\n三、监督部门\n本招标项目的监督部门为绍兴电力局招投标管理中心。\n四、联系方式\n招标人:嵊州市铁路项目工程建设指挥部\n地址:绍兴嵊州市\n联系人:吕先旺\n电话:18069621508\n电子邮件:544142621@qq.com\n招标代理机构:浙江广正建设项目管理有限公司\n地址:\n浙江省绍兴市越城区阳明北路80号A楼四楼4-1\n联系人:\n高强\n电话:\n13867532448\n电子邮件:\n734201819@qq.com\n%(签名)\n招标人或其招标代理机构主要负责人(项目负)\n上海有限公公\n招标人或其招标代理机构:\n(盖章)\n正建设\n浙江', '1.0']]
import json
import warnings
from pathlib import Path
from typing import Dict, List, Tuple, Union
import filetype
import fitz
import cv2
import numpy as np
from rapidocr_onnxruntime import RapidOCR
from rapidocr_pdf import PDFExtracter, PDFExtracterErrorclass PDFExtracterABC(PDFExtracter):def __init__(self, dpi=200):super(PDFExtracterABC, self).__init__(dpi)def __call__(self, content: Union[str, Path, bytes]) -> List:try:file_type = self.which_type(content)except (FileExistsError, TypeError) as e:raise PDFExtracterError('The input content is empty.') from eif file_type != 'pdf':raise PDFExtracterError('The file type is not PDF format.')try:pdf_data = self.load_pdf(content)except PDFExtracterError as e:warnings.warn(str(e))return self.empyt_listtxts_dict, page_idxs = self.extract_texts(pdf_data)page_img_dict = self.read_pdf_with_image(pdf_data, page_idxs)ocr_res_list = self.get_ocr_res(page_img_dict)return ocr_res_listdef get_ocr_res(self, page_img_dict: Dict) -> List:ocr_res = []for k, v in page_img_dict.items():preds, _ = self.text_sys(v)if preds:i, rec_res, _ = list(zip(*preds))print(i, rec_res, _)det_list = []for m, n in zip(i, rec_res):det_dict = {'position': m,'text': n}det_list.append(det_dict)data = {'page': k,'det': det_list}ocr_res.append(data)# ocr_res[str(k)] = '\n'.join(rec_res)return ocr_respdf_extracter = PDFExtracterABC()pdf_path = 'example.pdf'
texts = pdf_extracter(pdf_path)
print(json.dumps(texts, indent=4, ensure_ascii=False))
([[234.0, 243.0], [1343.0, 245.0], [1343.0, 278.0], [234.0, 276.0]], [[550.0, 373.0], [1029.0, 373.0], [1029.0, 404.0], [550.0, 404.0]], [[236.0, 521.0], [469.0, 521.0], [469.0, 551.0], [236.0, 551.0]], [[275.0, 584.0], [1304.0, 586.0], [1304.0, 616.0], [275.0, 614.0]], [[317.0, 647.0], [765.0, 650.0], [765.0, 680.0], [317.0, 677.0]], [[854.0, 652.0], [1125.0, 652.0], [1125.0, 679.0], [854.0, 679.0]], [[231.0, 708.0], [374.0, 708.0], [374.0, 746.0], [231.0, 746.0]], [[275.0, 776.0], [722.0, 776.0], [722.0, 806.0], [275.0, 806.0]], [[230.0, 838.0], [424.0, 838.0], [424.0, 871.0], [230.0, 871.0]], [[274.0, 904.0], [932.0, 905.0], [932.0, 935.0], [274.0, 934.0]], [[231.0, 965.0], [426.0, 965.0], [426.0, 998.0], [231.0, 998.0]], [[272.0, 1031.0], [808.0, 1031.0], [808.0, 1060.0], [272.0, 1060.0]], [[268.0, 1090.0], [555.0, 1090.0], [555.0, 1126.0], [268.0, 1126.0]], 这篇关于Python识别PDF扫描版PDF纯图PDF,OCR提取汉字的10大方法,力推RapidOCRPDF 可识别纯图PDF 加密签名的PDF 重点是开源免费,某些方面准确度比百度OCR高的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




