本文主要是介绍从数据可视化到场景渲染:山海鲸的创新与实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作为山海鲸的开发者,我们深知可视化模型场景渲染在数据分析和决策支持中的重要作用。因此在保证山海鲸可视化软件免费编辑、分享、部署的同时也在场景渲染方面不断优化,本文将介绍山海鲸在可视化模型场景渲染方面的技术革新与实践探索。
首先,山海鲸采用了自研Cetus3D 渲染引擎 ,能做出可媲美游戏场景的数字孪生画面。我们运用精细的几何建模和纹理映射技术,将现实世界中的建筑、地形、植被等元素细致入微地呈现出来。这使得用户能够更加直观地理解数据,并从多角度、多维度地观察和分析场景。


其次,山海鲸引入了实时渲染技术,确保了模型场景的流畅展示和交互体验。我们利用高效的图形处理单元(GPU)加速技术,大幅提升了渲染性能和响应速度。用户可以在山海鲸平台上进行实时缩放、旋转、移动等操作,观察场景中的细节变化,实现动态数据可视化。


此外,山海鲸还注重场景渲染的视觉效果和用户体验。我们运用高级着色器和光照模型,模拟自然光照和环境效果,为模型场景带来更加真实、生动的视觉感受,还可以直接在软件中模拟不同天气变化。同时,通过简洁直观的用户界面设计,用户可以轻松上手操作,无需复杂的设置和操作步骤。

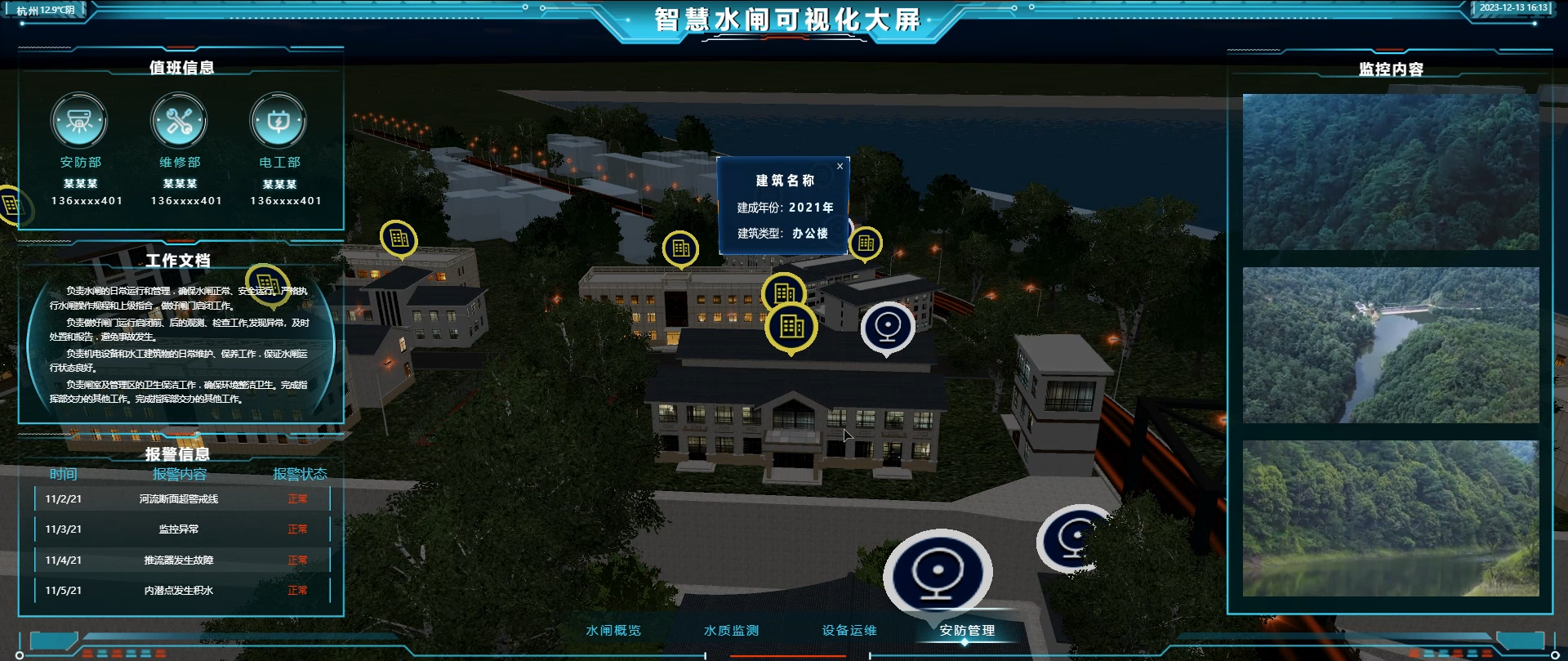

总之,山海鲸可视化模型场景渲染作为我们技术革新的重要方向之一,已经取得了一系列成果和突破。我们将继续致力于提升可视化技术的性能和效果,推动其在数据分析和决策支持领域的广泛应用。同时,我们也期待与更多合作伙伴共同探讨和实践可视化技术的未来发展,为智慧城市、数字孪生等领域提供更多创新解决方案。
这篇关于从数据可视化到场景渲染:山海鲸的创新与实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







