本文主要是介绍SQL中FOREIGN KEY(外键)约束用于确保一个表中的数据匹配另一个表中的值,从而保证参照完整性,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
FOREIGN KEY(外键)是用于确保一个表中的数据与另一个表中的值匹配的参照完整性约束。为了更形象地解释它,让我们使用一个具体的示例来说明:
假设我们有两个表:Customers(顾客)和Orders(订单)。Customers表包含顾客的信息,而Orders表包含订单的信息。每个订单都必须与一个特定的顾客相关联,这就是我们要使用FOREIGN KEY来实现的。
在Customers表中,我们有一个主键列P_Id,它唯一标识每个顾客的ID。在Orders表中,我们希望创建一个FOREIGN KEY,将其指向Customers表中的P_Id列,以确保每个订单都与一个有效的顾客关联。
通过使用FOREIGN KEY约束,我们可以在创建或修改表时指定这种关系。下面是一些创建和修改表时使用FOREIGN KEY约束的SQL示例:
1. 使用CREATE TABLE语句创建FOREIGN KEY约束:
CREATE TABLE Orders (O_Id int NOT NULL PRIMARY KEY,OrderNo int NOT NULL,P_Id int,FOREIGN KEY (P_Id) REFERENCES Persons(P_Id)
);
上述代码在创建Orders表时,指定了一个FOREIGN KEY约束,将P_Id列作为外键,参照了Persons表中的P_Id列。
2. 使用ALTER TABLE语句添加FOREIGN KEY约束:
ALTER TABLE Orders
ADD FOREIGN KEY (P_Id)
REFERENCES Persons(P_Id);
上述代码在Orders表已被创建后,通过ALTER TABLE语句添加了一个FOREIGN KEY约束。
无论是使用CREATE TABLE还是ALTER TABLE语句,我们可以选择给FOREIGN KEY约束命名,并定义多个列的FOREIGN KEY约束。这有助于提高约束的可读性和维护性。
如果我们想撤销FOREIGN KEY约束,可以使用ALTER TABLE语句的DROP CONSTRAINT子句:
ALTER TABLE Orders
DROP CONSTRAINT fk_PerOrders;
上述代码将撤销名为"fk_PerOrders"的FOREIGN KEY约束。
总之,FOREIGN KEY约束是用于确保表之间数据的一致性和完整性的重要工具。它通过建立引用关系,使得一个表中的数据能够正确地引用另一个表中的值。
表格举例
让我们以一个名为"Orders"和"Persons"的数据库表为例来说明FOREIGN KEY约束的概念。
假设我们有以下的"Persons"表结构:

以及以下的"Orders"表结构:
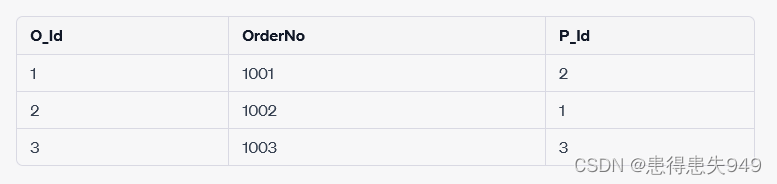
在这个例子中,"Orders"表中的"P_Id"列将作为FOREIGN KEY与"Persons"表中的"P_Id"列的PRIMARY KEY进行关联。这样可以确保在"Orders"表中的"P_Id"列中的值必须在"Persons"表中的"P_Id"列中存在。
我们可以通过以下方式来定义FOREIGN KEY约束:
-- 创建表时的FOREIGN KEY约束
CREATE TABLE Orders (O_Id int NOT NULL PRIMARY KEY,OrderNo int NOT NULL,P_Id int,FOREIGN KEY (P_Id) REFERENCES Persons(P_Id)
);或者
-- 修改表时的FOREIGN KEY约束
ALTER TABLE Orders
ADD FOREIGN KEY (P_Id) REFERENCES Persons(P_Id);通过上述代码,我们建立了"Orders"表中的"P_Id"列与"Persons"表中的"P_Id"列之间的关联。这意味着在"Orders"表中的"P_Id"列的每个值必须存在于"Persons"表的"P_Id"列中,确保了数据的参照完整性。
通过FOREIGN KEY约束的关联,你可以根据"Orders"表中的"O_Id"找到对应的"Persons"表中的行内容。
在上述的例子中,我们有以下的"Orders"表结构:

和以下的"Persons"表结构:
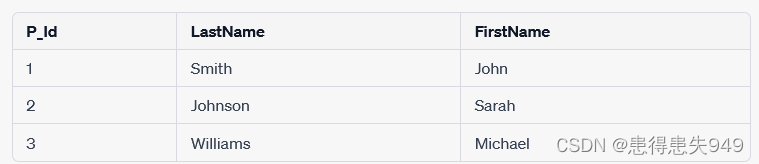
如果你想要根据"Orders"表中的"O_Id"查找对应的"Persons"表中的行内容,可以执行以下查询:
SELECT *
FROM Orders
JOIN Persons ON Orders.P_Id = Persons.P_Id
WHERE Orders.O_Id = 1;
这个查询将返回与"Orders"表中"O_Id"为1的记录相关联的"Persons"表中的行内容。
查询结果示例:

通过FOREIGN KEY约束,我们可以方便地根据一个表中的数据(例如"Orders"表中的"O_Id")找到另一个表中相关的数据(例如"Persons"表中的对应行内容)。这样的关联查询使得我们可以获取跨表的相关信息,提高了数据的查询灵活性和准确性。
这样,我们可以通过连接这两个表来进行关联查询,例如找到特定订单的相关客户信息。
在这个例子中,"Orders"表的"P_Id"列作为FOREIGN KEY与"Persons"表的"P_Id"列的PRIMARY KEY进行关联。FOREIGN KEY约束确保了在"Orders"表中的"P_Id"列的值必须存在于"Persons"表中的"P_Id"列中。这样可以建立表与表之间的关联关系,并确保数据的参照完整性。
外键(FOREIGN KEY)通常与主键(PRIMARY KEY)相连。主键是唯一标识表中每条记录的列,而外键是用于建立表与表之间关联的列。
在关系型数据库中,外键用于建立引用完整性(Referential Integrity),确保表之间的数据关联是有效和一致的。外键的值必须与主表中的主键值匹配,这样可以确保关联的数据存在且有效。
通常情况下,外键约束定义在一个表中的列上,该列引用了另一个表中的主键列。这种关系被称为父表(Parent Table)和子表(Child Table)之间的关系,其中父表的主键列是子表的外键列。
然而,需要注意的是,并非所有的外键都必须与主键相连。在某些情况下,外键也可以与唯一约束(UNIQUE CONSTRAINT)或主键的组合(多个列的主键)相连。这种情况下,外键引用的是确保唯一性的列或列组合。
总而言之,虽然外键通常与主键相连,但也可以与唯一约束或主键的组合相连,以建立有效的数据关联。这样可以确保数据的完整性和一致性。
这篇关于SQL中FOREIGN KEY(外键)约束用于确保一个表中的数据匹配另一个表中的值,从而保证参照完整性的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





