本文主要是介绍【万字长文】多模态预训练模型研究进展,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1 背景
- 2 单模态表示
- 2.1 NLP领域
- 2.2 CV领域
- 3 多模态领域
- 3.1 三个关键问题
- 模态表征
- 模态融合
- 预训练任务
- 3.2 下游任务
- 多模态理解
- 多模态生成
- 4 多模态模型发展
- 双塔阵营
- 1 VilBERT 2019 NeurlPS
- 2 LXMERT 2019 EMNLP
- 单塔阵营
- 1 VisualBERT 2019
- 2 VL-BERT 2020 ICLR
1 背景
从2018年Bert横空出世以后,以预训练模型为基石的各个领域百花齐放,多模态预训练模型也是在这样一个背景下诞生的,具体大概是从2019年开始涌现的。
在传统NLP单模态模型中,表征学习的发展较为完善,但在多模态,由于高质量标注数据集的限制,少样本学习以及零样本学习是研究的重点。基于Transformer结构的多模态预训练模型,通过海量无标注数据进行预训练,然后使用少量有标注数据进行微调即可。
通常多模态分为:
- 文字-图像多模态
- 文字-音频多模态
- 文字-视频多模态
- 音频-视频多模态
一般是人类看到是实物,声音甚至味道都是一种模态信息。以下介绍将基于最常用的语言视觉多模态(Language-Vision mulmodal)。在介绍多模态之前,需要掌握单模态的特征表征的方法。
2 单模态表示
2.1 NLP领域
对于一短文本。表征的发展主要有以下四个阶段:
-
文本的独热表示
矩阵 X = [ x i , x 2 , . . . x n ] T X=[x_i,x_2,...x_n]^T X=[xi,x2,...xn]T 表示一个句子,其中 xi 是第 i 个单词的独热表示向量。 xi 是一个维度等于词典包含的单词个数且元素取值为 0,1 向量, 且只有一个元素值为 1 , 其余元素都为0 , 值为 1 的元素在向量中的位置与 xi 所表示的单词在词典中的位置坐标相同。
-
文本的低维空间表示
分布性假设指一个单词或字包含的信息被其上下文中的单词确定, 而不是由单词或字本身决定, 例如北京、东京等首都城市名称上下文中的单词相似程度较高, 这类单词或字的语义信息就相近。用 x ′ = x W x'=xW x′=xW线 性方程创建一个语义空间, 其中 [公式] 为一个单词或字的独热表示向量, W W W为一个在神经网络模型上学习得到的转换矩阵, x ′ x' x′是该单词或字在语义空间中的向量, 在语义空间中, 包含的信息相近的单词或字的表示向量距离较近。
-
文本序列的词袋表示
对于短语、句子、段落和文档。假定x表示一个单词序列, x是一个维度等于词典包含的单词个数 且元素取值为 0,1 的向量, 值为1的元素在向量中的位置与单词序列中包含的所有单词在词典中的位置相同, 其余元素为 0 。
词袋表示忽略了词语在单词序列中的先后顺序, 考虑词语顺序后, 词袋模型衍生出句子 n-grams 词袋模型。词袋表示和 n-grams 词袋表示的语言模型常能获得较准确的结果, 但是都没有考虑单词的语义信息。
-
文本序列的低维空间表示
获取文本序列模态的语义表示,即将文本序列映射到语义空间中。在早期的获取单词序列模态的语义表示的探索中,最简单的方法就是加权平均单词序列中各单词的语义表示向量,还有一种较复杂的方法是按照句子解析树的单词顺序,将句子组织为矩阵。这两种方法都有各自的缺点,前者在加权平均的过程中忽略了单词先后顺序, 后者的核心是句子的解析, 其适用对象局限于句子。
为解决这些不足, 研究人员提出了递归神经网络,由于递归神经网络的输入序列长度可变以及当前输出与之前输入有关等特性, 递归神经网络成为句子模态处理中非线性映射的主流模型,而目前主流的表示方法是预训练文本模型例如:BERT。
2.2 CV领域
视觉模态分为图像模态和视频模态,视频模态实在时间维度哈桑展开的一个图像序列,因此关键是图像的向量表达。
在深度学习中,卷积神经网络是在多层神经网络的基础 上发展起来的针对图像而特别设计的一种深度学习方法,在本节中,对经典的卷积神经网络展开论述,如 LeNet-5、AlexNet、 VGG、GoogLeNet、ResNet和CapsNet。
将卷积神经网络 的卷积和池化操作理解为产生图像模态矩阵表示的过程,将全连接层或全局均值池化层的输入理解为图像模态的向量表示。
-
LeNet 1998年
以Yann LeCun为首的研究人员实现了一个七层的卷积神经网络LeNet-5以识别手写数字。
LeNet-5 的输入为包含数字或字母的灰度图像,经过卷积和池化后产生特征图像,即图像模态的矩阵表示,特征图像经过维度变化后获得全连接层的输入,即图像模态的向量表示。
-
AlexNet 2012年
通过更多的卷积和池化操作以及归一化处理和 dropout ,Relu激活函数等方法,在网络深层的卷积层和池化层获得图像的矩阵表示, 即通过增加网络深度获取了包含图像深度语义信息的特征表示。 -
GAN 2014年
GAN的基本思想是串联训练两个网络-生成器和鉴别器。生成器的目标是生成使鉴别器蒙蔽的样本,该样本经过训练可以区分真实图像和生成的图像。随着时间的流逝,鉴别器将在识别假货方面变得更好,但生成器也将在欺骗鉴别器方面变得更好,从而生成看起来更逼真的样本。GAN的第一次迭代会产生模糊的低分辨率图像,并且训练起来非常不稳定。但是随着时间的推移,变化和改进。 -
VGG 2014年
与AlexNet 增加神经网络深度的方式不同,VGG通过构建含有多个卷积子层的卷积层实现网络深度的拓展,它每层都有 2~4 个卷积子层,用较小的卷积核和多个卷积层实现了对图片特征的精细抓取。VGG 的结构使得其能深度提取图像中的精细的语义特征,获得更好的图像模态表示。 为获得更好的图像模态表示,研究者不断地尝试增加网 络的深度,但是发现当网络深度增加到一定程度后网络性能逐渐变差,获得的图像模态表示反而不能更好地提取图像模态信息

-
GoogleNet 2014年
提出 Inception 模块。Inception 模块具有高效表达特征的能力,它包含 1x1、3x3、5x5 三种尺寸的卷积核,以及一个 3x3 的下采样,不同尺寸的卷积核赋给 Inception 模块提取不同尺寸的特征的能力。Inception 模块从纵向和横向上,增加了卷积层 的深度,使得 GoogLeNet 能够产生更抽象的图像模态的矩阵 表示。
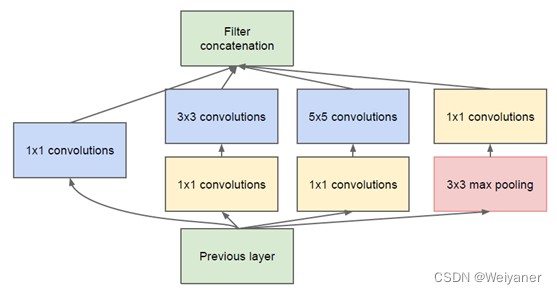
-
ResNet 2015年
是在增加网络深度的研究方向上进行了突破性探索的深度卷积网络,由融合了恒等映射和残差映射的构造性模块堆栈后构成。当在网络已经到达最优情况下继续向深层网络运算时,构造性模块中的残差映射将被置 0,只剩下恒等映射,这样使网络在更深的网络层上也处于最优。
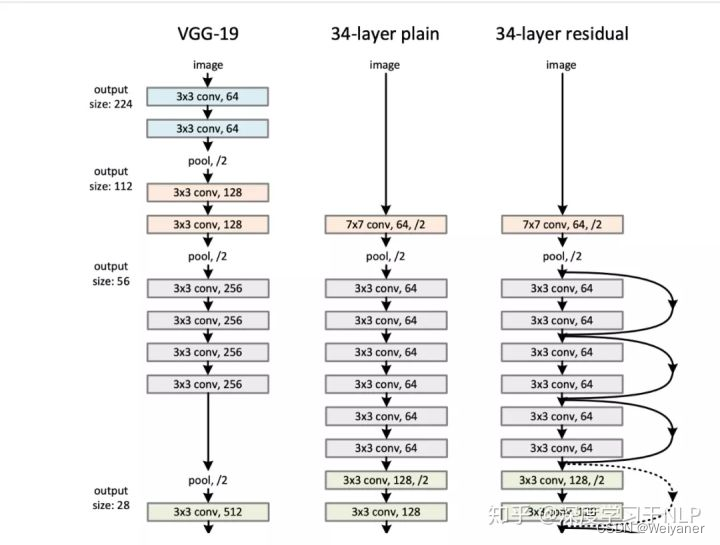
3 多模态领域
3.1 三个关键问题
分别是模态表征,模态融合和预训练任务。
模态表征
要解决的问题是怎么分别量化文字和图像,进而送到模型学习?对于文字和图像特征,用各自领域的模型进行表征,得到向特征量。
文本端的表征标配就是bert的tokenizer,更早的可能有LSTM;
图像的话就是使用一些传统经典的卷积网络(如chap2),按提取的形式主要有三种Rol、Pixel、Patch三种形式。
模态融合
要解决的问题是怎么让文字和图像的表征交互?是单流交互还是双流交互(也就是前融合和后融合的方式。当然还有一类是Multi-stream(MMFT-BERT),
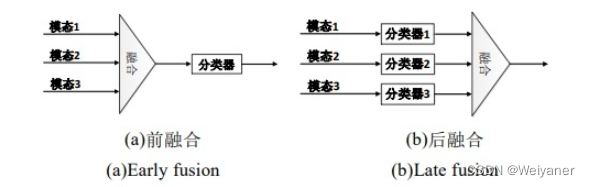
预训练任务
就是怎么去设计一些预训练任务来辅助模型学习到图文的对齐信息?也就是,模态对齐。这也是多模态领域最重要的一部分内容和研究重点。
比如,在如下文本-图像对中,需要对齐“白色台阶”和“猫”在图像中的区域,实现模态对齐。
白色台阶上有只猫

- MLM:掩码语言模型,对于文本序列进行mask,学习词向量表达
- MRM(Mask Region Modeling),对图片随机mask,被随机屏蔽的概率是15% ,替换成 0 和保持不变的概率分别是 90%和10%。
- ITM(Image-Text matching),文本-图像匹配任务,针对图文交叉流,判断当前的pair是不是一个匹配,通过将image的token和文本的cls做元素外积,在经过一个MLP进行相似性的监督学习。
3.2 下游任务
多模态模型一般应用于2大领域理解和生成。
多模态理解
主要是进行分类任务,比如:
-
Visual Question Answering (VQA):输入是一张图片及一个问题(用文本描述),输出是一组答案集合中的一个答案,即可以把他当成一个分类任务,模型需要从3129个合适的答案中找到对应问题的答案,一般用acc作为metric。例如:
where is he looking?

{‘answers’: [{‘answer’: ‘down’, ‘answer_confidence’: ‘yes’, ‘answer_id’: 1},
{‘answer’: ‘down’, ‘answer_confidence’: ‘yes’, ‘answer_id’: 2},
{‘answer’: ‘at table’, ‘answer_confidence’: ‘yes’, ‘answer_id’: 3},
{‘answer’: ‘skateboard’, ‘answer_confidence’: ‘yes’, ‘answer_id’: 4},
{‘answer’: ‘down’, ‘answer_confidence’: ‘yes’, ‘answer_id’: 5},
{‘answer’: ‘table’, ‘answer_confidence’: ‘yes’, ‘answer_id’: 6},
{‘answer’: ‘down’, ‘answer_confidence’: ‘yes’, ‘answer_id’: 7},
{‘answer’: ‘down’, ‘answer_confidence’: ‘yes’, ‘answer_id’: 8},
{‘answer’: ‘down’, ‘answer_confidence’: ‘yes’, ‘answer_id’: 9},
{‘answer’: ‘down’, ‘answer_confidence’: ‘yes’, ‘answer_id’: 10}],
‘image_id’: 262148,
‘multiple_choice_answer’: ‘down’,
‘question_id’: 262148000,
‘question_type’: ‘none of the above’}可以看到,对于一张图片,一个问题,可能会有很多答案都被视为正确答案。由于这种不确定性,很多作者将VQA视作一个多标签的分类问题。即不将ground truth视作一个one hot向量,反之,根据每个答案的出现次数,给annotation一个soft label.
-
Visual Reasoning: Visual Reasoning是一个二分类任务,输入是一句文本描述以及两张图片,输出是这个文本描述是否正确。同样是以acc作为metric。
The left image contains twice the number of dogs as the right image, and at least two dogs in total are standing

多模态生成
对于给定图片/文字生成文字描述或者图片描述
- Image Caption:根据图片生成文字描述
- text to image:根据文字生成图片(佛说,要有光)
4 多模态模型发展
多模态模型分为单塔和双塔两个阵营,由于单塔的速度更快,对此,现阶段的我偏向于双塔模型,单塔的模型精度更高但对应的代价也很高。
双塔阵营
1 VilBERT 2019 NeurlPS
论文:Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
地址:https://arxiv.org/pdf/1908.02265.pdf
代码:https://github.com/facebookresearch/vilbert-multi-task
Model
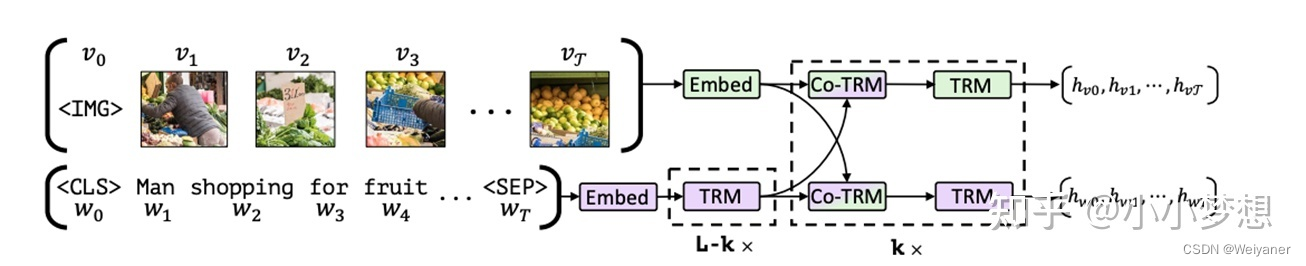
Motivation
NLP领域于2018年提出了bert(双向transformer)预训练模型,成为了领域的通用预训练模型。而在图文交叉领域还没有一个通用的预训练模型,提出视觉和文本统一建模。
Method
(1)特征提取
- 文本采用bert的tokenizer。
- 图片是基于一个pretrain的object-detection网络生成图像rpn及其视觉特征。
具体的是使用bounding boxes的左上角和右下角的坐标以及图像区域的覆盖占比形成的一个5-dim的vec,然后用一个MLP将之映射成与视觉特征一样的维数,然后做sum。
(2)特征融合
通过co-TRMe完成文本和图片向量的交叉(下图右)。传统的TRM的q,k,v是来自同一个vec(self-attention),这里为了交互改进了这一结构,具体的为了在表征图片的时候考虑到其文本的上下文,那么q来自图片,而k,v都来自文本,同样在表征文本的时候,其k,v来自图片。
图片采用Faster R-CNN模型从图像中提取多个目标区域的特征**,由于图片特征不像文字特征一样含有位置信息,因此用5维数据给图片位置编码**,它们分别是归一化之后左上角坐标,右下角坐标,以及面积。然后将其投影到匹配视觉特征的维度,并对其求和。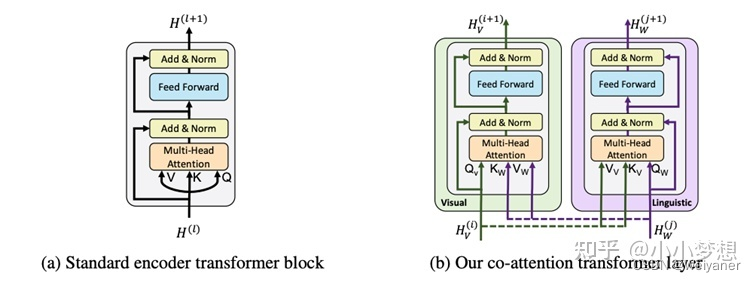
Task
- Masked Language Modeling (MLM):15%(80%,10%,10%)
- Masked Object Classifation (MOC):15%(90%,10%)—语言只能表达图片的高阶语义信息
- Visual-linguistic Matching (VLM)
2 LXMERT 2019 EMNLP
论文:Learning Cross-Modality Encoder Representations from Transformers
论文链接:https://arxiv.org/pdf/1908.07490.pdf
代码链接:https://github.com/airsplay/lxm
Model:
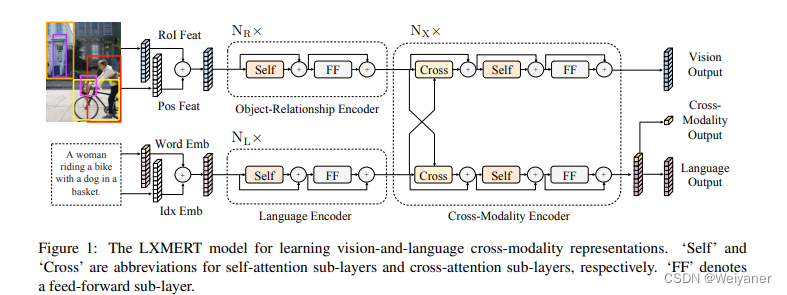
Motivation
和vilbert不同的是cross-attention在cross操作后加入一个全连接层,同时融合了图片和文字的信息。增加了一些预训练任务目标,比如Masked Cross-Modality LM。
Method
(1)特征提取
- 文本使用bert的tokenizer
- 图片使用object-detection对图片进行分块,注意这里只是得到了Rol, 本质上还是图片,为了量化具体采用的是pre-trained R-CNN提取得到的表征。
(2)特征融合
和ViLBERT一样,都是采用Co-TRM进行双塔。
Task
- 掩蔽文本预测(Masked Cross-Modality LM)该任务的设置与BERT的MLM任务设置一致。作者认为除了从语言模态中的非模态词中预测被掩蔽词外,LXMERT还可利用其跨模态模型架构,从视觉模态中预测被掩蔽词,从而解决歧义问题,所以将任务命名为Masked Cross-Modality LM以强调这种差异。
- 掩蔽图像类别预测(Detected-Label Classification)该任务要求模型根据图像线索以及对应文本线索预测出直接预测被遮蔽ROI的目标类别。
- 掩码图像特征回归(RoI-Feature Regression)不同于类别预测,该任务以L2损失回归预测目标ROI特征向量。
图片-文本对齐(Cross-Modality Matching)通过50%的概率替换图片对应的文本描述,使模型判断图片和文本描述是否是一致的。 - 图像问答(Image Question Answering)使用了有关图像问答的任务,训练数据是关于图像的文本问题。当图像和文本问题匹配时,要求模型预测这些图像有关的文本问题的答案
单塔阵营
1 VisualBERT 2019
论文:A Simple and Performant Baseline for Vision and Language
地址:https://arxiv.org/pdf/1908.03557.pdf
代码:https://github.com/uclanlp/visualbert
Model
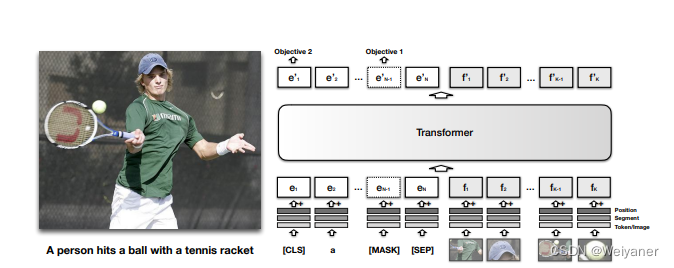
Motivation
文字和图片统一进行语义学习,提出单流的方法(更简单)
Method
(1)特征提取
- 文本采用的是bert的tokenizer
- 图片这里依然使用的是ROI。
(2)特征融合
不像vilbert一样图文和文字分别进入transformer进行学习,将文本和图片一起输入transformer。因为单流,需要增加段编码。
Task
MLM,ITM(Image-Text Modeling)
2 VL-BERT 2020 ICLR
论文:Pre-training of Generic Visual-Linguistic Representations0
地址:https://arxiv.org/pdf/1908.08530.pdf
代码:https://github.com/jackroos/VL-BERT
Model
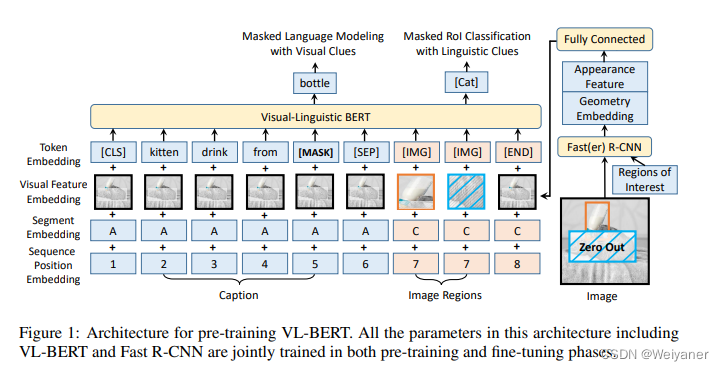
Motivation
- 在19年的ViLBERT和LXMERT中,提出了image-text关系预测任务对视觉语言表征的预训练毫无帮助,因此拿掉了这个任务。
- 在视觉语言和纯文本数据集上预先训练VL-BERT。发现这种联合预训练提高了对长句子和复杂句子的泛化能力。
- 改进了视觉表示的调整。在VL-BERT中,快速R-CNN的参数也得到了更新,从而得到了视觉特征。为了避免语言线索掩盖的RoI分类预训练任务中的视觉线索泄漏,对输入的原始像素进行掩蔽操作,而不是对卷积层生成的特征图进行掩蔽操作。
method
(1)特征提取
-
文本:bert的tokenizer
-
图片:object-detection+Faster-RCNN。
-
Token embedding层:对于文本内容使用原始BERT的设定,但是添加了一个特殊符[IMG]作为图像的token。
-
Visual feature embedding层:这层是为了嵌入视觉信息新添加的层。该层由视觉外部特征以及视觉几何特征拼接而成,具体而言,对于非视觉部分的输入是整个图像的提取到的特征,对应于视觉部分的输入即为图像经过预训练之后的Faster R-CNN提取到的ROI区域图像的相应视觉特征。
-
Segment embedding层:模型定义了A、B、C三种类型的标记,为了指示输入来自于不同的来源,A、B指示来自于文本,分别指示输入的第一个句子和第二个句子,更进一步的,可以用于指示QA任务中的问题和答案;C指示来自于图像。
-
Position embedding层:与BERT类似,对于文本添加一个可学习的序列位置特征来表示输入文本的顺序和相对位置。对于图像,由于图像没有相对的位置概念,所以图像的ROI特征的位置特征都是相同的。
(2)特征融合
单流融合,左边文本,右边图片。
·task·
-
MLM「掩蔽文本预测(Masked Language Model with visual Clues)」 此任务与BERT中使用的Masked Language Modeling(MLM)任务非常相似。关键区别在于,在VL-BERT中包含了视觉线索,以捕获视觉和语言内容之间的依存关系。
-
MRC「掩蔽图像类别预测(Masked RoI Classification with Linguistic Clues)」 类似于掩蔽文本预测,每个RoI图像以15%的概率被随机掩蔽,训练的任务是根据其他线索预测被掩藏的RoI的类别标签。值得一提的是为了避免由于其他元素的视觉特征的嵌入导致视觉线索的泄漏,在使用Faster R-CNN之前,需要先将被Mask的目标区域的像素置零。
这篇关于【万字长文】多模态预训练模型研究进展的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








