本文主要是介绍Atlas 200 DK 系列--初级篇--MindStudio常见操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
Mind Studio是一套基于华为昇腾AI处理器开发的AI全栈开发平台,包括基于芯片的算子开发、以及自定义算子开发,同时还包括网络层的网络移植、优化和分析,另外在业务引擎层提供了一套可视化的AI引擎拖拽式编程服务,极大的降低了AI引擎的开发门槛,全平台通过Web的方式向开发者提供以下4项服务功能。
- 针对算子开发
Mind Studio提供全套的算子开发环境、支持真实环境运行,支持针对动态调度的异构程序的可视化调试,支持第三方算子开发,极大的降低了基于华为自研NPU的算子开发门槛,提高算子开发效率,有效提升产品竞争力。
- 针对网络层的开发
Mind Studio集成了离线模型转换工具(OMG)、模型量化工具、模型精度比对工具、模型运行Profiling分析工具和日志分析工具,极大的提升了网络模型移植和分析优化的效率。
- 针对AI引擎开发
Mind Studio提供了AI引擎可视化拖拽式编程以及大量的算法代码自动生成技术,极大的降低了开发者的门槛,并且预置了丰富的算法引擎,如:Resnet18等,大大提高了用户AI算法引擎开发及移植效率。
- 针对应用开发
Mind Studio内部集成了各种工具如Profiler、Compiler等,为用户提供图形化的集成开发环境,通过Mind Studio进行工程管理、编译、调试、仿真、性能分析等全流程开发,从而提高开发效率。
一、 卸载Mind Studio
卸载Mind Studio过程中,会自动卸载DDK,使用安装用户权限登录Mind Studio后台服务器,在linux系统的“~/tools/bin”目录下执行./uninstall.sh命令卸载Mind Studio。操作步骤如下:
1. 切换到root用户在“/usr/bin”目录下为Mind Studio安装用户加权。
su root
cd /usr/bin
./add_sudo.sh username
说明:
如果不执行上述加权操作,则会在执行卸载脚本时出现如下提示信息,停止卸载。
Please check if add_sudo.sh, del_sudo.sh exists and execute the add_sudo.sh script with root privileges
2. 切换到Mind Studio的安装用户,在“~/tools/bin”目录下执行./uninstall.sh卸载脚本。
说明:
若卸载失败,需要重新执行1进行加权操作。
3. 是否需要备份用户数据:
[WARNING] Do you need to backup for user data (include projects my-datasets my-model caffe-model mongodb profiling) ? [Y/N]
(输入Y/y回车备份用户数据,进入3.a;输入N/n回车不备份,则进入3.b)
(只有/home/username/wsbackup不为空才会出现该信息,若为空,则进入4)若备份用户数据,则提示:
[WARNING] Directory /home/username/wsbackup is not empty, please make your choice! [Y:(Continue to overwrite backup)/N:(Change a directory)]:
(输入Y/y回车使用默认路径覆盖备份数据,输入N/n回车更换备份路径)
若不备份用户数据,则提示是否需要删除用户数据:
[WARNING] Are you sure to remove user data (include projects my-datasets my-model caffe-model mongodb profiling) ? [Y/N]:
(输入Y/y回车删除用户数据;输入N/n回车不删除)
4. 停止HiAI_CCE-Profiler服务。
5. 卸载mongodb。
6. 停止Web服务。
7. 备份用户的数据,包括工程、自定义数据集、自定义模型等(backup路径)。
8. 若出现“Uninstallation finished.”则表明卸载成功。
二、查询Mind Studio版本
版本查询有两种方式:一种方法是通过后台命令查询;另一种是通过前台界面查询。
通过后台命令查询
Mind Studio安装成功之后,进入“~/tools/conf”目录,执行命令cat version查看Mind Studio版本,如图1所示:
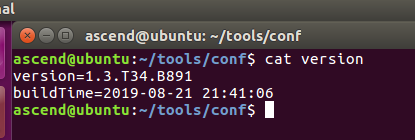
图1 后台查看Mind Studio版本
通过界面查询
登录 Mind Studio界面,在菜单栏依次选择 “Help > About”:
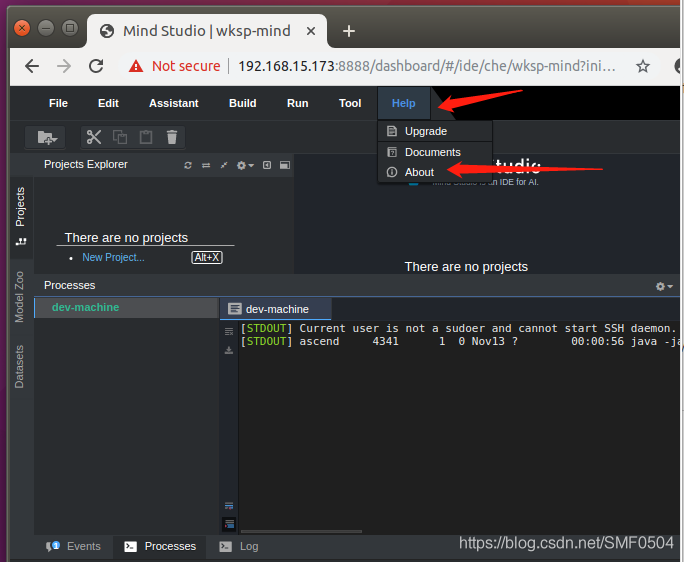
在弹出的窗口中会显示 Mind Studio版本信息,如 图2所示:

图2 前台界面查看Mind Studio版本
三、修改IP地址
若用户想要更换Ubuntu服务器的IP地址,则Mind Studio安装使用的IP地址也要随之更换,方法如下:
1.如果env.conf文件中的IP配置为Ubuntu服务器IP地址,则修改IP时,直接将env.conf文件中的IP地址改为新的Ubuntu服务器IP。
2. 如果env.conf文件中的IP配置为any:
a. 如果env.conf文件中use_eth0取值为true,则修改eth0的IP地址,重新启动Mind Studio,新的IP地址生效。
b. 如果env.conf文件中use_eth0取值为false,则重新启动Mind Studio,在多个网卡中选择输入IP,新IP地址生效。
说明:
env.conf文件路径:~/tools/scripts/env.conf。
这篇关于Atlas 200 DK 系列--初级篇--MindStudio常见操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



