本文主要是介绍大模型LLM Agent在 Text2SQL 应用上的实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.前言
在上篇文章中「如何通过Prompt优化Text2SQL的效果」介绍了基于Prompt Engineering来优化Text2SQL效果的实践,除此之外我们还可以使用Agent来优化大模型应用的效果。
本文将从以下4个方面探讨通过AI Agent来优化LLM的Text2SQL转换效果。
- 1 Agent概述
- 2 LangChain中的Agent模块
- 3 Agent优化Text2SQL效果的实践
- 4 后续计划
Text2SQL 系列
- 如何通过 Prompt 优化大模型 Text2SQL 的效果
- 大模型LLM在 Text2SQL 上的应用实践
技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
建立了大模型技术交流群,大模型学习资料、数据代码、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:技术交流
方式②、添加微信号:mlc2060,备注:技术交流

2. Agent概述
2.1 Agent概念
在大语言模型LLM领域中,Agent是一个人工智能系统的设计理念,它旨在模拟人类或其他智能体的行为和决策过程。Agent被设计为能够在特定环境中运作,能够感知环境状态,处理信息,制定策略,执行行动,并根据反馈调整其行为。
Agent 的本质是教大模型一些思考方法论,就好像人们已经有了知识,但可能缺乏思考的方法。因此,Agent通过一个框架传授方法论,这个框架具有一些具体模块,支持整个结构的运行。
2.2 Agent关键组件
Open AI的Lilian Weng在个人博客发表的一篇文章:LLM Powered Autonomous Agents描述了 Agent 系统的全貌:
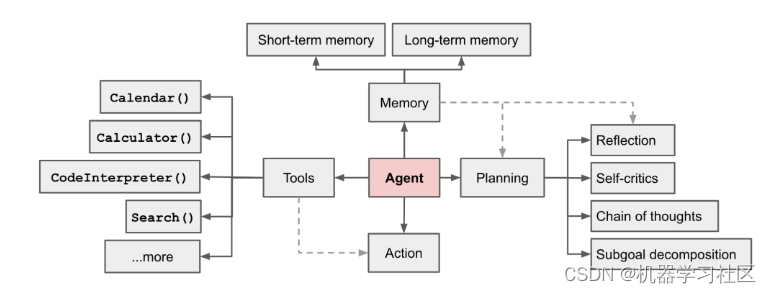
图1. LLM Powered Autonomous Agents系统
Agent: 核心,理解为可以处理一些复杂操作的“代理”服务,其核心驱动力是大模型;
Tools: 提供给 Agent 的工具,例如计算、搜索网络、代码执行等;
Memory: 由数据库或者其他存储上保存交流的历史记录,防止交流过程中遗忘之前的信息;
Planning: LLM的一些能力,包括反射、目标分解、反思、思维链。
2.2.1 Planning
一个复杂的任务通常涉及多个步骤,Agent需要知道这些步骤并提前计划,类型包括:
-
子目标和任务分解
-
反思与改进
1. 子目标和任务分解: Agent将大型任务分解为更小、更易管理的子目标,使得能够有效地处理复杂任务。其技术研究包括:
-
思维链(CoT;Wei等人,2022年)已成为增强模型在复杂任务上性能的标准提示技术。模型被指示“一步一步思考”,利用更多测试时间计算将困难任务分解为更小、更简单的步骤。CoT将大任务转化为多个可管理的任务,并揭示了模型思考过程的解释。
-
思维树(ToT;Yao等人,2023年)通过在每一步探索多种推理可能性扩展了CoT。它首先将问题分解为多个思维步骤,并在每一步生成多个思想,创建一个树状结构。搜索过程可以是广度优先搜索(BFS)或深度优先搜索(DFS),每个状态由分类器(通过Prompt)或多数投票评估。
任务分解可以通过以下方式进行:
-
LLM使用简单的提示,如“Steps for X.Y.Z.”,“What are the subgoals for achieving XYZ?”
-
使用任务特定的指令,例如用于写作“Write a story outline.”
-
用户输入
2. 反思与改进: Agent可以对过去的行为进行自我校准和自我反思,从错误中学习并改进未来步骤,从而提高最终结果的质量。其技术研究包括:
- ReAct(Yao等人,2023年)通过将“Acting行为”和“Reasoning推理”组合,在LLM中集成推理和行动。前者使LLM能够与外部环境交互(例如Wikipedia搜索API),而后者提示LLM生成自然语言中的推理轨迹。
ReAct提示模板包含LLM思考的明确步骤,大致格式为:
Thought: ...
Action: ...
Observation: ...
... (Repeated many times)
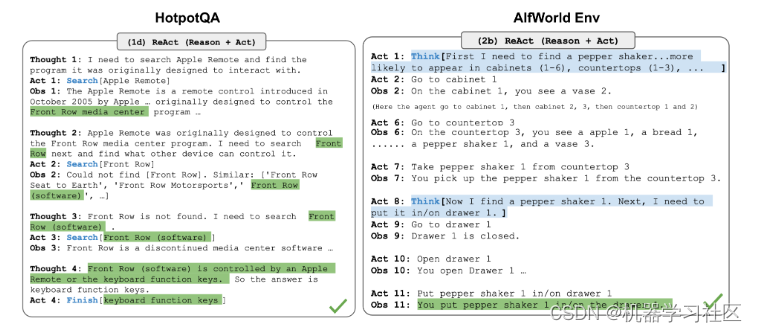
图2.ReAct模式推理轨迹
上面是一个例子。问题是:除了Apple Remote之外,还有什么设备可以控制 Apple Remote 最初设计用于交互的程序吗?
然后 ReAct 就会一步步拆开,第一个 Thought:需要查找 Apple Remote原生的交互程序;然后进行一个 Action,去 google 找这个问题答案。然后进行下一个 Thought:Apple remote 是一个控制媒体的程序,需要查找其他可以控制媒体中心的程序,然后继续下一个 Action:找不到;然后继续 Thought:找其他相关的;然后找到了。把找到的信息填入到最后一个 Thought,得到最终答案。
所以 ReAct 是通过外部工具和反复查找匹配得到最终答案的过程。
这样似乎给我们打开了一个新的解决问题的路径。利用 LLM 的拆解问题的能力,在中间过程投喂信息。人工参与确认是否正确,直至找到人类认可的答案。
- Reflexion(Shinn & Labash,2023年)是一个框架,为Agent配备动态记忆和自我反思能力,以提高推理技能。遵循ReAct的设置,在每次动作a后,Agent计算一个启发式h,并根据自我反思结果选择是否重置环境以开始新的试验。
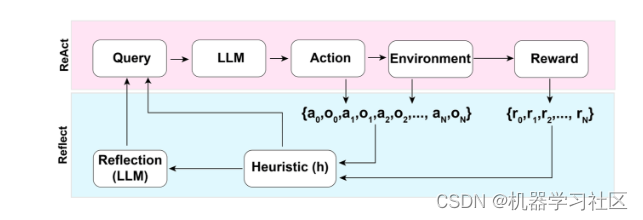
图3. Reflexion框架示意图
- Chain of Hindsight(CoH;Liu等人,2023年)其思想是在上下文中呈现顺序改进的输出历史,并训练模型跟随趋势生成更好的输出。算法蒸馏(AD;Laskin等人,2023年)将相同的想法应用于强化学习任务中的跨情节轨迹,其中算法被封装在长历史条件策略中。考虑到Agent与环境互动多次,并且在每个情节中Agent都会变得更好一点,AD连接这一学习历史并将其输入到模型中。因此,我们应该期望下一个预测动作比之前的试验表现更好。
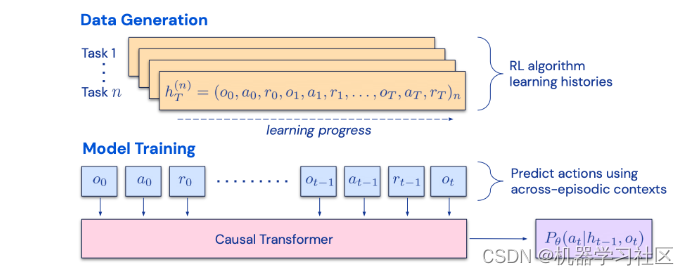
图4. 算法蒸馏(AD)工作原理示意图
2.2.2 Memory
Memory可以定义为获取、存储、保持和随后检索信息的过程。Memory类型如下:
(1) 感觉Memory:这是Memory的最早阶段,表示为原始输入(包括文本、图像或其他模态)的Embedding表示。
(2) 短期Memory:认为所有在上下文学习(见Prompt Engineering)中利用的都是模型的短期Memory来学习;是短暂和有限的,因为它受到Transformer上下文窗口长度的限制。
(3) 长期Memory:这为Agent提供了在长时间内保留和回溯(无限)信息的能力,通常利用外部向量存储和快速检索实现。
2.2.3 Tools
Agent可以调用外部API获取模型权重中缺失的额外信息(通常在预训练后难以更改),包括当前信息、代码执行能力、访问专有信息源等。
Tools使用意味着Agent能够识别和利用外部资源(如API、数据库或其他模型)来增强其解决问题的能力。这可能包括学习如何调用适当的API获取额外信息、从数据库中检索相关数据或组合多个模型的输出以生成更全面的答案。通过这种方式,Tools使用使Agent能够适应不断变化的环境和任务需求,提高其灵活性和效率。
MRKL(Karpas等人,2022年),“Modular Reasoning, Knowledge and Language”, MRKL系统包含一组“专家”模块,而LLM作为路由器,将请求路由到最适合的专家模块。这些模块可以是神经网络(例如深度学习模型)或调用模块(例如数学计算器、货币转换器、天气API)。
我们熟悉的ChatGPT插件和OpenAI API函数调用是LLM与工具增强的好例子。这些工具允许LLM访问额外的信息源和计算能力,从而扩大其解决问题的能力范围。
3. LangChain中的Agent模块
3.1 Agent模块概述
在LangChain的Agents这个模块中,Agent 类型有多个,包括:Zero-shot ReAct、Conversational 以及 Plan-and-execute等。其中ReAct就是所谓Reasoning + Acting 模式,把复杂问题拆开,有些缺少的内容通过工具从外部获取,然后补充到问题回答里。
那么LangChain 是怎么实现的呢?
LangChain设置了两种模式:
(1)Action Agents,就是下一步的动作由上一步的输出决定
(2)Plan-and-execute Agents,就是计划好所有的步骤,然后顺序执行
在执行过程中, Agent可以调用一些 tools,来辅助过程。例如 google 搜索、语音识别、文件处理、python执行等等。tools 就是给Agent配备了一些工具箱ToolKit。
3.2 Agent示例
示例的代码如下:
# 设置一个搜索工具
search = SerpAPIWrapper()
tools = [Tool(name = "Current Search",func=search.run,description="useful for when you need to answer questions about current events or the current state of the world"),]# 提供交互中的“memory”存储
memory = ConversationBufferMemory(memory_key="chat_history")# 设置 agent chain
llm=OpenAI(temperature=0)
agent_chain = initialize_agent(tools, llm, agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION, verbose=True, memory=memory)
执行提问:
agent_chain.run(input="whats the current temperature in pomfret?")
执行结果如下:
> Entering new AgentExecutor chain...Thought: Do I need to use a tool? Yes
Action: Current Search
Action Input: Current temperature in Pomfret
Observation: Partly cloudy skies. High around 70F. Winds W at 5 to 10 mph. Humidity41%.
Thought: Do I need to use a tool? No
AI: The current temperature in Pomfret is around 70F with partly cloudy skies and winds W at 5 to 10 mph. The humidity is 41%.> Finished chain.'The current temperature in Pomfret is around 70F with partly cloudy skies and winds W at 5 to 10 mph. The humidity is 41%.'
上面代码逻辑还是比较清楚,设置工具,设置 chain。运行之后,会出现Thought->Action->Observation的模式。这就是上面所说的"ReAct"模式。
3.3 ReAct模式解析
在执行run之后,LangChain会按照模型来顺序执行,这里是默认AI Agent执行模型,根据返回结果执行下一步。
这里会有一个疑问,为什么提交到LLM之后,可以返回Thought->Action->Observation 的模式?奥秘还是在提示(Prompt)模板上。
在使用agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION之后,Prompt就会被格式化成如下这样:
"Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:
Search: useful for when you need to answer questions about current events.
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [Search]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question Begin!"
在提示模板里面,说明了需要按照 Search、Question、Thought、Action这种模式来回答,还告诉LLM,可以使用Search这个工具,之后LLM按照要求回答,LangChain就可以按照格式返回获取对应的Thought。然后可以提供新的工具或者与用户的交互输入,形成新的提示词再继续提交给LLM,直至获得最终结果。
这种做法打开了新的一扇窗,当下流行的AutoGPT、BabyAGI也是类似的机制。
4. Agent优化Text2SQL效果的实践
4.1 现有问题
依然以上篇文中的数据库Chinook为例,需求为统计“连续两个月都下订单的客户有哪些?”,示例代码可参考上文。
结果如下:
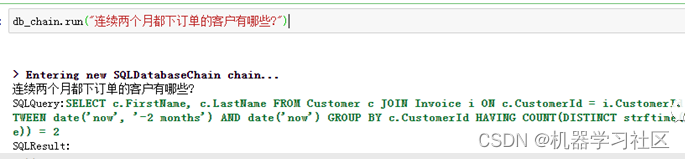
可以看出生成的SQL不准确,只统计了最近两个月中都下订单的客户,和统计需求不相符。那如何解决这个问题?
4.2 Agent解决方案
LangChain的SQL Agent提供一种比SQLDatabaseChain更灵活的与SQL数据库交互的方式。
使用SQL Agent的主要优点是:
(1)可以根据Database Schema和数据库的内容(如描述特定的表)回答问题;
(2)可以通过运行生成的查询、捕获回溯并正确的重新生成,以此来纠错。
我们可以使用create_sql_agent函数来初始化SQL Agent。此Agent包含SQLDatabaseToolkit,其中包含用于执行以下操作的工具:
-
创建和执行查询
-
检查SQL查询语法
-
检索表的描述
示例代码如下:
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit# from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentTypedb = SQLDatabase.from_uri("sqlite:///xxx/Chinook.db")agent_executor = create_sql_agent(llm=OpenAI(temperature=0),toolkit=SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0)),verbose=True,agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
执行提问:
agent_executor.run("在订单表中,连续两个月都下订单的客户有哪些?")
结果如下:
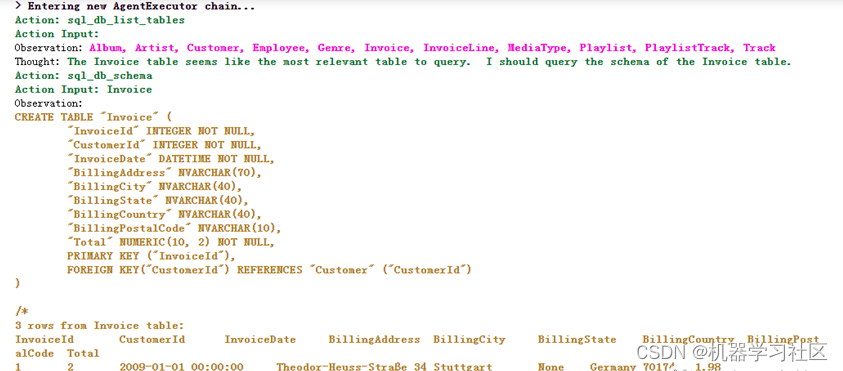
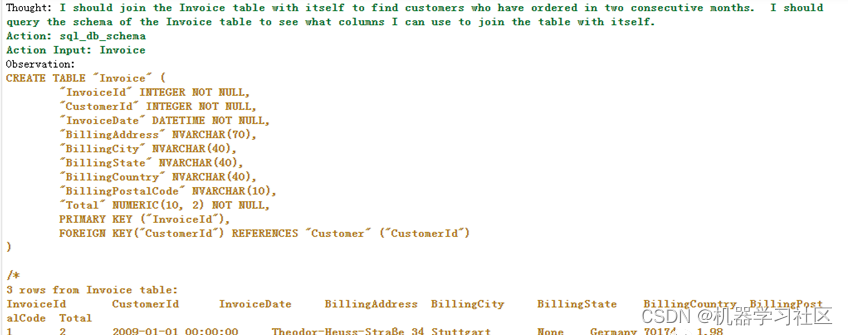
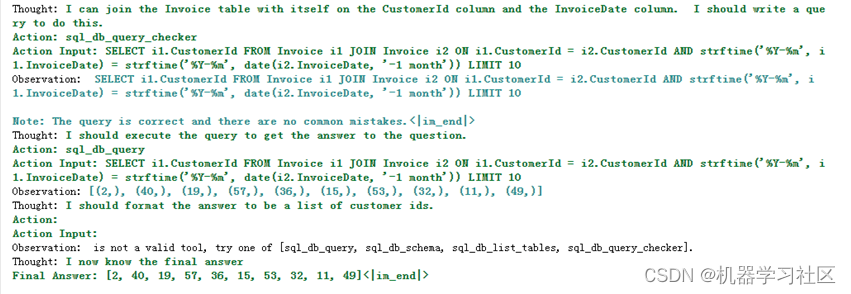
效果: 生成的SQL基本满足我们的需求。
我们可以进一步通过LangSmith trace查看AgentExecutor执行过程:
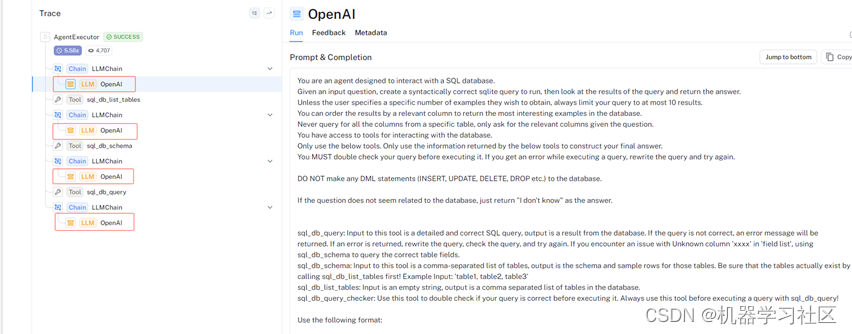
5.后续计划
本文介绍了通过Agent来优化Text2SQL生成结果的案例,通过SQLDatabaseToolkit工具与Database进行交互,LLM按照要求回答,LangChain可以按照格式返回获取对应的Thought,然后可以提供新的工具或者与用户的交互输入,形成新的提示词再继续提交给LLM,直至获得最终结果。总的来说,Agent提供了一种新的方法来优化LLM在Text2SQL应用上的效果。通过Thought->Action->Observation,我们可以step by step分解问题,借助LLM更好地理解用户的查询,从而提高查询的准确性和效率。但仍然存在一些技术挑战需要克服,包括上下文长度限制、长期规划和任务分解的复杂性,以及自然语言接口的可靠性问题,后续持续更新。这些问题的解决将进一步推动Agent在LLM应用中的发展和效率提升。
参考文献:
https://lilianweng.github.io/posts/2023-06-23-agent
https://python.langchain.com/docs/modules/agents
https://python.langchain.com/docs/integrations/toolkits/sql_database
https://python.langchain.com/docs/use_cases/qa_structured/sql
https://zhuanlan.zhihu.com/p/643799381
https://zhuanlan.zhihu.com/p/664281311
这篇关于大模型LLM Agent在 Text2SQL 应用上的实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








