本文主要是介绍针对大规模服务日志敏感信息的长效治理实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1 背景
- 2 目标与措施
- 3 实施
- 3.1 脱敏工具类
- 3.2 JSON脱敏
- 3.3 APT自动脱敏
- 3.3.1 本地缓存问题
- 3.3.2 JDK序列化问题
- 3.4 弃用方案
- 4 规划
- 5 总结
1 背景
近年来,国家采取了多项重要举措来加强个人数据保护,包括实施《中华人民共和国网络安全法》和《个人信息保护法》等法律法规。这些举措旨在确保用户隐私的安全,同时确保企业合规运营。在处理敏感数据时,企业有责任采取适当的措施来保护用户信息。
在数据保护方面,日志记录成为一个需要特别关注的敏感信息领域。因此,本文将重点介绍转转在日志脱敏方面的应用与实践。
2 目标与措施
目标:
对日志内的手机号、身份证号、银行卡号等敏感信息脱敏,建立一个可持续的日志敏感信息管控机制。
措施:
- 检测和定位存在敏感日志的服务与CASE;
- 开发低接入成本的日志脱敏工具;
- 推动相关业务进行迭代修改;
- 长期监控和持续治理,确保日志安全。

我们的第一步是利用大数据离线扫描服务日志,并使用正则表达式匹配敏感信息。
然而,第二和第三步是挑战的关键,即
如何在不干扰业务正常迭代排期的情况下,推动大量服务的日志做脱敏。
我们希望使用技术手段尽量降低业务日志脱敏的人力成本。
3 实施
参考《转转日志规范》查看标准日志输出要求,在此基础之上,提供一些工具辅助业务对日志脱敏。
【推荐】JavaBean类需实现toString()方法,日志直接打印对象,慎用JSON工具将对象转换成String。
3.1 脱敏工具类
我们开发了脱敏工具类,期望
业务同学在实现JavaBean toString()方法的同时,使用脱敏工具对敏感字段使用脱敏。
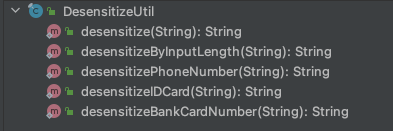
desensitize(String input):通用脱敏函数,支持对任意字符脱敏,将提取字符串中4位以上数字(如手机号、银行卡号、身份证号、数字验证码等)做脱敏;desensitizeByInputLength(String input):据字符串长度匹配不同的脱敏规则,如:11位则使用手机号脱敏规则,18位则使用身份证号脱敏规则;desensitizePhoneNumber(String phoneNumber):脱敏手机号,前3位和后4位,中间的数字用*代替;desensitizeIDCard(String idCard):脱敏身份证号, 保留前6位和后4位,脱敏7~15位生日信息, 用*代替;desensitizeBankCardNumber(String bankCardNumber):脱敏银行卡号, 前6位和后4位,中间的数字用*代替。
public final class DesensitizeUtil { /*** 根据字符串长度匹配不同的脱敏函数, 强制脱敏*/public static String desensitizeByInputLength(String input) {int length = input.length();// 手机号if (length == 11) {return desensitizePhoneNumber(input);}// ,,,}/*** 脱敏手机号, 前3位和后4位,中间的数字用*代替*/public static String desensitizePhoneNumber(String phoneNumber) {// 11位手机号if (phoneNumber.length() == 11) {return phoneNumber.substring(0, phoneNumber.length() - 8) + "****" + phoneNumber.substring(phoneNumber.length() - 4);}return phoneNumber;}// 省略其他脱敏函数...}
3.2 JSON脱敏
在某些日志记录的场景中,会打印包含敏感字段的JSON格式的数据,需要对其中的敏感信息进行脱敏处理。
在常见的JSON工具中,比如Jackson,可以
使用自定义的序列化器/反序列化器来实现脱敏。
下面以Jackson为例进行说明:
首先,我们可以定义一个注解来标注哪些字段需要脱敏处理:
/*** 脱敏注解*/
@Target({ElementType.FIELD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Desensitize {}
然后,我们可以创建一个自定义的Jackson模块,通过继承BeanSerializerModifier类来修改字段的序列化行为。在这个类中,我们可以根据字段上的Desensitize注解来判断是否需要进行脱敏处理:
/*** Jackson脱敏序列化修改器*/
public class JacksonDesensitizeSerializerModifier extends BeanSerializerModifier {@Overridepublic List<BeanPropertyWriter> changeProperties(SerializationConfig config, BeanDescription beanDesc,List<BeanPropertyWriter> beanProperties) {for (BeanPropertyWriter beanProperty : beanProperties) {// 只针对使用了@Desensitize的字段做脱敏Desensitize desensitize = beanProperty.getAnnotation(Desensitize.class);if(desensitize != null) {// 指定自定义的序列化器beanProperty.assignSerializer(new Desensitization());}}return beanProperties;}/*** Jackson序列化器*/public class Desensitization extends StdSerializer<Object> {@Overridepublic final void serialize(Object value, JsonGenerator gen, SerializerProvider provider) throws IOException {// 根据长度对字段做脱敏String desensitize = DesensitizeUtil.desensitizeByInputLength(String.valueOf(value));gen.writeString(desensitize);}}
}
最后,我们需要注册这个自定义的模块到Jackson中
/*** JSON工具*/
public class JsonUtil {private static final ObjectMapper DESENSITIZE_OBJECT_MAPPER = newObjectMapper();private static ObjectMapper newObjectMapper() {ObjectMapper mapper = new ObjectMapper();//增加脱敏序列化器SimpleModule simpleModule = new SimpleModule("SimpleModuleDesensitize");simpleModule.setSerializerModifier(new JacksonDesensitizeSerializerModifier());mapper.registerModule(simpleModule);return mapper;}/*** 对象转JSON的自动脱敏工具*/public static <T> String object2DesensitizeString(T object) throws JsonProcessingException {return DESENSITIZE_OBJECT_MAPPER.writeValueAsString(object);}//...
}
对于业务同学而言,只需在需要脱敏的对象上添加脱敏注解,然后使用我们提供的JsonUtil进行脱敏操作,实现简单高效。
/*** 需要脱敏的对象*/
public class User {/*** 标记此字段需要脱敏*/@Desensitizeprivate String mobile;private String username;//getter setter...
}User user = new User();
user.setAge(18);
user.username = "zhangsan";
user.password = "123456";JsonUtil.object2DesensitizeString(user);
//输出结果: {"mobile":"135****5555","username":"张三"}
注意:以上代码只是一个示例,并不完整。在实际使用中,还需要根据具体的需求来灵活实现脱敏处理。
3.3 APT自动脱敏
在实际实施过程中,以上两个方案遇到了很多阻碍。主要问题在于业务同学
手动维护Bean的toString()方法过于繁琐、重复工作多、容易遗漏对象并导致增加或删除字段时需要不断修改toString()函数。此外,业务服务所依赖的Bean来源复杂,有可能是其他业务提供的第二方Jar包或第三方Jar包。
因此,在实际应用中,业务同学
更倾向于将Bean序列化为JSON
并输出到日志中,如下所示:
log.info("data={}", JsonUtil.object2DesensitizeString(bean));
然而,这种方法不符合《转转日志规范》要求,而且忽略了
JSON序列化性能
的问题。此外,这种方案也需要耗费大量的人力资源:
需要评估每一行日志,以确定是否需要添加JSON脱敏功能。
因此,业务同学提出了以下需求:是否可以实现类似Lombok一样的功能,
只需在Bean的字段上添加脱敏注解,就能在编译期自动实现脱敏后的toString()函数?
这样的话,在打印日志时直接打印对象即可自动脱敏。
经过调研发现,Lombok在编译时利用APT(Annotation Processing Tools)生成代码,实现了自动化的代码生成过程,从而简化了开发工作。
APT(Annotation Processing Tool)是Java的编译期注解处理器。它允许开发人员在编译期间处理注解,并根据注解和相关对象的信息生成Java代码模板或配置文件等。
APT的使用可以提高程序性能,因为它在代码编译时完成注解处理,而不是在运行时使用反射方式处理注解。
著名的开源框架,如Lombok、MapStruct和AutoService等,也使用了类似的技术来优化代码的生成和处理过程。
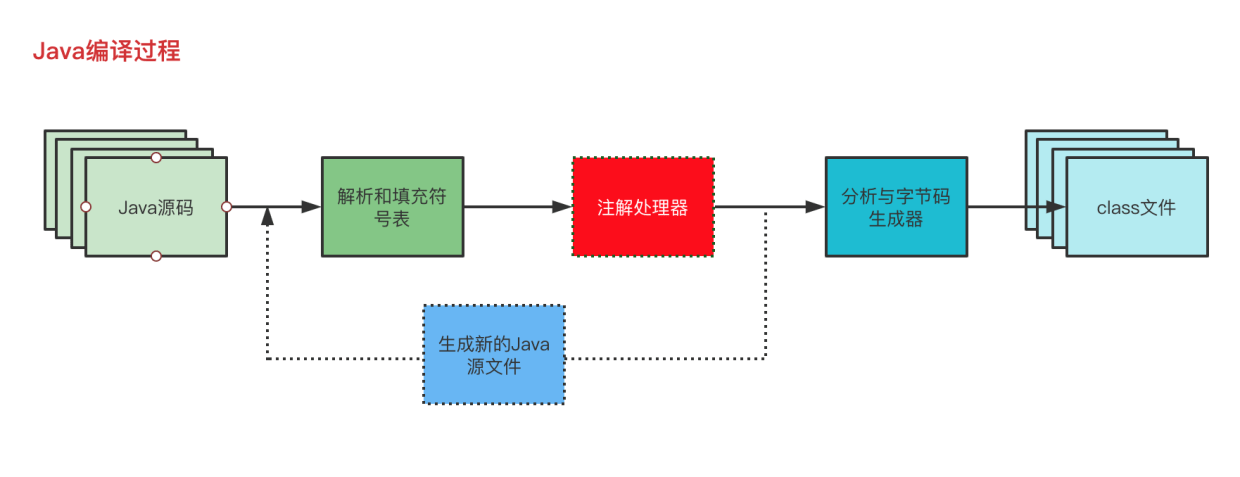
我们利用APT技术实现了这样的功能:
如果一个类没有重写Object.toString()方法,在编译时会自动为该类生成一个脱敏后的toString()方法。
这个自动生成的toString()方法能够识别脱敏注解,并在生成的toString()方法内对敏感信息进行脱敏处理。
在Java编译后的Class文件中,toString()方法可能来自三个来源:源代码、转转APT处理、Lombok等。优先级为:
源代码 > 转转APT处理 > Lombok等其他APT。
简言之,我们的APT处理不会覆盖源代码中定义的toString()方法,但会覆盖由Lombok生成的toString()方法。
比如,我们有以下源码:
class User {private String username;/*** 密码,增加了脱敏注解*/@Desensitizeprivate String password;
}
在接入转转APT后,反编译的Class文件如下:
class User {private String username;@Desensitizeprivate String password;public String toString() {StringJoiner sj = new StringJoiner(", ", "User[", "]");if (this.username != null) {sj.add("username=" + this.username);}if (this.password != null) {sj.add("password=" + DesensitizeUtil.desensitizeByInputLength(value));}return sj.toString();}
}
测试如下:
User user = new User();
user.username = "zhangsan";
user.password = "123456";System.out.println(user);
//输出结果: User[username=张三, password=1****6]
这个功能的上线大大降低了业务同学实现日志脱敏的工作量,只需为字段添加脱敏注解即可。同时,
也解决了线上对象未重写Object.toString()时打印日志的尴尬问题。
不过,
在落地APT过程中,我们也遇到了一些问题,
希望能给读者提供一些有收益的参考。
3.3.1 本地缓存问题
在某个服务的Spring Bean上,有一个包含大量本地缓存的List字段,这个服务会打印Spring Bean对象到日志中。在引入转转APT之前,一切正常;但引入后,出现了频繁的OOM问题。通过内存分析后发现,问题出在转转APT为Spring Bean自动生成的toString()函数内产生了大量的字符串上。
@Service
public class AppService {/*** 本地缓存*/private List<Object> cache = new ArrayList<>();}@Autowired
private AppService service;log.info("service={}", service);
我们观察到大部分带有本地缓存(或者高内存占用字段)的对象都是Spring的Bean,因此,我们对转转APT进行了修改:即
不再为Spring Bean生成toString()函数。
3.3.2 JDK序列化问题
某个服务的JavaBean使用了原生JDK的序列化/反序列化工具,但是这个JavaBean却没有添加serialVersionUID。
class Person implements Serializable {// 没有定义serialVersionUID// private static final long serialVersionUID = -55721300387280236L;}
Java序列化机制使用long型的serialVersionUID字段来标志类的版本号;序列化对象时,JVM会将serialVersionUID的值写入序列化数据中;反序列化时,JVM会将序列化数据中的serialVersionUID与对应类中的serialVersionUID进行比较,若不同,则抛出InvalidCastException;若版本号相同,则能够进行反序列化。
当一个类没有显式定义serialVersionUID时,JVM会自动根据类的信息计算生成一个默认的serialVersionUID。这样,在类发生变化时,自动生成的serialVersionUID可能会改变,导致无法正确反序列化之前的数据。
引入转转APT后,由于自动生成了toString函数,类信息发生变化,导致serialVersionUID也发生了改变,进而导致反序列化失败。
解决方式是将之前默认生成的serialVersionUID找到,并将其添加到类的源码中。
3.4 弃用方案
还有一种快速落地的方法是,通过在应用程序内部统一拦截日志输出,正则匹配敏感信息,并利用脱敏工具进行脱敏处理。
我们没有使用这种方式的原因是因为:脱敏应尽量避免正则匹配,容易误伤且性能低下。
4 规划
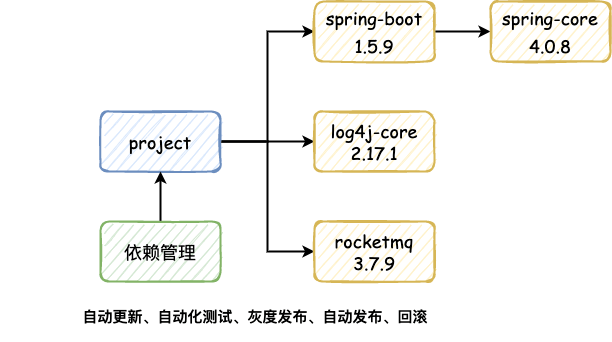
上文提过,服务内依赖的Java Bean来源十分复杂,我们目前只解决了对象本身的脱敏问题。而对于服务依赖的Jar包版本控制,仍需要业务团队梳理依赖关系,并手动修改脱敏后的Jar包版本,这一过程仍需要耗费较多的时间和人力。
考虑到这个问题,是否可以为每个服务提供一个
依赖关系管控系统
?该系统可以对Jar包的版本实现自动更新、自动化测试、灰度发布、自动发布和回滚等一系列功能。对于转转目前的情况来说,我相信这不是一个技术问题,而是一个需要更多时间来完善的TODO List。
5 总结
一个小小的功能日志脱敏,却经历了多个阶段与挑战,从敏感日志的发现到开发脱敏工具类,再到Json脱敏,再到APT脱敏,最终推动业务应用。核心的挑战在于
如何做好推动相关的工作?
我认为,推动相关工作的核心在于有效应对内在和外在的因素。然而,外部因素对推动的阻力常常更大,要成功推动工作,
转变外部阻力为内部动力至关重要
。而对于推动者而言,
换位思考、勇于挑战未知、深入追根究底
的打磨产品会使产品更容易被接受和推广。
关于作者
苑冲,转转架构部存储服务负责人,负责MQ、监控系统、KV存储、时序数据库、Redis、KMS秘钥管理等基础组件。喜欢深入思考问题,对探索新领域和解决问题充满热情。
这篇关于针对大规模服务日志敏感信息的长效治理实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






