本文主要是介绍无痛搭建hadoop集群并运行Wordcount程序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 前置准备
- 查看本地网络信息
- 查看网络连接状态
- 更改网络信息
- 更改主机名
- 对虚拟机进行克隆得到slave1和slave2节点
- 配置slave1和slave2的参数信息
- 建立主机名到ip的映射
- 配置ssh免密登录
- 关闭防火墙与SELinux
- 安装JDK
- 创建新用户
- hadoop环境配置
- 下载与安装
- 环境配置
- 更改配置文件
- 进行传输与连接
- 运行Wordcount程序
前置准备
首先,打开自己的虚拟机,我使用的是centos7的系统,但是不同系统操作差别不大。
查看本地网络信息
进入虚拟网络编辑器
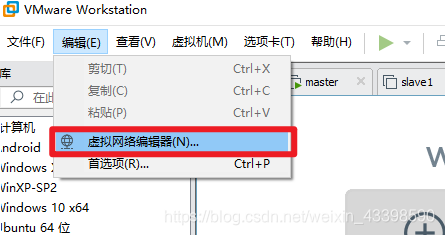
进入NAT设置,查看以下信息
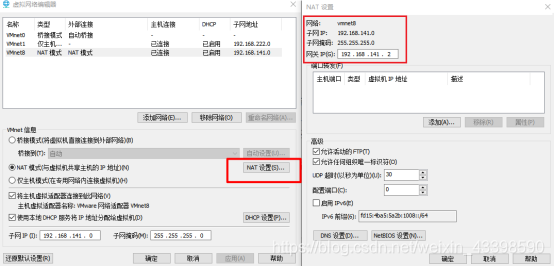
查看网络连接状态
可以看到网络成功连接

输入ifconfig命令发现没有eth0(如果就是eth0可以跳过该步骤),不符合我们的习惯。而且也无法远程ssh连接
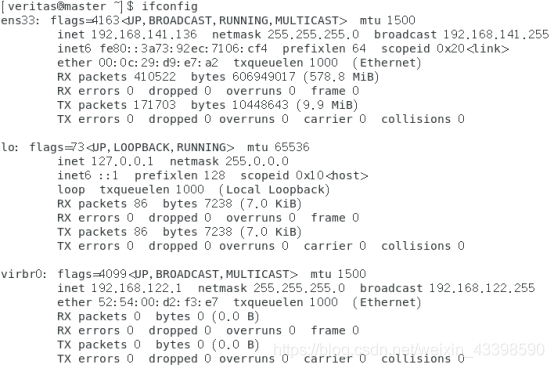
cd /etc/sysconfig/network-scripts/
mv ifcfg-ens33 ifconfig-eth0
更改网络信息
如果有eth0的从这里执行即可
进入管理员模式,因为不进入的话会显示无法保存。
su

vim /etc/sysconfig/network-scripts/ifcfg-eth0
对以下信息进行更改,注意这里的ip和网关需要用你上面自己记录的。

重启网卡,可以看到更改生效

service network restart
如果网卡无法重启
vim /etc/default/grub
加入以下内容
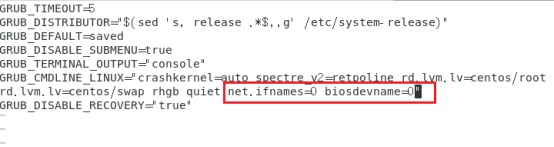
执行以下命令来更改我们的配置
grub2-mkconfig -o /boot/grub2/grub.cfg

如果还不行那么执行
reboot
更改主机名
vim /etc/hostname
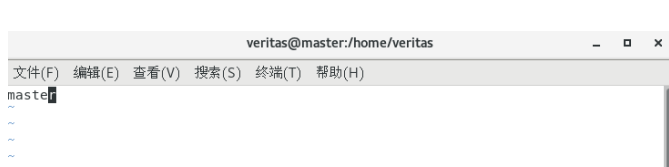
执行reboot命令重启电脑
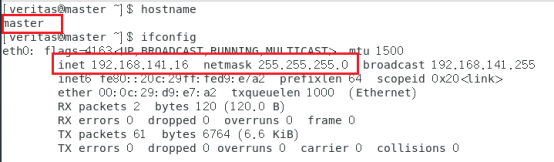
最后检查一遍配置是否正确:
对虚拟机进行克隆得到slave1和slave2节点
关闭虚拟机,进入虚拟机克隆
点击下一步
再次进行下一步
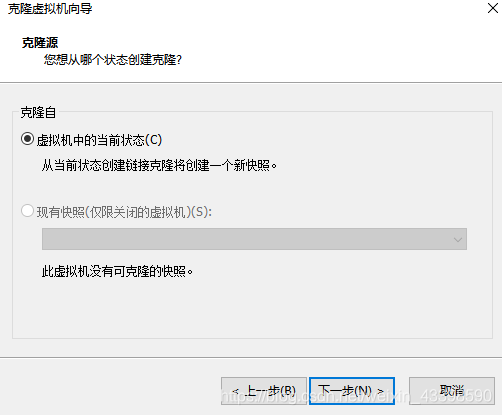
进行完整克隆
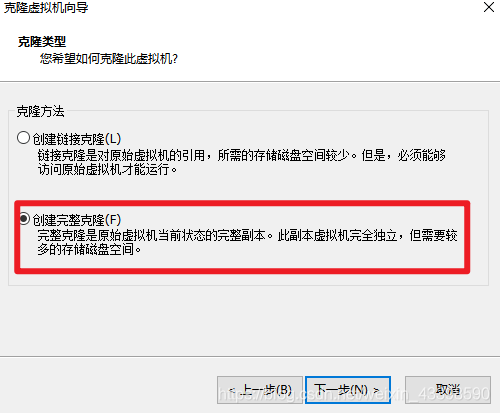
选择安装地点
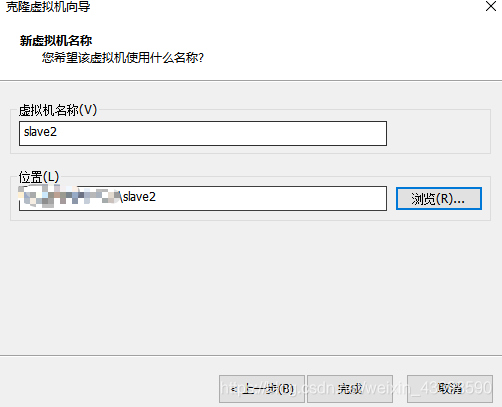
点击完成,然后等待即可。
配置slave1和slave2的参数信息
用上述同样的方法配置slave1和slave2的参数信息,记得ip要选择不一样的,主机名选择slave1和slave2。
vim /etc/sysconfig/network-scripts/ifcfg-eth0

vim /etc/hostname
reboot重启即可,查看配置是否成功


建立主机名到ip的映射
vim /etc/hosts
添加以下内容
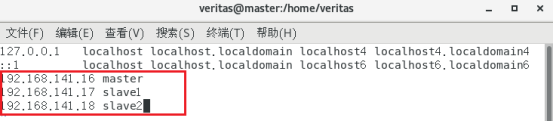
查看是否配置成功
配置ssh免密登录
为了大家的方便我把多了命令合成了一个,运行的过程中一直输入回车即可。
ssh-keygen -t rsa&&cd ~/.ssh/&&cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys&&chmod 600 ~/.ssh/authorized_keys&&cat ~/.ssh/authorized_keys&&ls
结果图如下
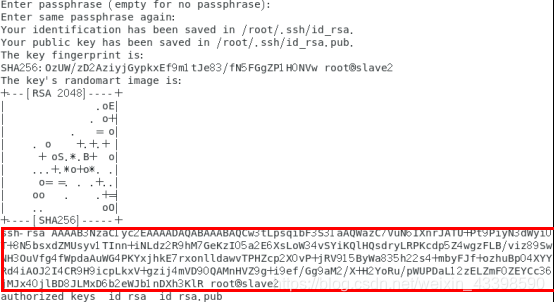
master slave1 slave2都执行这个命令并且把authorized_keys(上图标红的部分),复制到master节点的authorized_keys中。
最终结果如下:
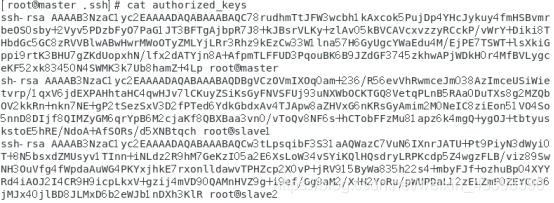
把这些公钥传到子节点上,并测试是否可以免密登录。
scp ~/.ssh/authorized_keys root@slave1:~/.ssh/
scp ~/.ssh/authorized_keys root@slave2:~/.ssh/

关闭防火墙与SELinux
在所有节点执行以下操作:
yum install iptables-servicessystemctl stop firewalld
在master节点执行以下操作:
vim /etc/selinux/config

安装JDK
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
进入放置jdk的文件夹,执行(记得改成你自己压缩包的名字)
mkdir -p /usr/local/java # 创建你要的文件夹
tar -vzxf jdk-8u251-linux-x64.tar.gz -C /usr/local/java/ # 解压到指定位置
查看名字

在文件最下方或者指定文件添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_251
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
执行代码应用环境变量
source /etc/profile
查看是否安装成功:
java -version

创建新用户
adduser hadoop
执行以下操作
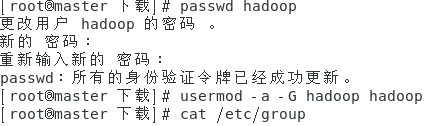
找到以下信息说明配置成功
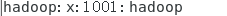
赋予其超级用户权限:
vim /etc/sudoers
改成如下形式

hadoop环境配置
下载与安装
下载网址:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.1.3/hadoop-3.1.3.tar.gz
把hadoop放置到你指定文件夹,进入所在目录,执行以下命令。
tar -vzxf hadoop-3.1.3.tar.gz -C /usr/&&cd /usr&&cd ./hadoop-3.1.3&&mkdir -p dfs/name&&mkdir -p dfs/name&&mkdir temp&&ls

环境配置
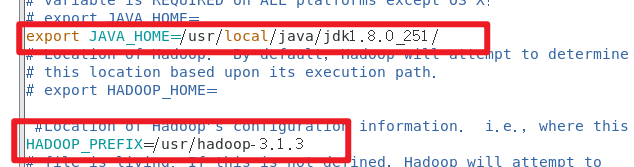
cd ./etc/hadoop/&&vim hadoop-env.sh
加入如下环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_251/
HADOOP_PREFIX=/usr/hadoop-3.1.3
vim yarn-env.sh
加入以下内容:
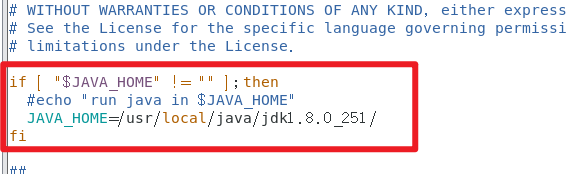
if [ "$JAVA_HOME" != "" ];then#echo "run java in $JAVA_HOME"JAVA_HOME=/usr/local/java/jdk1.8.0_251/
fi
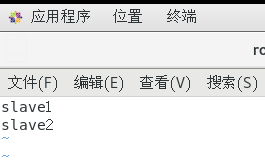
打开当前文件夹下的slaves或者workers
vim workers
删去hostname,添加自己的节点名称。
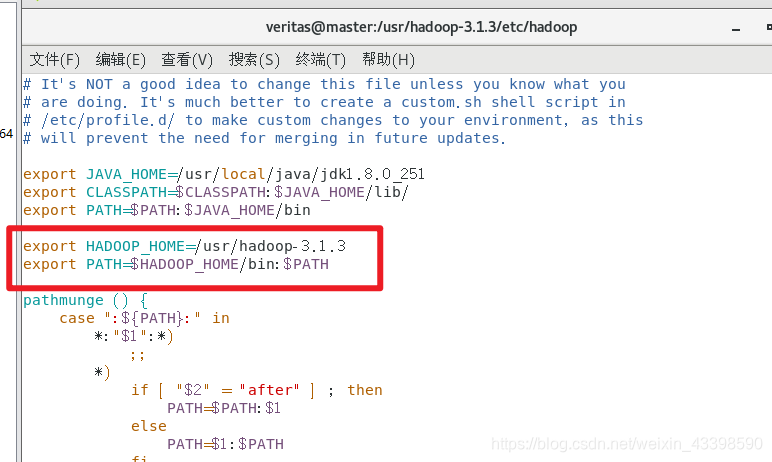
vim /etc/profile
添加以下环境变量
export HADOOP_HOME=/usr/hadoop-3.1.3
export PATH=$HADOOP_HOME/bin:$PATH
更改配置文件
更改sh文件
cd /usr/hadoop-3.1.3/sbin/
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh,stop-yarn.sh顶部也需添加以下:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
更改xml文件
cd /usr/hadoop-3.1.3/etc/hadoop/
vim core-site.xml
添加如下信息
<configuration><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop-3.1.3/tmp</value><description>Abase for other temporary directories.</description></property><property><name>hadoop.proxyuser.hduser.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.hduser.groups</name><value>*</value></property>
</configuration>vim hdfs-site.xml
添加如下信息
<configuration><property><name>dfs.namenode.secondary.http-address</name><value>master:9001</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/hadoop-3.1.3/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/hadoop-3.1.3/dfs/data</value></property><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property>
</configuration>
vim mapred-site.xml
添加如下信息
<configuration><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property>
</configuration>
vim yarn-site.xml
添加如下信息
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.address</name><value>master:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>master:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>master:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>master:8088</value></property>
</configuration>
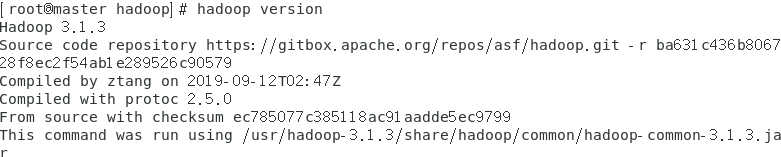
查看是否成功
hadoop version
执行
hadoop classpath

复制打印出的信息,像我下面这样,添加到yarn-site.xml中。
<property><name>yarn.application.classpath</name><value>/usr/hadoop-3.1.3/etc/hadoop:/usr/hadoop-3.1.3/share/hadoop/common/lib/*:/usr/hadoop-3.1.3/share/hadoop/common/*:/usr/hadoop-3.1.3/share/hadoop/hdfs:/usr/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/usr/hadoop-3.1.3/share/hadoop/hdfs/*:/usr/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/usr/hadoop-3.1.3/share/hadoop/mapreduce/*:/usr/hadoop-3.1.3/share/hadoop/yarn:/usr/hadoop-3.1.3/share/hadoop/yarn/lib/*:/usr/hadoop-3.1.3/share/hadoop/yarn/*</value></property>
进行传输与连接
传输给两个子节点
scp -r /usr/hadoop-3.1.3/ root@slave1:/usr/&&scp -r /usr/hadoop-3.1.3/ root@slave2:/usr/
格式化namenode
/usr/hadoop-3.1.3/bin/hdfs namenode -format
开启集群
/usr/hadoop-3.1.3/sbin/stop-all.sh&&/usr/hadoop-3.1.3/sbin/start-dfs.sh&&/usr/hadoop-3.1.3/sbin/start-yarn.sh
查看是否开启成功
hdfs dfsadmin -report
如果live datanodes不为0说明成功了
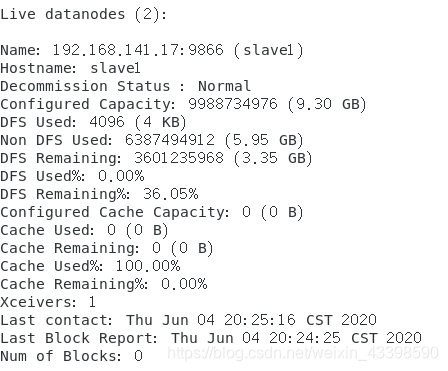
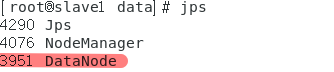
如果不成功的解决方法一
如果在slave节点上执行jps没有这个,那么是由于多次执行/usr/hadoop-3.1.3/bin/hdfs namenode -format代码造成的:
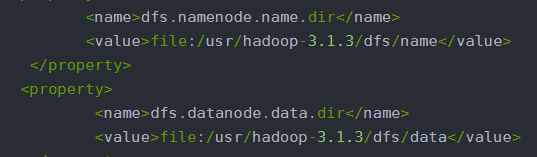
进入hdfs-site.xml中,找到下面两个路径,在master和slave节点上把里面的东西全部删除。
重新执行下面的命令即可
/usr/hadoop-3.1.3/bin/hdfs namenode -format
/usr/hadoop-3.1.3/sbin/stop-all.sh&&/usr/hadoop-3.1.3/sbin/start-dfs.sh&&/usr/hadoop-3.1.3/sbin/start-yarn.sh
hdfs dfsadmin -report
如果不成功的解决方法二
如果有以下的DataNode
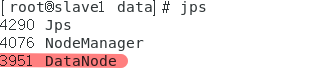
应该是由于没有关闭防火墙导致的:
在所有节点上执行以下命令:
systemctl stop firewalld
重新执行下面的命令即可
/usr/hadoop-3.1.3/sbin/stop-all.sh&&/usr/hadoop-3.1.3/sbin/start-dfs.sh&&/usr/hadoop-3.1.3/sbin/start-yarn.sh
hdfs dfsadmin -report
运行Wordcount程序
随意找几个txt文件放置在指定路径
hadoop dfs -mkdir -p /usr/hadoop-3.1.3/input&&hadoop dfs -put 你放txt的路径/* /usr/hadoop-3.1.3/input&&hadoop dfs -ls /usr/hadoop-3.1.3/input
注意output路径不能事先存在。如果存在,用下面的命令删除:
hadoop dfs -rmr /usr/hadoop-3.1.3/output
运行Wordcount程序:
hadoop jar /usr/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /usr/hadoop-3.1.3/input /usr/hadoop-3.1.3/output
出现以下结果说明运行成功
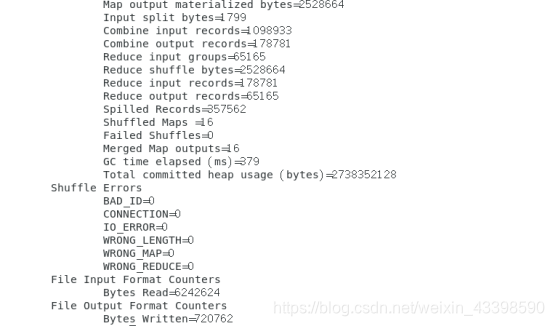
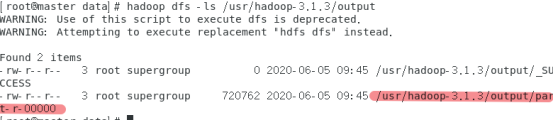
查看output文件夹
hadoop dfs -ls /usr/hadoop-3.1.3/output
打印其中的结果
hadoop dfs -cat /usr/hadoop-3.1.3/output/part-r-00000

这篇关于无痛搭建hadoop集群并运行Wordcount程序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









