本文主要是介绍Opencv3.1.0+opencv_contrib配置及使用SIFT测试,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
因为需要用到一些比较新的跟踪算法,这两天装了opencv3.1并配置了opencv_contrib,并使用了SIFT算法测试是否配置成功。
1.opencv3.1安装与配置
这里不多言,不熟悉的可以参考浅墨的博客:http://blog.csdn.net/poem_qianmo/article/details/19809337
2.opencv_contrib安装与配置
从opencv3以来,一些比较新的功能都挪到了“opencv_contrib”库里。配置这个库需要重新编译opencv,关于此部分可以参考教程:http://blog.csdn.net/linshuhe1/article/details/51221015
关于此教程需要补充两点:A,使用cmake编译的过程中经常会失败,因为国内网络问题ippicv_windows_20151201.zip 文件下载失败导致,可以直接从这里下载:http://download.csdn.net/detail/qjj2857/9495013 B.教程最后配置包含目录、库目录时没有提及添加环境变量,这里也是同样需要的。还有一切配置完成后别忘了重启电脑哟。
3.写个程序测试一下配置是否成功吧
opencv3.1中SIFT匹配是在opencv_contrib库中的,这里我们就用它来做一个简单的测试。
参考:
1. cv::xfeatures2d::SIFT Class Reference:http://docs.opencv.org/3.1.0/d5/d3c/classcv_1_1xfeatures2d_1_1SIFT.html#gsc.tab=0
2. OpenCV3.1 xfeatures2d::SIFT 使用:http://blog.csdn.net/lijiang1991/article/details/50855279
程序:
#include <iostream>
#include <opencv2/opencv.hpp> //头文件
#include <opencv2/xfeatures2d.hpp>
using namespace cv; //包含cv命名空间
using namespace std;int main()
{//Create SIFT class pointerPtr<Feature2D> f2d = xfeatures2d::SIFT::create();//读入图片Mat img_1 = imread("1.jpg");Mat img_2 = imread("2.jpg");//Detect the keypointsvector<KeyPoint> keypoints_1, keypoints_2;f2d->detect(img_1, keypoints_1);f2d->detect(img_2, keypoints_2);//Calculate descriptors (feature vectors)Mat descriptors_1, descriptors_2;f2d->compute(img_1, keypoints_1, descriptors_1);f2d->compute(img_2, keypoints_2, descriptors_2); //Matching descriptor vector using BFMatcherBFMatcher matcher;vector<DMatch> matches;matcher.match(descriptors_1, descriptors_2, matches);//绘制匹配出的关键点Mat img_matches;drawMatches(img_1, keypoints_1, img_2, keypoints_2, matches, img_matches);imshow("【match图】", img_matches);//等待任意按键按下waitKey(0);
}原始图片:


匹配结果:
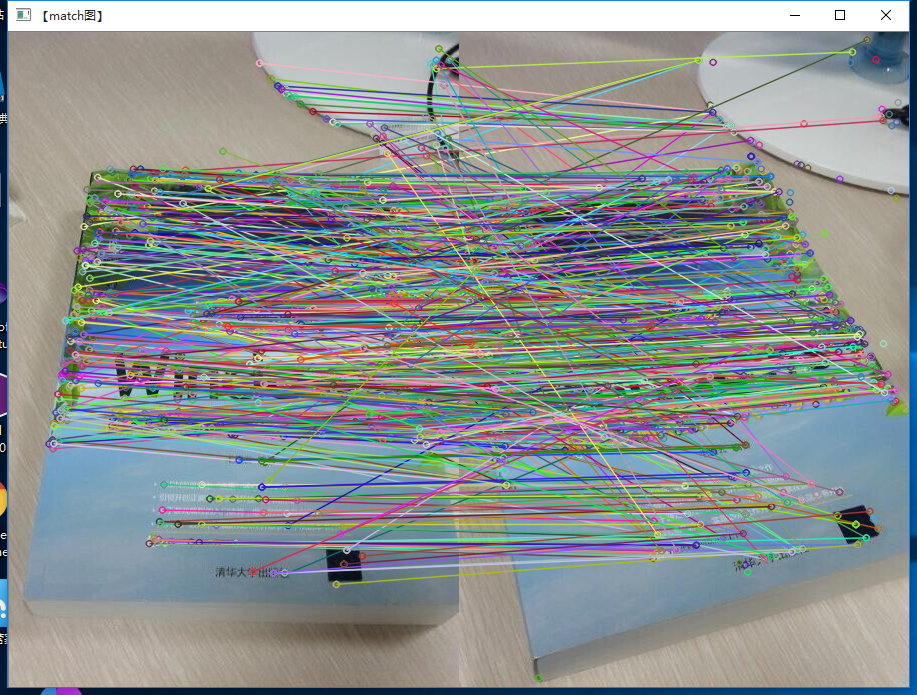
———————————-2016/8/12———————————
1.关于Ubuntu下opencv3.1及opencv_contrib的安装与配置可参考:
官网:Installation in Linux
http://www.cnblogs.com/asmer-stone/p/5089764.html
上博文中有两点需要注意:
A.按上文参考所述,第3步build文件夹需建在~/opencv/opencv文件夹中;且cmake时按照作者示例OPENCV_EXTRA_MODULES_PATH=~/opencv/opencv_contrib/modules ,注意”<>”需要去掉;末尾的.. 表示opencv源码在上一级目录中。当然如果你了解cmake的使用方法cmake [optional] <opencv source directory>, 可以任意设置文件夹目录。
B.与在windows下相同,cmake时会因为“ippicv_linux_20151201.tgz 无法下载”而导致失败。我们可以从http://download.csdn.net/download/lx928525166/9479919下载,并放入相应文件夹中。
2. 好,现在假设你已经安装配置好了。由于在windows下我们习惯了用一个IDE来编程,这里在Ubuntu下我选择使用eclipse来作为编程环境,下边简单说一下怎么在eclipse中配置opencv。
首先参考官网: http://docs.opencv.org/3.1.0/d7/d16/tutorial_linux_eclipse.html 你就应该能配置的差不多了,或者其他类似的吧网上一大堆。
但是中间可能会出现一些小问题,我个人配置的时候出现了两个小问题:
A. 错误 undefined reference to symbol ‘_ZN2cv6imreadERKNS_6StringEi’ ,参考:http://answers.opencv.org/question/46755/first-example-code-error/
B. 错误 error while loading shared libraries: libopencv_core.so.3.0: cannot open shared object file: No such file or directory ,参考:http://stackoverflow.com/questions/27907343/error-while-loading-shared-libraries-libopencv-core-so-3-0
3. 所有配置均完成后,在上述windows下的代码可以在这里直接运行。见下图:
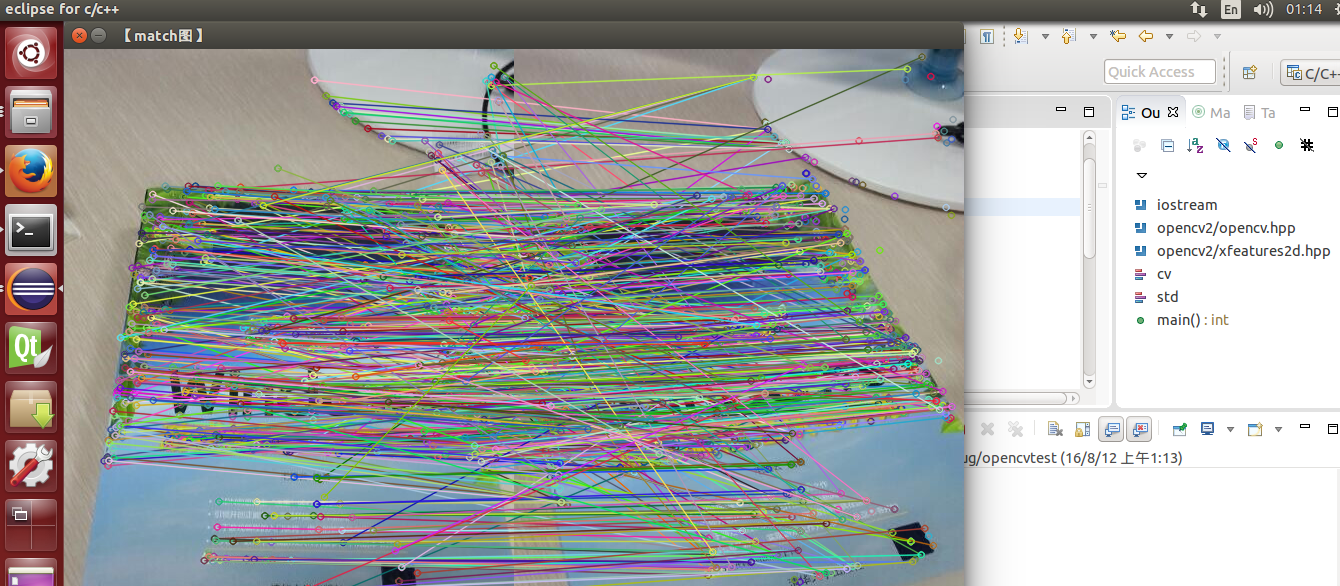
4.关于在ubuntu下运行其他samples程序。这里以cpp为例,直接找到opencv/samples/cpp/example_cmake,这里有一个示例已经提供了Makefile文件,make一下即可生成可执行文件。其他cpp示例文件类似。
这篇关于Opencv3.1.0+opencv_contrib配置及使用SIFT测试的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




